

Update #51: ChatGPT-hallucinated Briefs in Court and Voyager
Lawyers cite fake cases invented by ChatGPT in court hearings and researchers release a GPT-4-powered agent capable of planning and executing diverse tasks in Minecraft.



Welcome to the 51st update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter :) You’ll need to view this post on Substack to see the full newsletter!
Want to write with us? Send a pitch using this form.
News Highlight: ChatGPT-hallucinated briefs submitted to court by attorneys'

Summary
Following the breakout popularity of Open AI’s ChatGPT, we have seen a proliferation of AI powered chatbots, photo apps, and content generators. When put to the test by multiple lawyers, those lawyers began citing fake cases invented by ChatGPT in courts around the United States. This has even prompted one Texas judge to institute “mandatory certification regarding generative artificial intelligence” requiring lawyers to attest all text generated by AI to be checked by humans for accuracy.
Background
As reported by the New York Times, a lawyer of the firm Levidow, Levidow & Oberman “submitted a 10-page brief that cited more than a half a dozen relevant court decisions.” When those decisions could not be located by the opposing counsel, the judge ordered the firm to “provide copies of the opinions referred to in their brief”. They submitted eight cases, listing the court, judges, docket numbers and dates and suggested in writing that at least some were “written by a three-judge panel of the 11th circuit.” However, neither the judge nor the opposing counsel could find that opinion, or the others, on any court dockets or legal databases.
As the lead attorney would later attest, he used ChatGPT for his legal research. However, when he started his journey he was “unaware of the possibility that the content [generated by ChatGPT] could be false.” Now he “greatly regrets” relying on ChatGPT “and will never do so in the future without absolute verification of its authenticity.” This incident has not happened in isolation, with online reports circulating of multiple US attorneys submitting briefs generated by ChatGPT which cited non-existent cases.
Why does it matter?
In the United States, the right to a fair trial and counsel is a core pillar of the Sixth Amendment of the Constitution. When lawyers outsource their responsibilities to fallible text-generation systems that often hallucinate, they are derelict in their duty to both client and country. While AI assisted legal tools seem like a panacea for helping attorneys manage large caseloads, prepare briefs faster, and “increase access to legal services” they are causing chaos for courts and their clients.
Texas District Judge Branlty Starr, either in anticipation of or reaction to how generative AI will impact his court, is now requiring that all those before his court attest in writing that “language drafted by generative artificial intelligence will be checked for accuracy, using print reporters or traditional legal databases, by a human being.” As these tools proliferate in use, we should expect to hear more and more about AI generating briefs containing falsehoods and hallucinations. Fortunately, while the stakes so far have been relatively low (financial compensation for minor injuries), there is no guarantee that this will continue. It remains to be seen how other judges and courts will accommodate AI-generated briefs as well as how those briefs which contain falsehoods and hallucinations will influence people's pursuits of justice.
Editor Comments
Justin : Perhaps if the lead attorney was a subscriber to our Substack / newsletter he would have known all about large language models tendencies to make stuff up before this debacle
Research Highlight: Voyager: Minecraft In Context

Summary
A team led by NVIDIA researchers recently released Voyager, a GPT-4 driven agent capable of planning and executing diverse tasks in Minecraft. This is achieved solely via prompting an LLM, without any further training needed. To accomplish this, the project develops three major components for generating diverse tasks, maintaining and using learned skills, and iteratively prompting an LLM to generate code for a given task.
Overview
Transformer-based Large Language Models (LLMs) are known to be very capable of in-context learning — learning based on a content in a prompt, without any parameter updates to the model. These capabilities have been very widely studied recently, and we have covered them in Gradient Updates #31, #40, #43, and an article by our very own Daniel Bashir.

Researchers from NVIDIA, Caltech, UT Austin, Stanford, and ASU have recently developed Voyager — a system for LLMs to in-context learn to control an agent in Minecraft that is capable of autonomously exploring the world, acquiring knowledge, and developing skills. Voyager works solely through prompting GPT-4, without needing to update model parameters.
Voyager can consistently solve tasks in a new Minecraft world, such as creating diamond tools. When compared with the baselines ReAct, Reflexion, and AutoGPT that are based on LLM prompting, Voyager explores more of the map, more consistently reaches difficult milestones, and requires fewer prompting iterations to reach a goal. The authors also show that Voyager adapts to feedback from humans, for instance through critiquing previous actions, or giving Voyager subtasks to solve on the way to a larger task.
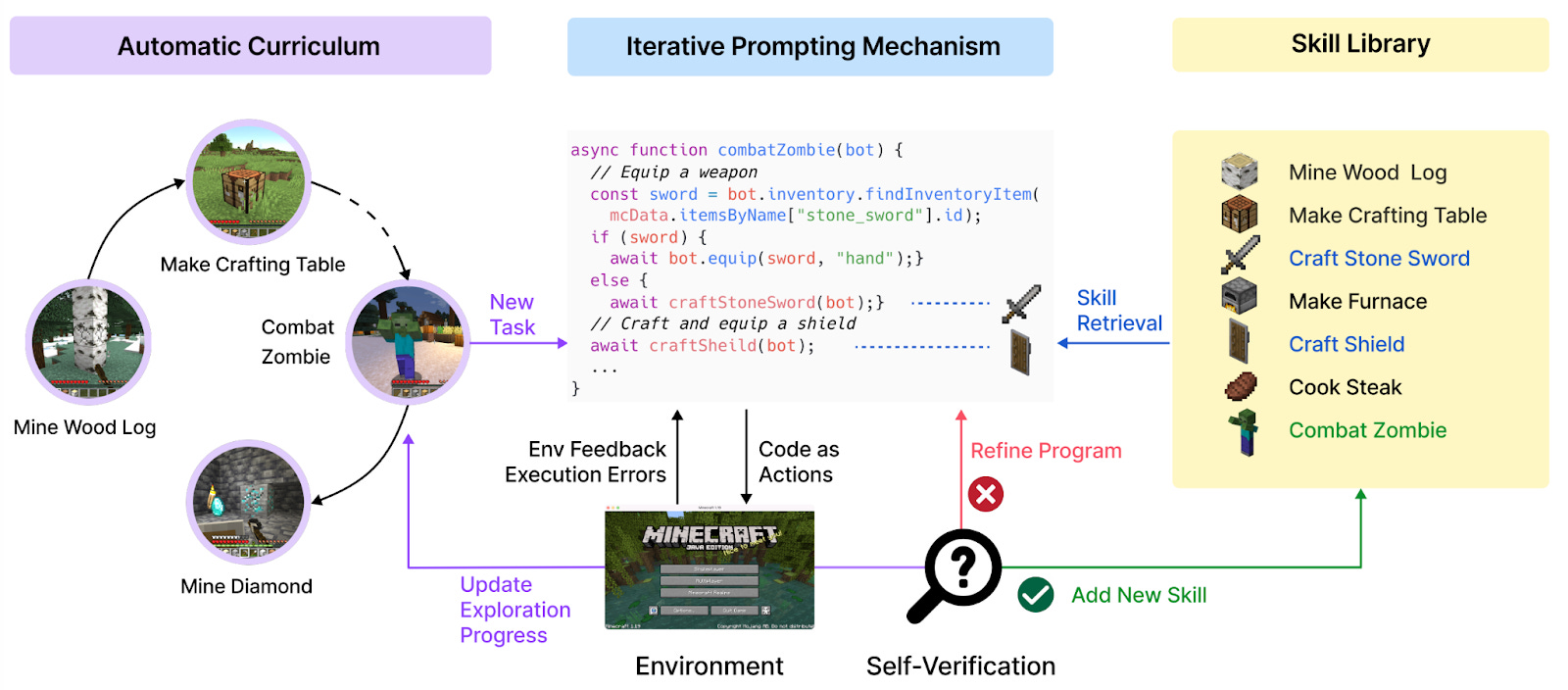
The Voyager model has three key components:
Automatic curriculum. An LLM is used to generate new tasks for the agent to complete. The prompt encourages the agent to “discover as many diverse things as possible” and to make sure the next task is not “too hard since [the agent] may not have the necessary resources or have learned enough skills to complete it yet.”
Skill library. The agent maintains a bank of skills that it has successfully used before. These skills are represented as executable code in the MineFlayer Javascript API. Some examples of learned skill libraries are available in the Github repo. Each skill is indexed via an embedding of its description, and later a to-be-used skill is retrieved via comparison to an embedding of the current task and environment feedback.
Iterative prompting. Voyager repeatedly prompts the LLM to generate code to complete a given task. In between repetitions, it receives feedback from the environment (e.g. an attempt to make a stone pickaxe may fail because the agent does not have enough stone) and from the program interpreter, which catches e.g. syntax errors in generated code. The authors also utilize another instance of an LLM to self-verify that a generated program completes a given task.
Why does it matter?
This work pushes the limits of in-context learning in LLMs, in a domain that is very different from the training data and standard applications of LLMs. Voyager and related future systems based on in-context learning are powerful AI systems that do not require expensive and more complex finetuning or other modifications to the underlying foundation model. As noted by Andrej Karpathy, the “source code” is in large part located in .txt files in a prompts/ folder, and are written in natural language.
Future improvements could lead to even better LLM-based embodied learning agents. For instance, models with longer context length could include even more information for planning, memory, and reasoning. Several works have studied integrating retrieval with LLMs, which is crucial for Voyager’s skill library. Further, the authors note that coding ability of the underlying LLM is very important for Voyager, so the use of GPT-4 is crucial (as opposed to GPT 3.5 or open-source LLMs). Future improvements in coding ability of LLMs would lead to even better agents.
Author Q&A
We spoke with lead author Guanzhi Wang for more information.
Q: The paper says that “novel techniques for finetuning open-source LLMs will overcome these limitations…”. How do you envision finetuning being used in future systems for embodied agent learning?
A: Reasoning and coding abilities are essential for LLMs to work well for embodied agent learning. Techniques such as process supervision that provides feedback for each reasoning step could enhance the reasoning capability. Furthermore, finetuning LLMs on extensive code corpora that involve planning logic would be beneficial for generating sophisticated policies.
Q: Minecraft is an extremely popular game with a lot of internet content on it. Do you know the extent to which Voyager’s success is based on GPT-4’s knowledge of Minecraft, and whether a similar approach would be limited in non-Minecraft settings?
A: Voyager’s success can be attributed to GPT-4's comprehensive understanding of Minecraft’s game mechanics, gained from its pre-training on internet data. This knowledge is critical for planning and reasoning within the Minecraft environment. In non-Minecraft settings, it is feasible to adopt a similar approach by leveraging external knowledge bases, such as instructional materials or subject-specific guides, to supplement GPT-4's capabilities and enhance its performance.
Q: Have you noticed any similarities or differences between the ways in which Voyager and humans play Minecraft? How about between Voyager and other AI agents?
A: Both Voyager and expert human players exhibit proficiency in planning when playing Minecraft. Voyager typically provides sophisticated plans that are derived from the Minecraft knowledge encapsulated within GPT-4. In contrast to other AI agents that operate on short-horizon actions and generate task-specific blackbox policies, Voyager approaches the game with an open-ended objective to discover as many diverse things as possible, and creates interpretable and reusable policies in the form of executable code. These features make Voyager obtain more novel items, travel longer distances, and unlock key tech tree milestones much faster than other AI agents.
New from the Gradient
Riley Goodside: The Art and Craft of Prompt Engineering

Talia Ringer: Formal Verification and Deep Learning

Other Things That Caught Our Eyes
News
US Intelligence Building System to Track Mass Movement of People Around the World "The Pentagon’s intelligence branch is developing new tech to help it track the mass movement of people around the globe and flag ‘anomalies.’"
AI Is Not an Arms Race “The window of what AI can’t do seems to be contracting week by week. Machines can now write elegant prose and useful code, ace exams, conjure exquisite art, and predict how proteins will fold. Experts are scared.”
Deepfaking it: America's 2024 election collides with AI boom “Joe Biden finally lets the mask slip, unleashing a cruel rant at a transgender person. "You will never be a real woman," the president snarls. Welcome to America's 2024 presidential race, where reality is up for grabs.”
China warns of ‘complicated and challenging circumstances’ posed by AI risk “China is warning about the threat of artificial intelligence (AI) and has called for increased security measures.”
US, Europe Working on Voluntary AI Code of Conduct as Calls Grow for Regulation “The United States and Europe are drawing up a voluntary code of conduct for artificial intelligence, with a draft expected in weeks.”
A majority of Americans have heard of ChatGPT, but few have tried it themselves “About six-in-ten U.S. adults (58%) are familiar with ChatGPT, though relatively few have tried it themselves, according to a Pew Research Center survey conducted in March. Among those who have tried ChatGPT, a majority report it has been at least somewhat useful.”
Italy plans state-backed fund to promote AI startups “Italy's government plans to set up an investment fund backed by state lender Cassa Depositi e Prestiti (CDP) to promote startups investing in Artificial Intelligence (AI), cabinet undersecretary Alessio Butti said on Tuesday.”
Baidu’s $145M AI fund signals China’s push for AI self-reliance “The U.S.-China decoupling is giving rise to a divided tech landscape between the two major economies, shaping the development of the red-hot area of generative AI, which turns text into various forms of content like prose, images, and videos. China, in order to reduce dependence on the U.S.”
While parents worry, teens are bullying Snapchat AI “In a more lighthearted video, a user convinced the chatbot that the moon is actually a triangle. Despite initial protest from the chatbot, which insisted on maintaining “respect and boundaries,” one user convinced it to refer to them with the kinky nickname ‘Senpapi.’”
Google says Gmail on your phone just got a lot faster thanks to A.I. “On Friday, the company announced an AI update for Gmail: Over the next 15 days, end users will begin to see "top results" when they search their inboxes, featured above the "all results" section.”
AI Is an Insult Now “People are already tired of machine-generated text, and they’re not afraid to say it. If you want to really hurt someone’s feelings in the year 2023, just call them an AI.”
Papers
Daniel: The preprint “Prompt-based method may underestimate large language models’ linguistic generalizations” is very interesting to me because it speaks to how our natural ways of working out LM capabilities might fail to capture what is actually going on in their representational structure. I think this is really important because when we want to ask questions like “what linguistic generalizations to LLMs capture?”, we have to interrogate LLMs with particular scientific tools equipped to help us assess that question. Hu and Levy point out that without access to LLM probability distributions (e.g., given a context what is the probability of a word), LLM evaluation begins to rely on metalinguistic prompting (writing a sentence and asking the model about it). Their experiments show that negative results relying on these metalinguistic prompts cannot serve as conclusive evidence that LLMs lacks a particular linguistic competency.
Derek: Lexinvariant Language Models by Huang et al. is a super interesting work that explores the capabilities of language models without fixed token embeddings. One instantiation of such a language model studied in their paper is a Transformer with randomly sampled Gaussian embeddings for each token, where repetitions of a token in the same sequence will have a consistent embedding, but instances of that same token in different sequences will have generally different embeddings. With a finite set of tokens and a growing context length, lexinvariant language models are empirically and theoretically shown to be capable of approaching the true language distribution. Interestingly, in the context of the symbol grounding problem, the symbols in lexinvariant language models are even less physically grounded than in standard language models, since their meaning is completely derived from the context.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!