

Update #43: Propaganda Deepfakes and Transformers get Loopy
The first known use of deepfakes for spreading state-aligned propaganda and transformers embedded in loops can emulate Turing complete computers.



Welcome to the 43rd update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter :) You’ll need to view this post on Substack to see the full newsletter!
Want to write with us? Send a pitch using this form.
News Highlight: Deepfakes Used for State-Aligned Propaganda For The First Time

Summary
Graphika, a research organization that studies disinformation, recently discovered the first known use of deepfakes for spreading state-aligned propaganda. Multiple videos were released on Meta’s platforms by bot accounts and featured American news anchors of “Wolf News” siding with the Chinese Communist Party (CCP) and criticizing the United States. At least one of the videos has since been taken down from Facebook for policy violations and the company whose software was used to generate the videos has also banned the accounts responsible for the propaganda videos.
Background
Deepfakes are synthetic media in which a person in an existing image or video is replaced with someone else's likeness. Models that generate deepfakes are specifically trained on datasets of human faces and speech to generate realistic videos of an individual saying things they have never uttered. These generative models have existed for many years now and were used by Kendrick Lamar in a music video to morph into Kanye, by an Indian political party to communicate with voters in different languages, and by a Chinese company to make Trump speak mandarin. While deepfakes have been used for many controversial purposes in recent years, they had not been used to spread propaganda for a specific government until this incident.
Social media analytics firm Graphika recently discovered two deepfake videos that seem to show anchors of an American news channel promoting the interests of the CCP and undercutting the United States. For instance, one video featured a reporter criticizing mass shootings in America, and another showed an anchor praising the CCP’s foreign policy and saying that their initiatives would bring “great vitality to world development”. While the videos themselves didn’t garner many views before they were removed, Graphika says that the videos themselves are a bigger concern as they are indicative of how the use of politically motivated deepfakes could spread rampant misinformation in the future. It should be noted that while the deepfakes’ content is certainly state-aligned, there is currently no evidence that they were state sponsored.
Graphika was able to trace the videos back to Synthesia, a London-based startup that offers a deepfake-generation platform, as the videos used two avatars available on Synthesia’s online platform. Synthesia has now deactivated the responsible accounts, citing a violation of their terms of use which prevent the technology from being used for political purposes.
Why does it matter?
As generative models continue to receive more and more attention, cases like these illuminate the inevitable misuse of the technology. As we make it easier to generate synthetic media, the barriers to generating harmful, incendiary or propagandist content will also lower.
This case also demonstrates that when prompt-based models are deployed at scale, it is difficult for companies to detect which prompts violate their terms of use. Victor Riparbelli, Synthesia’s co-founder and chief executive, said that while Synthesia prevents users from generating videos with illicit content, it cannot detect implicit hate speech or malicious intent in a free-flowing sentence. While government regulations could ameliorate the situation, creating reasonable regulations is not trivial either as tighter rules could unintentionally restrict a user’s creative and artistic expression. While the task at hand is nuanced, there is a strong need for the government and industry to collaboratively combat the issue so that more harmful cases of misinformation can in the future be prevented, and not just addressed.
Research Highlight: Looped Transformers as Programmable Computers

Summary
A recent paper from University of Wisconsin-Madison and Princeton demonstrates the expressive power of Transformers embedded in simple loops. They show that constant depth Looped Transformers are highly expressive and can be programmed to emulate a particular Turing Complete computer, fundamental linear algebra operations, and stochastic gradient descent on in-context data.
Overview
Transformers are — needless to say — one of the most widely used and widely studied classes of neural network architectures. A large body of work has investigated the theoretical and empirical learning capabilities of Transformers. For instance, several works have studied the ability for Transformers to simulate optimization algorithms on in-context examples (see Gradient Updates #31 and #40). Other works have studied the ability of Transformer to perform linear algebra operations, algorithmically reason, and simulate Turing machines.
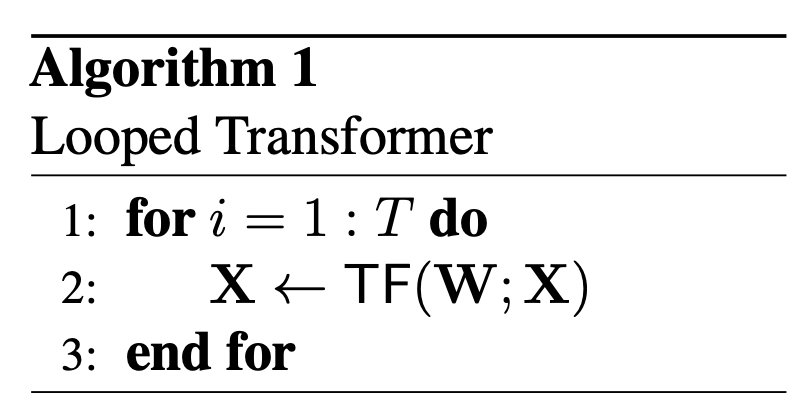
The work “Looped Transformers as Programmable Computers” theoretically studies the power of a single Transformer wrapped in a simple loop, where the Transformer’s output at step i is used as its input for step i+1. The authors “program” the Transformer by setting its weights to particular values that allow it to perform certain computations. As there is no external memory, the input sequence itself is divided into sections that are used by the Transformer in certain ways. One part of the sequence serves as a scratchpad in which computations are done, another serves as a memory for reading and writing data, and a third part contains instructions that tell the Transformer what to do. Also, the Transformer maintains a program counter in the input sequence to keep track of the next command to run, and uses particular positional encodings concatenated to the input.
Using this setup, the authors show that Looped Transformers can simulate powerful operations and run useful computations. First, the authors show that a small Transformer can run a “SUBLEQ” or “FLEQ” instruction; any computer that can execute SUBLEQ or FLEQ is Turing Complete, so the Looped Transformer is shown to be Turing Complete. Using the flexible FLEQ operation, the authors then show that many useful computations can be run by small Looped Transformers. For instance, small Looped Transformers can approximate arbitrary functions using the attention mechanism; simulate a calculator with operations like addition, inversion, and square roots; compute fundamental linear algebra operations like matrix multiplication and top eigenvector computation; and simulating learning algorithms like Stochastic Gradient Descent on in-context examples.
Why does it matter?
Importantly, the programmed constructions in this paper all use small Transformers — the deepest Transformer used has 13 layers, and the number of heads and width of the Transformers are of reasonable size as well. The key to the small layer count is the loop, which allows a constant depth Transformer to execute many instructions. In contrast, a Transformer without a loop would require more depth and/or width as the complexity of a desired computation grows (e.g. running more steps of SGD).
However, these “programmed” Transformer constructions may not be found in the actual set-ups that people use to train Transformers. In other words, backpropagation and gradient-based optimization algorithms typically used to train neural networks may not find these programmed Transformers. Still, these constructions show that it is theoretically possible for a reasonably-sized Transformer to perform many useful computations, and it is possible that future work can find benefit in using programmed Transformers as submodules in learning systems.
Author Q&A
We spoke with the authors of the study to find out more:
Q1: In terms of expressive power and ability to approximate functions, what is special about the Transformer architecture?
A: “The Transformer architecture is quite powerful in expressing both algebraic functions but also emulating the execution of deterministic programs, largely due to its attention mechanism and positional encodings. The input to a Transformer is a sequence of tokens, each of which is distinguished from the others by positional encodings. The attention mechanism then allows the model to focus on specific tokens based on these encodings and/or the values of the tokens. This provides the model with the capability to select from a set of complex functions of tokens to implement, as instructed by the input itself. This allows the network to essentially implement "algebraic" programs. Although ReLU/LSTMs and other architectures are also universal function approximators, there are well understood cases where these constructions require significantly more parameters to implement the same functionality as attention-based networks.”
Q2: Do you see a new type of programming in the future that relates to the Transformers constructed in your paper, or similar constructions?
A: “It's amazing that many models used for various prediction tasks have converged to using the Transformer architecture, and our research has shown that Transformers are capable of performing almost any type of deterministic computation, such as running general purpose algebraic programs. This exciting discovery has sparked our interest and we can't wait to explore the possibility of fusing these programmable models with larger, pre-trained ones through training or distillation algorithms. Imagine being able to effortlessly upload computational skills onto large Transformers, just like Neo in the Matrix exclaimed ‘I know kung fu’ after loading the Kung Fu training into his brain. Finally, we want to see more people play with these constructions, and program transformers that can do a lot of cool things. Perhaps even emulate Doom :)?“
Q3: Are there any exciting future directions that your work suggests?
A: “Our research suggests numerous exciting avenues for future exploration around programmable transformer networks. One of the most interesting opportunities is to investigate the potential for augmenting large language models with computational capabilities using programmable transformers, perhaps through a mixture of experts design, or learning from them via knowledge distillation. Our findings raise the possibility of hard-coding specific abilities into these models, which could offer a new approach to model modification beyond traditional fine-tuning. We're also curious about the existing computational abilities of current language models, such as the ability of ChatGPT to perform mathematical operations. Can models like ChatGPT learn to perform deterministic computations and algorithms through traditional training methods or do they need guidance in the form of instructions? It currently seems hard to make these models perform even simple operations like a square root of a number, and it's unclear if this is an inherent limitation, or if we're just not designing their prompts well. We're overall excited about the potential to explore the computational capabilities of LLMs and the possibility of upgrading models with algorithmic skills!”
Q4: Are there any other comments you would like to make?
A: We would like to acknowledge the previous works that have inspired our research. Specifically, the works of Gargcan and Tsipras et al, Akyurek et al, Von Oswald et al, which demonstrate the ability of transformers to perform in-context learning by emulating internally algorithms like gradient descent, and the work by Weiss et al. that provided crucial insights into the use of transformer networks as programmable boxes.
Editor Comments
Daniel: I think the connections between modern deep learning systems and modern computations is super interesting. Neural Turing Machines really kicked off a wave in this—I recently spoke to Ed Grefenstette who, in his DeepMind days, argued that Recurrent Neural Nets lie much closer to DFAs than to Turing Machines on the computational hierarchy (even though you can technically set an RNN’s weights so that it represents a Turing Machine). Also, I wanted us to use the below image for this highlight, but alas :( (yumpy is almost loopy, right)

New from the Gradient
Kyunghyun Cho: Neural Machine Translation, Language, and Doing Good Science

Steve Miller: Will AI Take Your Job? It’s Not So Simple.

Other Things That Caught Our Eyes
News
ChatGPT Is a Blurry JPEG of the Web "In 2013, workers at a German construction company noticed something odd about their Xerox photocopier: when they made a copy of the floor plan of a house, the copy differed from the original in a subtle but significant way."
Google’s AI-powered ‘multisearch,’ which combines text and images in a single query, goes global “Amid other A.I.-focused announcements, Google today shared that its newer “multisearch” feature would now be available to global users on mobile devices, anywhere that Google Lens is already available.”
U.S. Copyright Office tells Judge that AI Artwork isn’t Protectable “The U.S. Copyright Office has told a federal judge that artificial intelligence (AI) artwork can’t be protected. The Copyright Office is attempting to get a lawsuit brought against them by Stephen Thaler dismissed.”
Silicon Valley Is Turning Into Its Own Worst Fear “Because corporations lack insight, we expect the government to provide oversight in the form of regulation, but the internet is almost entirely unregulated.”
Meta, Long an A.I. Leader, Tries Not to Be Left Out of the Boom “Two weeks before a chatbot called ChatGPT appeared on the internet in November and wowed the world, Meta, the owner of Facebook, WhatsApp and Instagram, unveiled a chatbot of its own. Called Galactica, it was designed for scientific research.”
Papers
Daniel: I really want to mention the paper “Theory of Mind May Have Spontaneously Emerged in Large Language Models” because I think there is a lot of muddled thinking about LLMS, what “intelligence” means, and the nature of language and cognition. The paper is, undoubtedly, really interesting: the author administers false-belief tasks, used to test the presence of mental states in humans, to LLMs and finds that 2022 versions of GPT-3 solved over 70% of these tasks. Do these findings really suggest that “Theory of Mind-like ability may have spontaneously emerged as a byproduct of language models’ improving language skills”? I’m doubtful. I think we can say LLMs display intelligence in the sense that they can accomplish goals and solve tasks because next-word prediction combined with the incredible descriptive power of language allows them to say many things about the world. I’m not here to say that grounding (physical, visual, etc.) is required for us to call something intelligent if we’re operating on the goals-based definition, but it is important for tasks like the ones in this paper to be comparable when administered to LLMs vs humans. Not too long after I started writing this take, Melanie Mitchell posted that she also feels calling this “theory of mind” is vast overinterpretation:
Derek: Complete Neural Networks for Euclidean Graphs caught my eye. It develops theoretically powerful neural networks invariant to the symmetries of point clouds in Euclidean space; invariance to such symmetries is important for many tasks in the physical and computational sciences. The authors nicely apply and extend recent theory in this subject to develop their relatively low complexity architecture. Previous works have had a hard time developing methods with this level of theoretical expressivity, often resorting to computationally intractable theoretical constructions.
Tanmay: Google recently released its paper on scaling vision transformers (ViT’s) that allowed them to train a model with 22 Billion parameters (previously the largest ViT had 4B params). The model outperforms current methods on various tasks such as image classification and semantic segmentation. The most impressive result however is on the “zero-shot image classification” task, in which the vision transformer has to correctly classify an image generated by querying a text-to-image model with a unique prompt. Since these prompts are intentionally chosen to be unrealistic (such as “sushi dog house”, or “a snake made of salad”), it is highly likely that the model has neither seen the image, nor the exact prompt during its training. Yet, it is able to pick out the prompt from a list of options to correctly classify this image zero-shot. You can find similar examples in the appendix of their arxiv paper.
Industry News
A note from our friends at Cerebras:
The National Energy Technology Laboratory (NETL) and Pittsburgh Supercomputing Center (PSC) have pioneered the first ever computational fluid dynamics simulation on the Cerebras Wafer Scale Engine at near real-time rates. The workload tested was thermally driven fluid flows, also known as natural convection, an application of computational fluid dynamics (CFD).
According to NETL lab director Brian Anderson, this will dramatically accelerate and improve the design process for some really big projects that are vital to mitigate climate change and enable a secure energy future -- projects like carbon sequestration and blue hydrogen production.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!