




Welcome to the 56th update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter :) You’ll need to view this post on Substack to see the full newsletter!
Want to write with us? Send a pitch using this form.
News Highlight: Artificial Intimacy

Summary
Recent advancements in artificial intelligence have led to an increase in artificial intimacy. Many people now receive some level of affectionate satisfaction from interactions with machines.
Overview
The Wall Street Journal recently reported on several current examples of artificial intimacy, where people use software (and especially artificial intelligence) for companionship, empathy, and/or romance. This often takes the form of chatbots from companies such as Replika, Character.ai, and Snapchat, which make use of tools like LLMs that have rapidly improved over the last few years. Currently, millions of users interact with these chatbots: Replika has over 2 million monthly users, and Character.ai has received hundreds of millions of visits in a month
For example, the WSJ article reports on a 40 year-old who — after a divorce — started talking with a Replika bot that he considers his girlfriend. He says that he is currently hesitant to date humans at the moment, and talking to his artificial girlfriend is like “therapeutic role-play”. As another example, a 30 year-old from Illinois asks a Snapchat bot for dating advice, since her friends would typically give conflicting advice and since the bot would not judge her for what she shares.
Artificial intimacy is interesting and desirable enough to some people that it has motivated technical advances in artificial intelligence. Recently, SuperHOT, a model finetuned from LLaMa “with extra focus towards NSFW outputs,” pioneered a method to extend the context length of LLaMa from 2K to 8K tokens (see Update 54 for more on extending language model context lengths), which for example allows for generation of longer intimate stories or chats with longer history. Eugenia Kuyda, founder of Replika, started building the technology that led to Replika when she trained a chatbot on the text messages of her close friend that died in 2015.
Why does it matter?
As more and more people experience some form of artificial intimacy in their lives, it is important to study and be aware of its possible effects. Anecdotes from users that the WSJ interviewed show that artificial intimacy can substantially decrease loneliness or isolation, for instance for a married man that works the night shift as a security guard, or for an elderly retiree without relatives to talk to. On the other hand, in the WSJ article, psychologist Mike Brooks warns that access to artificial intimacy may reduce incentives to enter potentially uncomfortable situations and interact with humans.
The organizations that develop chatbots for artificial intimacy have the power to affect the social and romantic lives of their users. For instance, companies may update their chatbots to reduce NSFW conversations or roleplay. Replika updated their services in an attempt to remove adult content in February 2023 (before restoring the ability for certain users about a month later), which devastated certain users, as their artificial companions that they had been interacting with for so long had been essentially “lobotomized” by the company that developed them.
Further, as LLMs and other artificial intelligence models progress, the capabilities and behavior of the artificial intimacy apps can change dramatically. Even more people could experience artificial intimacy in the future, with systems that could be substantially more capable, and that will very likely be substantially different from the ones today.
Sources
Replika (Wikipedia)
Things I’m Learning While Training SuperHOT (kaiokendev)
Editor Comments
Daniel: I have a lot of mixed thoughts about artificial intimacy and the role of chatbots and other systems that can impact our emotive states. I worry about chatbots and other forms of artificial intimacy offering us another “easy way out” of actually talking to and engaging with the people around us. I also have concerns that AI tools which allow us to create “better”-looking versions of ourselves might induce feelings similar to body dysmorphia (even though they’re pretty cool!). I don’t think we should dismiss these systems as categorically bad—they can reduce loneliness and help people out in important ways. But I hope it’s pretty apparent that they’re far from a suitable alternative to interaction with real people. AI systems probably have a role to play as supplements in navigating complicated problems in helping people navigate their social, emotional, and romantic lives, but we should be clear-eyed about where they do and don’t belong. This being said, I am interested in where LLMs and AI systems can fit into human wellbeing. Joel Lehman wrote an incredible paper exploring this question—you can see our coverage and my Q&A with Joel on the paper here.
Research Highlight: Measuring Faithfulness in Chain-of-Thought Reasoning

Summary
As Large Language Models (LLMs) become more integrated into critical systems and decision making processes, it's imperative to understand how they arrive at their conclusions. For instance, unfaithful or post-hoc reasoning, where a model retroactively justifies an answer it has already decided upon, can lead to misplaced trust and potentially erroneous decisions. ‘Measuring Faithfulness in Chain-of-Thought Reasoning’ investigates the faithfulness of reasoning samples produced by LLMs using chain-of-thought prompting and develops metrics to measure it.
Overview
LLMs perform better when they produce step-by-step a.k.a “Chain-of-Thought” (CoT) reasoning before answering a question. While some suggest that LLMs become more interpretable when they explain their reasoning step-by-step, this is only true if the explanation genuinely reflects the model's thought process. The paper focuses on measuring the faithfulness of Chain-of-Thought (CoT) reasoning in large language models (LLMs). The experiments are designed to understand how accurately the reasoning steps in the CoT reflect the model's internal decision-making process. This is done by studying the following measures:
Post-hoc reasoning: This refers to a scenario where the model might generate a reasoning chain after it has already decided on an answer. Naturally, since post-hoc reasoning doesn't alter a model's response, such reasoning doesn’t seem faithful. To measure post-hoc reasoning abilities, the authors examine how the model predictions change under two interventions on CoT prompting. In particular, they study two types of interventions:
Early Answering Experiment:
Objective: To determine if the model has already decided on an answer before generating the full reasoning.
Method: The model is interrupted at various points during the generation of its reasoning to ask for an answer to the original question for which it is formulating a response. The frequency with which the early answer matches the final answer is measured.
Adding Mistakes Experiment:
Objective: To understand how the model reacts when a mistake is introduced into its reasoning.
Method: A mistake is introduced into the reasoning, and the model is then prompted to continue its chain of thought from that point. The final answer is then compared to the original answer.

These interventions are conducted on eight multiple choice tasks, such as ARC Challenge, ARC Easy etc which encompass grade-school science questions and algebra word problems. As shown in the figure, on ARC (Easy), ARC (Challenge), and OpenbookQA, there is a high match in model’s performance after early answering intervention and a complete COT. However, on AQuC, the CoT changes the answer more than 60% of the time showing low post-hoc reasoning. Similar findings are also observed for the intervention involving addition of mistakes. From the figure, it is evident that across both the interventions, the extent of post-hoc reasoning varies considerably between tasks.
Unfaithful reasoning due to test-time computation: When an LLM is provided with a longer input (or context), it potentially gives the model more computational steps, as it processes each token in the context. CoT reasoning provides a longer input to the model, as it includes multiple steps of reasoning leading up to the final answer. The authors hypothesized that the additional test-time computation provided by a longer context window might be responsible for the performance boost from CoT. However, this would mean that the model might be using CoT to improve performance without revealing it in the CoT. So, to test this, they replaced the CoT with filler tokens each consisting of a space followed by three periods. However, the accuracy remained consistent across various tasks, and even showed a decline in some, contradicting their initial hypothesis.
Encoded reasoning: Another hypothesis that the paper tests is that the phrasing choices in the reasoning could encode information that influences the model's answer. To test this, they paraphrased the CoT to see if rewording would change the predicted answer.
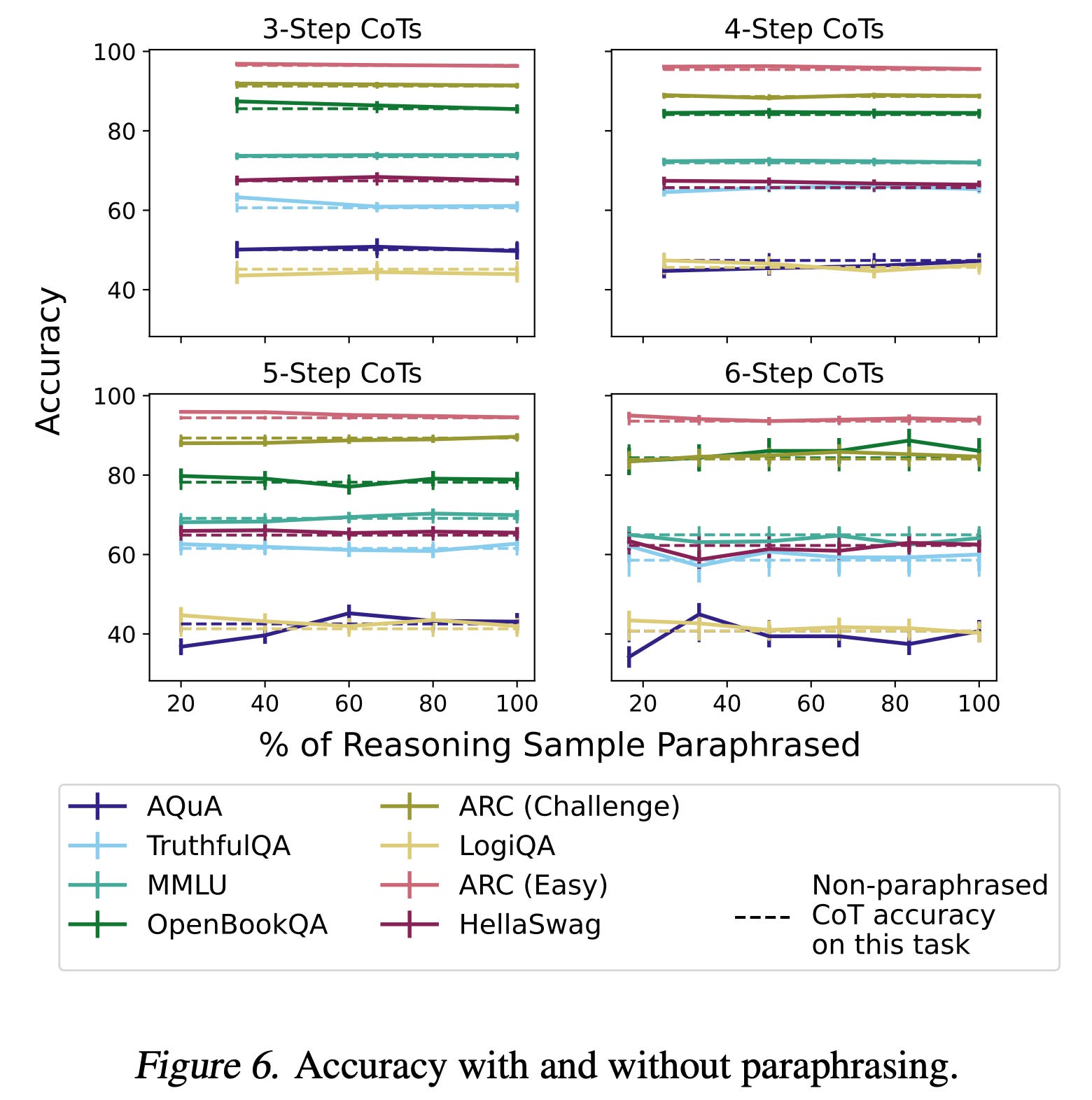
As shown in the figure, the results indicate that phrasing-encoded information isn’t the reason for the observed accuracy boost in CoT.
Why does it matter?
Understanding the reasoning process of LLMs is crucial for ensuring their reliability. If models are not faithful in their reasoning, their outputs can be unpredictable or erroneous. By investigating the CoT reasoning, this paper highlights the potential pitfalls and areas of improvement in LLMs, emphasizing the importance of careful model and task selection to achieve reliable results. Additionally, their proposed metrics provide a rigorous framework to test LLMs and their abilities.
New from the Gradient
Anant Agarwal: AI for Education

Raphaël Millière: The Vector Grounding Problem and Self-Consciousness

Other Things That Caught Our Eyes
News
San Franciscans Are Having Sex in Robotaxis, and Nobody Is Talking About It “Ever thought about getting down and dirty in a robotaxi? Want to light up a cig or a joint on the drive home from the club? You’re not alone.”
China’s draft measures demand ‘individual consent’ for facial recognition use “The pervasive use of facial recognition technology across all facets of life in China has elicited both praise for its convenience and backlash around privacy concerns.”
China's internet giants order $5bn of Nvidia chips to power AI ambitions “China's internet giants are rushing to acquire high-performance Nvidia chips vital for building generative artificial intelligence systems, making orders worth $5 billion in a buying frenzy fueled by fears the U.S. will impose new export controls.”
Amazon removes books ‘generated by AI’ for sale under author’s name “Five books for sale on Amazon were removed after author Jane Friedman complained that the titles were falsely listed as being written by her. The books, which Friedman believes were written by AI, were also listed on the Amazon-owned reviews site Goodreads.”
Google says AI systems should be able to mine publishers’ work unless companies opt out “Publishers should be able to opt out of having their works mined by generative artificial intelligence systems, according to Google, but the company has not said how such a system would work.”
A Zoom Call, Fake Names and an A.I. Presentation Gone Awry “Arthur AI, an artificial intelligence company in New York, received a message in April last year from a start-up called OneOneThree. Yan Fung, OneOneThree’s head of technology, said he was interested in buying Arthur AI’s technology and wanted a demonstration.”
Cruise begins testing self-driving vehicles in Atlanta “Cruise said Monday it has started testing its self-driving vehicles in Atlanta as the company continues its ambitious plan to launch its robotaxi service in multiple cities.”
Zoom says its new AI tools aren’t stealing ownership of your content “Zoom doesn’t train its artificial intelligence models on audio, video, or text chats from the app ‘without customer consent,’ according to a Monday blog post from Zoom’s chief product officer, Smita Hashim.”
ChatGPT gets several new features, including multi-document chat “OpenAI wants to alleviate the fear of ‘empty chats’ and now offers random suggestions for prompts to help you get started in ChatGPT. Other new features include chatting over multiple documents, which could prove particularly useful.”
Tim Cook says Apple is building AI into ‘every product’ amid questions over its plans “Artificial intelligence and machine learning are ‘virtually embedded in every product’, Apple chief executive Tim Cook has said, amid ongoing questions over the company’s plans.”
Every start-up is an AI company now. Bubble fears are growing. “A February report helped kick off the AI boom by stating that ChatGPT had 100 million users. In reality, consumer interest in chatbots might not be that strong.”
Eight Months Pregnant and Arrested After False Facial Recognition Match “Porcha Woodruff was getting her two daughters ready for school when six police officers showed up at her door in Detroit. They asked her to step outside because she was under arrest for robbery and carjacking.”
TikTok lets creators label AI-generated content more easily “TikTok is making it clear to creators that any AI-generated content must be labelled. The new label feature makes it easier for creators to disclose if their posts contain any AI-made content. A toggle labelled ‘AI-generated content’ is now found under "more options" when uploading a video.”
Papers
Daniel: First off, the Generative Agents paper is now open source! If you want more details on this line of work, I interviewed the lead author, Joon Park, a few months ago. As far as new work, I think SILO is exciting. Training on copyrighted data seems like something you’d want to avoid in developing a language model (or other model!), and OpenAI has faced multiple lawsuits over copyright violations because of ChatGPT’s training data. SILO’s training recipe allows data owners to remove their data from a model at any time—a model can be trained on public domain text data, and use other data in an inference-time-only datastore. This builds on other work in developing nonparametric language models and shows that using a nonparametric datastore addresses generalization challenges for models trained on permissively licensed data. Scaling the datastore size is key to this success, and the authors conclude that the encoder for a nonparametric distribution is more “robust to distribution shift” (specifically, domain shift) than the parametric component.
Derek: One thing that lots of people have been talking about (but that I have not yet sat down to fully understand yet) is “3D Gaussian Splatting for Real-Time Radiance Field Rendering.” The idea is that, as an alternative to prior NeRF variants, one can learn to represent a 3D scene as a set of 3D Gaussians. Their approach is fast to train, has high quality, and is very fast to render. Peyman Milanfar has a great post on how this approach surpasses prior NeRF variants as an effective interpolator, and Jon Barron has a great post on how the rasterization paradigm used in Gaussian splatting (as opposed to ray-tracing as in prior NeRFs) allows for fast training and inference.
Ads

How these investors achieved a 100% positive net returns track record
It may sound too good to be true but this investment platform's users are already smiling all the way to the bank. All made possible by Masterworks, the award winning platform for investing in blue-chip art.
Every single one of Masterworks’ 13 sales has returned a profit to investors for a 100% positive net return track record. With 3 recent sales, Masterworks investors realized annualized net returns of 17.8%, 21.5% and 35%.
How does it work? Simple, Masterworks does all of the heavy lifting like finding the painting, buying it, and storing it. It files each offering with the SEC so that nearly anyone can invest in highly coveted artworks for just a fraction of the price.
Shares of every offering are limited, but readers of The Gradient can skip the waitlist with this exclusive link.
See important disclosures at masterworks.com/cd
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!
Artificial Intimacy... as 3D Brain mapping Apprehensive Into-me-see, maybe.