

Gradient Update #31: Autonomous Driving in 2022 and Transformers Learning In-Context
In which we discuss the state of autonomous driving regulation, technology, and financing, as well as in-context learning in transformers.

Welcome to the 31st update from the Gradient! If you were referred by a friend, subscribe and follow us on Twitter!
News Highlight: Autonomous Driving In 2022: Setbacks and Wins in Regulation, Technology and Financing

Summary
The development of self-driving vehicles is one the most closely watched spaces in modern AI. However, before autonomous vehicles can become a cohesive part of our society, they must overcome various technological and regulatory challenges. Many companies have now seen successes in testing driverless vehicles on real-world roads, but these advancements are accompanied by various setbacks as organizations discover failure modes in their systems and battle against the current economic slowdown.
Background
While organizations in many countries are developing autonomous vehicles (AVs), the United States and China lead the pack in their synchronized advancement of both technology and regulation. In the United States, California witnesses the highest activity in the AV space, having given permits to 58 companies in three tiers, which dictate various terms of how autonomous cars can be tested by a company. Of these, 7 are allowed to conduct fully driverless testing, and only 3 companies - Waymo, Cruise, and Nuro - are authorized to deploy their vehicles on public roads.
On August 8th, Baidu became the first company in China to receive a permit to operate robot-taxis in a fully driverless manner, even without a safety supervisor. Earlier this year, both Baidu and Pony.ai had received permits to operate driver-free robot taxis in Beijing, but they still required a secondary supervisor to be present in the passenger seat. All of these regulatory advances pave a strong path forward for the development of AVs as they continue to be tested in real-world environments.
However, as testing begins to ramp up on public roads, many organizations unearth failure cases for their tech in the real world. For instance, Cruise.ai, one of the biggest players in the American AV space, lost contact with nearly 60 vehicles in San Francisco over a 90 minute period as the cars lost connection with a Cruise server and froze on the street. According to a Wired report, a driver described being stuck in a “robo-taxi sandwich” with his car surrounded by 4 Cruise vehicles, none of which moved for at least 15 minutes.
While some companies are working to make their technological stack robust, others face operational challenges. Pittsburgh-based Aurora recently had to delay the launch of their self-driving trucking product by one year, citing delays in their supply chain. On the other hand, Tesla has recently come under fire after being accused by the California DMV of misleading customers about their vehicles’ self-driving capabilities. The DMV asserts that Tesla’s “Autopilot” and “Fully Self Driving (FSD)” marketing labels indicate a level of autonomy that Tesla cars do not actually exhibit. The company has 15 days to respond, or risks losing its permit in California that allows it to operate as a vehicle manufacturer and dealer.
Why does it matter?
While autonomous vehicles have come a long way since their conception in the previous century, there are many obstacles their developers must overcome to deploy AVs at scale. Given the fact that the AV industry’s end goal is to deploy self-driving vehicles in the public domain, it is essential that technology and business progress within the bounds of regulation and oversight. When AVs fail on public roads due to unforeseen circumstances, they pose a security risk to the people around them. While failure modes are expected when testing such a novel technology in the real world, it is imperative that AVs are introduced slowly into the public domain with rapid iteration on the product. Lastly, it is important to recognize the risks of false advertising for such a product; ill-informed users with over-optimistic perceptions of their car’s autonomous driving features can cause harm to themselves, and those driving around them. In order to prevent AVs from “becoming that which they were supposed to defeat”, it is important that we collectively tame our excitement and take a steady, incremental approach towards the democratization of this technology.
Editor Comments
Daniel: As potentially helpful to the world as I think self-driving technology (done right) can be, I can’t help but become less and less bullish on it over time. I do think we’re eventually going to get past some of the largest roadblocks to using the technology and be able to adopt it in at least limited cases, but many non-technical aspects of the AV scene will need to see developments as well.
Paper Highlight: What Can Transformers Learn In-Context? A Case Study of Simple Function Classes

Summary
Language models have been observed to have some capacity for in-context learning, in which the language model is given a prompt consisting of input/output pairs (or question/answer pairs), and then the model gives the correct output for a new input. This new work by Stanford researchers gives a rigorous formulation and thorough investigation of in-context learning for language models that are trained from scratch. The work shows that Transformers can in-context learn linear functions and other more complex function classes very well with varying numbers of in-context examples and under various types of distribution shift.
Overview
Large language models have been shown to be capable of in-context learning, meaning that they can give accurate outputs for a new input, after being given demonstrative input-output pairs in a prompt. For instance, large language models like GPT-3 are capable of taking in a few examples of addition in a prompt (3+7=10, 2+9=11, 10+3=13, 3+4=) and then correctly answering 3+4=7. Or, they can take in example translations (wall -> mur, bread -> pain, hello ->) and translate hello -> bonjour. However, as the training datasets for these large models consist of hundreds of billions of tokens, it is unclear whether the models can in-context learn to do new tasks, versus simply being able to memorize solutions to tasks encountered during training.
This new work formalizes in-context learning, and studies the ability of Transformers to in-context learn in controlled settings. In-context learning is defined as follows: assume inputs are drawn from a data distribution, and output functions (learning targets) are drawn from a distribution of functions (e.g. linear functions). For one task, we first sample a function that we want to learn, and then sample a prompt consisting of multiple in-context examples by pairing sampled data points with the output of that function evaluated at the data points. Finally, we test our model by giving it this prompt, and determining whether its output on a query data point is close to the function value evaluated at that query.
Within this framework, the authors train a Transformer to learn linear functions. That is, given a sampled coefficient vector defining a linear function, and several input-output pairs of random data points evaluated under this linear function, we want our Transformer to correctly evaluate the linear function on new data points. They train the Transformer from scratch (that is, they do not use a pretrained language model) by giving the aforementioned prompts and using a squared loss to penalize deviations of the Transformer output from the actual target function. Under the data distribution and function distributions that are considered in the paper, the optimal algorithm is a simple linear regression.
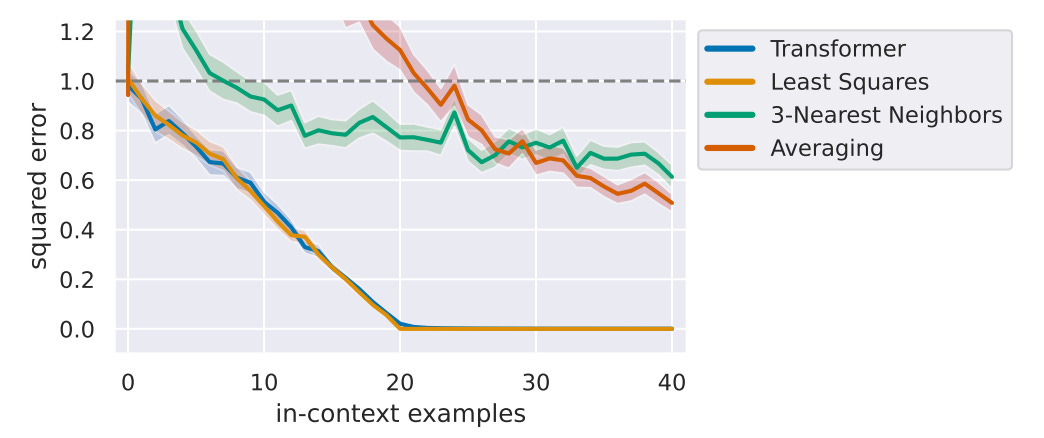
On linear target functions, the authors find that a Transformer is able to in-context learn with error essentially equal to the optimal linear regression’s. This strong performance from the Transformer holds in several scenarios, including when the number of in-context examples is limited, when there is a distribution shift between train and test prompt inputs, and when there is a distribution shift between in-context examples and the query data point. Further, the authors show that this performance is not due to memorization of training examples — a baseline that memorizes training functions does poorly, and a Transformer also does well when further limiting the amount of training data.
Moreover, Transformers are able to in-context learn more complicated target function classes, such as when target functions are given by two-layer random ReLU networks or depth 4 decision trees. Notably, optimal algorithms for learning decision trees are unknown, and the Transformer outperforms all of the tested heuristics and baselines for this task. The authors also find that increasing the size of the Transformer generally increases performance of in-context learning, and also increases robustness to distribution shifts.

Why does it matter?
In-context learning is a powerful capability of large language models, which can be leveraged by anyone who can prompt a language model. While the capabilities of pretrained language models have been widely studied, their massive, often private training sets cast doubt on which of their capabilities are simply memorization, and which are indicative of generalization and other useful traits.
This work has shown that Transformers empirically excel at in-context learning in a controlled environment on rigorously defined problems. In the linear regression target tasks, where the optimal learning algorithm is known, Transformers perform nearly optimally and are robust across many settings. Further, since Transformers do significantly better than existing baselines on in-context learning decision tree outputs, the authors speculate that it may be possible to reverse-engineer such a Transformer to discover better decision tree fitting algorithms. Future work could also use the framework considered in this paper to compare in-context learning abilities of different neural models, or to develop models that are even better at in-context learning.
Editor Comments
Derek: I really like how this paper develops a rigorous framework for testing in-context learning, and clearly explains it. The empirical results in this paper, along with all of the ablations, are pretty convincing to me. Although there are no theoretical results on in-context learning ability in this paper, it seems as though this mathematical formulation can be theoretically analyzed in future work.
New from the Gradient
Laura Weidinger: Ethical Risks, Harms of LLMs, Alignment

Other Things That Caught Our Eyes
News
SenseTime Releases AI Chinese Chess Robot “SenseTime, an artificial intelligence software company, held a new product launch event and launched its first household consumer artificial intelligence product – “SenseRobot”, an AI Chinese chess-playing robot.”
AI-generated digital art spurs debate about news illustrations “Artificial intelligence has seeped into many creative trades — from urban planning to translations to painting. The latest: visualizations in journalism. Why it matters: Computers are getting better at doing what humans can do, including creating art from scratch.”
Meta’s AI chatbot says Trump will always be president and repeats anti-Semitic conspiracies “Only days after being launched to the public, Meta Platforms Inc’s new AI chatbot has been claiming that Donald Trump won the 2020 US presidential election, and repeating anti-Semitic conspiracy theories.”
Papers
Social Simulacra: Creating Populated Prototypes for Social Computing Systems Can a designer understand how a social system might behave when populated, and make adjustments to the design before the system falls prey to such challenges? We introduce social simulacra, a prototyping technique that generates a breadth of realistic social interactions that may emerge when a social computing system is populated… We demonstrate that social simulacra shift the behaviors that they generate appropriately in response to design changes, and that they enable exploration of "what if?" scenarios where community members or moderators intervene. To power social simulacra, we contribute techniques for prompting a large language model to generate thousands of distinct community members and their social interactions with each other; these techniques are enabled by the observation that large language models' training data already includes a wide variety of positive and negative behavior on social media platforms.
Frozen CLIP Models are Efficient Video Learners Video recognition has been dominated by the end-to-end learning paradigm -- first initializing a video recognition model with weights of a pretrained image model and then conducting end-to-end training on videos. This enables the video network to benefit from the pretrained image model. However, this requires substantial computation and memory resources for finetuning on videos and the alternative of directly using pretrained image features without finetuning the image backbone leads to subpar results… we present Efficient Video Learning (EVL) -- an efficient framework for directly training high-quality video recognition models with frozen CLIP features. Specifically, we employ a lightweight Transformer decoder and learn a query token to dynamically collect frame-level spatial features from the CLIP image encoder. Furthermore, we adopt a local temporal module in each decoder layer to discover temporal clues from adjacent frames and their attention maps. We show that despite being efficient to train with a frozen backbone, our models learn high quality video representations on a variety of video recognition datasets…
Semi-supervised Vision Transformers at Scale We study semi-supervised learning (SSL) for vision transformers (ViT), an under-explored topic despite the wide adoption of the ViT architectures to different tasks. To tackle this problem, we propose a new SSL pipeline, consisting of first un/self-supervised pre-training, followed by supervised fine-tuning, and finally semi-supervised fine-tuning… Our proposed method, dubbed Semi-ViT, achieves comparable or better performance than the CNN counterparts in the semi-supervised classification setting. Semi-ViT also enjoys the scalability benefits of ViTs that can be readily scaled up to large-size models with increasing accuracies. For example, Semi-ViT-Huge achieves an impressive 80% top-1 accuracy on ImageNet using only 1% labels, which is comparable with Inception-v4 using 100% ImageNet labels.
Tweets
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at gradientpub@gmail.com and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! If you enjoyed this piece, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!