




Welcome to the 63rd update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter :) You’ll need to view this post on Substack to see the full newsletter!
Want to write with us? Send a pitch using this form.
News Highlight: This AI robot chemist could make oxygen on Mars

Summary
Mars, a longtime focus of global scientific research, holds the human aspiration of discovering life and creating habitable zones. Utilizing Martian resources, especially for oxygen production, is crucial for sustainable human missions, as oxygen is essential for rocket fuel and life support systems and can't be sourced from the Martian atmosphere. The presence of water on Mars offers the possibility of large-scale oxygen generation through solar-powered electrochemical processes with an oxygen evolution reaction (OER) catalyst made from local Martian materials.
Recently, researchers in China have developed an AI robot that could significantly impact Mars exploration. This AI-powered robot chemist utilizes local Martian materials to produce catalysts that break down water to release oxygen. This advancement represents a practical step forward in making Mars missions more self-sufficient and showcases the potential of AI in space technology.
Overview
Researchers in China, led by Jun Jiang from the University of Science and Technology, recently published a study in Nature Synthesis, showcasing an AI-powered robot chemist, capable of extracting oxygen from Martian water. Using materials found on Martian surface, this robot is designed to synthesis catalysts that facilitate the process of breaking down water to release oxygen.
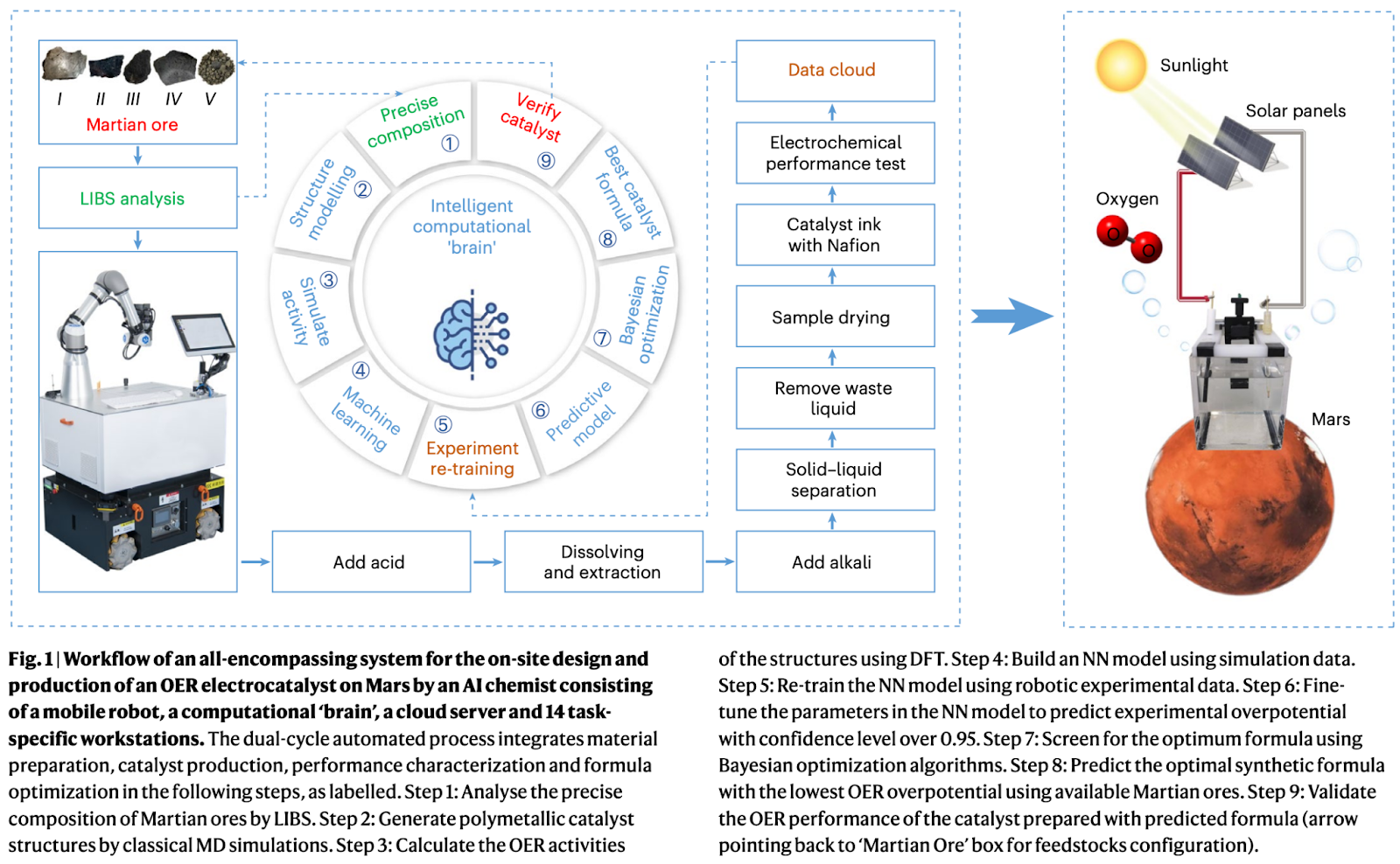
The AI chemist robot, without human intervention, automates the entire process of synthesizing oxygen evolution reaction (OER) catalysts from Martian meteorites. It follows a two layer workflow: 1) an outer layer consisting of a 12-step automated procedure and data handling, managed by the robot and several advanced chemical workstations, 2) an internal layer consisting of nine successive digital processes, handled by the computational “brain” of the system. The key steps conducted by each layer are highlighted below
Outer Layer (Experimental Cycle)
Initial Ore Analysis: The AI chemist starts by analyzing Martian ores using laser-induced breakdown spectroscopy (LIBS) for elemental composition.
Chemical Synthesis: It then processes these ores through physical and chemical pretreatments, including dissolving, mixing, separating, and drying steps to prepare the catalyst ink.
Electrochemical Analysis: This catalyst ink is utilized to construct the working electrode for electrochemical OER assessment at the electrochemical workstation. The gathered experimental data is then transmitted to a cloud server, where it undergoes machine learning processing by the system's computational 'brain'.
Inner Layer (Computational Cycle)
Computational Analysis: Here, the system uses molecular dynamics (MD) simulations and density functional theory (DFT) calculations to estimate OER activities of potential catalysts.
Model Building and Optimization: A neural network (NN) model is built and trained with this data, which is further optimized using robot-driven experimental data. This model predicts the best combination of Martian ores to synthesize the optimal OER catalyst.
Experimental Verification: The predicted optimal catalyst is then synthesized and its OER performance is experimentally verified.
Performance Testing and Optimization: The AI chemist conducts high-throughput testing and optimization, assessing various electrochemical parameters and stability under conditions simulating the Martian environment.
This end-to-end automated process dramatically accelerates the discovery and optimization of effective catalysts for oxygen production on Mars, showcasing a significant advancement in autonomous material synthesis for space exploration.
Why does it matter?
This development holds significant potential for future Mars missions. The robot's ability to produce nearly 60 grams of oxygen per hour per square meter of Martian material could drastically reduce the need to transport oxygen from Earth, paving the way for more sustainable human missions and possible settlements on the Red Planet. It also complements existing technologies like MOXIE, used on NASA’s Perseverance rover, which demonstrates oxygen production from the Martian atmosphere, primarily carbon dioxide.
Moreover, the technology has broader implications beyond space travel. Beyond oxygen production, the robotic chemist's versatility extends to synthesizing various useful catalysts for processes such as plant fertilization on Mars. This capability underscores the robot's potential applications in other celestial environments, like the Moon, highlighting the adaptability and utility of AI in space exploration.
Research Highlight: Pretraining Data Mixtures Enable Narrow Model Section Capabilities in Transformer Models

Summary
Researchers at Google DeepMind have unveiled a new paper, attempting to probe the limitations and capabilities of In-Context Learning with transformer models. In-Context Learning (ICL) refers to the ability to perform new tasks when prompted with previously unseen data or model training. The researchers tested the performance of transformers in a controlled setting where they could explicitly probe how the models perform on tasks representative of samples from in and outside of the pretraining distribution. The researchers found that “transformers demonstrate near-optimal unsupervised model selection capabilities, in their ability to first in-context identify different task families and in-context learn within them when the task families are well-represented in their pretraining data.” On less well-represented tasks, they “demonstrate[d] various failure modes of transformers and degradation of their generalization for even simple extrapolation tasks” on out-of-domain data. They concluded that impressive ICL abilities of Large Language Models (LLMs) and other transformer based networks may be an artifact of pre-training data coverage and not fundamental generalization capabilities.
Overview
The most impressive applications of transformers are in the vision and natural language domains, where training data consists of pairs of (text / image, label). In a similar manner, the DeepMind researchers studied sequences for arbitrary function mappings. Some advantages of modeling these kinds of sequences instead of natural text include having 100% correct labels, no sampling bias, and being able to explicitly map pairs to in / out of domain. After generating these pairs, the researchers investigated their impact on the pretraining process. Specifically, they wanted to investigate “how [the pretraining data] affects the few-shot learning capabilities of the resulting transformer model”.
The researchers go on to pretrain transformers for ICL using mixtures of distinct function classes in order to characterize the model selection behavior of the transformers during few-shot learning. In studying the ICL behavior of pre-trained transformers, the team probes the performance using functions that are out of distribution from the pretraining set. They go on to find strong evidence that pretrained transformers can correctly perform model selection (fit the curves) during ICL on distributions that are represented in the pre-training distribution. They were unable to find evidence that the transformers’ ICL behavior is capable of generalizing beyond their pretraining data. In their evaluations, they tested the performance of functions that the model has never seen, but are convex combinations (linear, non negative, and coefficients sum to one) of functions seen, as well as more extreme versions of functions seen (eg sinusoids with different frequencies)

To understand how transformers can fail at ICL tasks, we turn to three different examples provided by the authors. In each case, we have in red dots, the In-Context examples provided at inference. In Green, Orange, and Blue we have examples of the inferences from varying pretraining mixtures (Linear only, Sinusoids only, both Linear & Sinusoids). In the left case (a) the in context examples resemble a linear function and we can see how only the transformers pre-trained on linear inputs were able to achieve ICL while the sinusoids only (orange) fails to fit the points. In the middle case(b), the in context examples are sinusoidal and again, only those pretrained on mixtures representative of the ICL examples were able to fit well. In the rightmost figure (c), we have a convex combination of linear and sinusoidal functions, both of which are well represented in the pretraining process and transformers could not engage in ICL for these functions. Each of these examples demonstrate evidence of good ICL behavior only in cases that are representative distribution similar to the one used in pretraining.
Why does it matter?
Transformers have been the backbone behind the most powerful and well known recent advances in AI, leading some to speculate that artificial general intelligence (AGI) is coming soon, including from Microsoft’s OpenAI which shared their plans for AGI and beyond earlier in the year. As technology companies and world governments pour billions of dollars in investments into the field, it is crucial that all parties involved and impacted are aware of limitations. While there is no guarantee that transformers will always be the dominant architecture, understanding the limitations around in-context learning could be key to improving model performance as well as identifying kinds of tasks in which these models should be deployed.
Additionally, some may be tempted by these results to see a solution to ICL achieved by increasing the coverage of the target distribution in the training set; however, that too poses risks. Some of those risks relate to data privacy (where are we getting the extra training data from, how is that data being used, consent based access, etc), errors in the pretraining data (Scots wikipedia is fake) and introducing bias (sexualization of “latina” outputs in earlier versions of Stable Diffusion). All of the risks get compounded in quests to capture as much pretraining data as possible, without any guarantees that expanding the domain of training points will lead to the desired ICL behaviors.
New from the Gradient
Martin Wattenberg: ML Visualization and Interpretability

Laurence Liew: AI Singapore

Other Things That Caught Our Eyes
News
For the sake of collective sanity, I’ve expunged OpenAI articles from this edition (except for the next sentence). If you really must, this article in The Atlantic from Karen Hao has good context on things.
‘Lost Time for No Reason’: How Driverless Taxis Are Stressing Cities “Around 2 a.m. on March 19, Adam Wood, a San Francisco firefighter on duty, received a 911 call and raced to the city’s Mission neighborhood to help a male who was having a medical emergency. After loading the patient into an ambulance, a black-and-white car pulled up and blocked the path.”
Meta disbanded its Responsible AI team “Meta has reportedly broken up its Responsible AI (RAI) team as it puts more of its resources into generative artificial intelligence. The Information broke the news today, citing an internal post it had seen.”
France, Germany and Italy join forces to propose unified AI regulation in the EU “France, Germany and Italy have agreed on a proposal to regulate AI in the European Union. It pushes for mandatory self-regulation rather than binding rules for foundational models without an initial sanctions regime.”
Music publishers ask court to halt AI company Anthropic's use of lyrics “Three music publishers are asking a federal court judge to issue a preliminary injunction that would prevent artificial intelligence company Anthropic from reproducing or distributing their copyrighted song lyrics.”
Underage Workers Are Training AI “Like most kids his age, 15-year-old Hassan spent a lot of time online. Before the pandemic, he liked playing football with local kids in his hometown of Burewala in the Punjab region of Pakistan. But Covid lockdowns made him something of a recluse, attached to his mobile phone.”
Google will make fake AI products to help you find real gifts “Google’s AI-powered Search Generative Experience (SGE) is behind a bunch of new shopping features that aim to help users find niche or otherwise unique products for a friend or themselves. These include using AI to generate gift ideas or fashion items you can then shop for.”
Discord is already killing Clyde, its experimental OpenAI chatbot “Discord has updated the support page for its AI chatbot Clyde to say it's deactivating it at the end of the month. It will no longer be operational as of December 1. The platform introduced Clyde, powered by OpenAI technology, in March 2023.”
Cruise Exec Omitted Pedestrian Dragging In Summary of Self-Driving Car Incident to California DMV, Email Shows “An email obtained by Motherboard supports the CA DMV’s contention that Cruise misled the agency about what really happened during the October 2 crash.”
YouTube previews AI tool that clones famous singers — with their permission “It’s testing the Dream Track feature alongside a series of other music AI tools that can generate instrumental tracks from the likes of text prompts and humming.”
Google is embedding inaudible watermarks right into its AI generated music “Audio created using Google DeepMind’s AI Lyria model, such as tracks made with YouTube’s new audio generation features, will be watermarked with SynthID to let people identify their AI-generated origins after the fact.”
Airbnb acquires AI startup for just under $200 million “Airbnb has made its first acquisition as a public company, in a deal valued at just under $200 million, sources familiar with the deal told CNBC. The startup is called Gameplanner.AI, which has been in "stealth mode" since its founding in 2020.”
Google DeepMind wants to define what counts as artificial general intelligence “AGI, or artificial general intelligence, is one of the hottest topics in tech today. It’s also one of the most controversial. A big part of the problem is that few people agree on what the term even means.”
Microsoft unveils first AI chip, Maia 100, and Cobalt CPU “With 105 billion transistors, Azure Maia 100 is ‘one of the largest chips on 5-nanometer process technology,’ says Microsoft, referring to the size of the smallest features of the chip, five billionths of a meter.”
EU’s AI Act negotiations hit the brakes over foundation models “A technical meeting on the EU’s AI regulation broke down on Friday (10 November) after large EU countries asked to retract the proposed approach for foundation models. Unless the deadlock is broken in the coming days, the whole legislation is at risk.”
Papers
Daniel: A few interesting papers recently! On vulnerabilities, this paper out of IBM Research introduces a dataset of adversarial questions that provoke harmful or inappropriate responses from language models; they also introduce an automatic approach for identifying and naming vulnerable semantic regions. A preprint from researchers at the Kempner Institute proves mathematically and demonstrates empirically the impossibility of strong watermarking for generative AI models (a strong watermark is one that an attacker cannot erase without degrading the quality of a sample). I also like this paper from Murray Shanahan and colleagues that foregrounds the concept of role play to describe dialogue agents’ behavior without anthropomorphizing them.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!