

Update #59: Generative AI in the Classroom and Next-Token Predictors as Universal Learners
We consider the benefits and drawbacks of using generative AI to help teachers and students; Eran Malach argues that auto-regressive next-token predictors are powerful learners.



Welcome to the 59th update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter :) You’ll need to view this post on Substack to see the full newsletter!
Want to write with us? Send a pitch using this form.
News Highlight: Generative AI in the Classroom

Summary
In a recent Wired article, Khari Johson spoke with educators, AI researchers, and a founder of the “EdTech” startup MagicSchool about the role of generative AI in the classroom. According to their website, MagicSchool uses OpenAI models to help teachers fight burnout by assisting them in writing lesson plans, assessments, IEPs, and communications. This use case of generative AI runs counter to a common narrative of AI in classrooms about academic dishonesty. Rather than re-hashing the latest sensationalized AI cheating scandal (how did students cheat before Google and ChatGPT), we think it's important to highlight and discuss other aspects of generative AI in the classroom. Specifically, we’ll look at how it can help overworked educators reclaim more of their time and aid students in advancing their learning goals. Finally, we’ll offer some caution as the benefits of generative AI are often abstract and yet to be realized while the harms are real and ever present.
Overview
To date, most of the online attention and discourse around AI in the classroom focuses on cheating: either students using AI to cheat or faculty using AI to determine cheating and plagiarism. However, according to surveys run by the Walton Foundation and Quizlet, teachers are using AI more than students. These results may not be surprising toAdheel Khan the founder of MagicSchool, an education focused startup which uses ChatGPT to help more than 150K members. According to Adheel, MagicSchool’s software “can help teachers do things like create worksheets and tests, adjust the reading level of material based on a student’s needs, write individualized education programs for students with special needs, and advise teachers on how to address student behavioral problems.”
While teachers are using generative AI to help prepare for class, we also think there are other opportunities to incorporate it as a learning tool. Researchers at the University of Wisconsin-Madison published a guide titled “Considerations for Using AI in the Classroom” with a series of recommendations related to evaluating AI outputs. One of the most interesting recommendations involves “the instructor [using] AI to generate work … students analyze the sample work created by AI, with particular attention to evidence, sources, perceived bias, or other important elements for your course.” At first glance, this suggestion seems consistent with other metacognitive pedagogical strategies designed to enhance learning by encouraging students to think about thinking. As students interpret and critique the outputs of large language models, they can ideally help become better at independent self-regulated learning and critical analysts of their own thinking.
Why does it matter?
According to a report from the Bill & Melinda Gates Foundation, teachers spend an average of 95 minutes per day at home grading, preparing, and doing other job-related tasks. If generative AI could help teachers reclaim 20% of that time by automating lesson plans and assessment prep, each teacher could reclaim an extra 24 hours (20% * 95 minutes * 5 days a week * 39 weeks a year) per school year. That is time that can be redirected towards helping particular students in need or by providing personal and family time to educators who currently work an average of 53 hours per week.
In addition to being aware of the potential benefits AI brings to the classroom, educators should maintain a holistic view of the space and the potential vectors for harm. If an educator is not actively engaged in the process of generating content or classroom materials, their use of generative AI can risk any number of things including but not limited to:
Incorrect / Inaccurate answers
There are plenty of problems and domains that large language models do not excel at while others require “prompt hacking” to produce “good” results.
Propagating the racial, gendered, class, and other biases of the training data
Garbage in garbage out
EdTech has failed to deliver before and improved learning outcomes are not guaranteed
Editor Comments
Justin Landay: While I am in general excited about the various prospects regarding AI in the classroom, I do have some trepidation with one of the cited benefits of MagicSchool, specifically with respect to helping educators craft IEPs (Individualized Education Programs). IEPs are established to help every U.S public school student with special education needs by describing “present levels of performance, strengths, and needs, and creating measurable goals based on this data”. IEPs are a crucial tool for ensuring students with disabilities achieve fair and equitable learning outcomes. I worry, in our society that is already quick to disregard the needs of our most vulnerable, that automating the creation of IEPs could result in programs which are done in a haphazard way and fail to meet the individualized needs of the students.
Research Highlight: Auto-Regressive Next-Token Predictors are Universal Learners

Summary
Is attention all you need? Or, is some other component of the highly-effective modern Transformer learning paradigm more fundamental? A new study by Eran Malach of The Hebrew University argues the latter, contending that the auto-regressive next-token prediction framework begets powerful learners, even with very simple model architectures. The paper gives theoretical and empirical evidence that simple (linear, or multi-layer-perceptron-based) models can be very effective when trained on sequences with Chain-of-Thought reasoning.
Overview
The main theoretical result of the paper can be informally summarized as follows: any program that can be efficiently computed by a Turing machine can be learned by training a linear auto-regressive next-token predictor on some dataset. This is not the case in classical supervised learning, where linear predictors are weak; the fundamental difference is that in auto-regressive learning, each token is both an input and an output, so intermediate computations can be encoded in the training data (whereas in supervised learning, only input-output pairs are given).
Malach then proceeds to develop a theory of auto-regressive learning, with some analogies to classical learning theory. He defines notions of efficient learnability and approximation in the auto-regressive learning setting. Further, he defines a notion of length complexity of learning a class of functions with some class of models, where the complexity is given as the number of chain-of-thought tokens required for a model to compute the functions in the target class. This captures the intuition that harder tasks may require more intermediate computations and supervision, and hence longer chain-of-thought sequences.

Malach then empirically tested the theoretical prediction that simple models can perform well in auto-regressive next-token prediction. First, he trained a linear model on the TinyStories dataset, which is a synthetically generated dataset of short stories using simple vocabulary. The generated text of the resulting model is coherent and sensible, though it does make the occasional mistake (see examples below). Malach also trained a small MLP-based next-token predictor to solve 4-digit multiplication problems. This model only has 775 million parameters, but for this multiplication task it outperforms language models such as GPT-3.5 and GPT-4 that have orders of magnitudes more parameters.
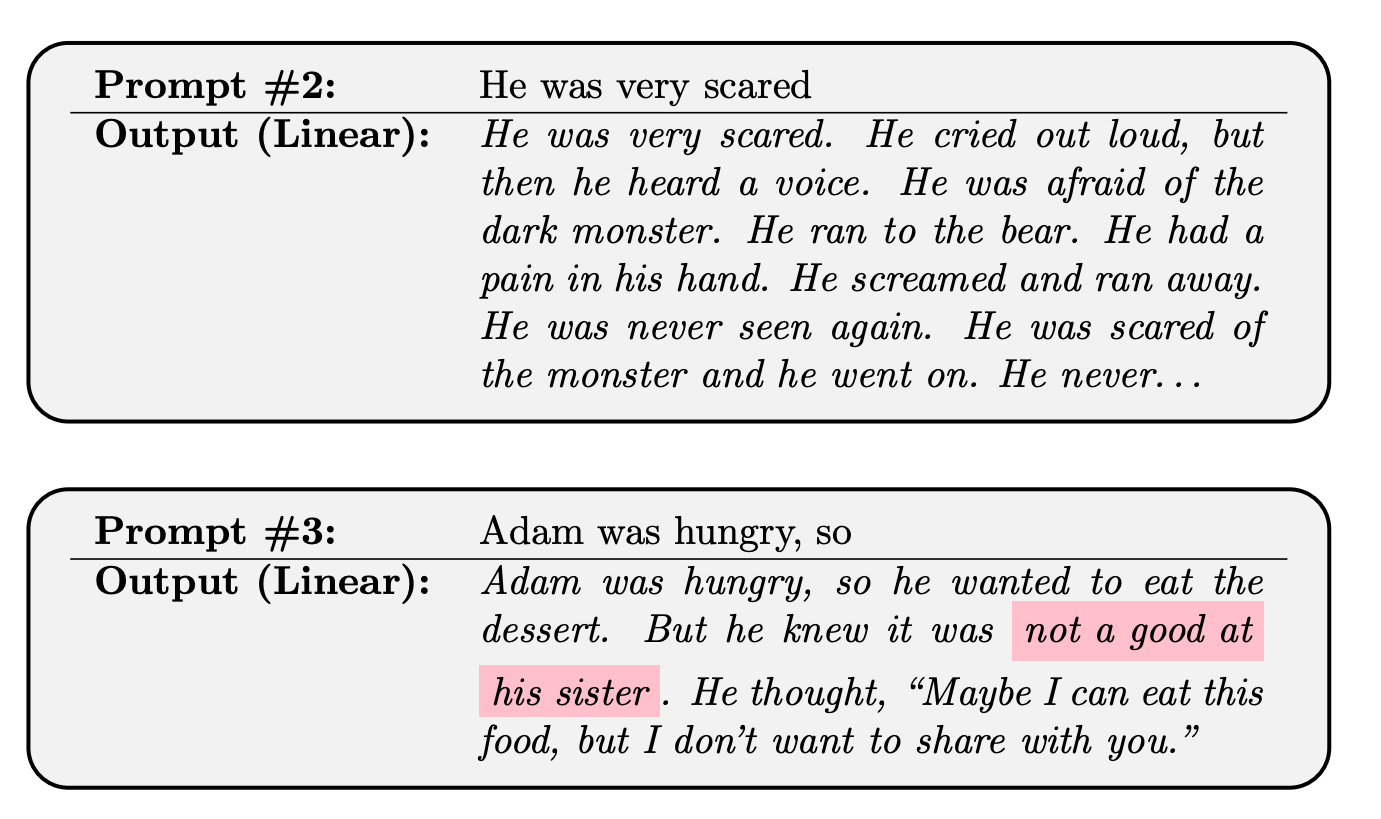
Why does it matter?
This paper works toward improving our understanding of the auto-regressive learners that have been so successful in various domains — particularly for language modeling. Importantly, it suggests promising directions for improving such models. While these models are typically Transformers, this paper’s results indicate that different models, including simpler ones, can in principle learn useful computations when given proper training data with intermediate computations. To find out more about promising future directions and implications of the work, we spoke with the author Eran Malach:
Author Q&A
Q: Do your theoretical results or intuition provide any guidance on how to choose the type of intermediate computations / reasoning to include in training sequences?
A: The main theoretical result implies that if we have a complex function that is composed of multiple steps, supervising the output of each step is the right thing to do. For example, if your data contains questions like: "Who was the US president when the lightbulb was invented", you better provide a step-by-step chain-of-thought solution (e.g. "The light bulb was invented in 1879, the US president in 1879 was ..."), and not just the final answer. We might be able to "skip" steps (i.e., give supervision only on some of the steps in the computation), but then we will have to pay a computational price (increasing the training-time, the number of samples, the size of the network etc.).
Q: Given that you find that the choice of model architecture used for autoregressive next-token prediction may not be important, what do you feel are promising future directions for improving LLMs or related models?
A: I think that investing more in generating high-quality data, with explicit and clear step-by-step reasoning, seems to be a promising way to move forward. I believe this is also indicated by other recent works in the field (e.g., the phi-1/1.5 LLM). That said, given that we can't really hope to have an "ideal" dataset, which provides enough explicit supervision to train small and simple models, architectural innovations and scale are still important to pursue.
Q: Do you see any promising problems to tackle within the theoretical framework for learning and learnability in the autoregressive setting?
A: Yes! I think that the introduction of autoregressive learning opens up exciting new avenues for theoretical research, and we just started to scratch the surface here. There are a lot of open questions regarding the interplay between the architecture, the data and the sequences of intermediate tokens in autoregressive learning. For example, in "classical" learning theory we have measures of complexity (e.g. VC dimension) that give us tight bounds on the number of samples that we need in order to generalize. Can we come up with similar measures that will bound the length of intermediate tokens required for solving a given task?
New from the Gradient
Arjun Ramani & Zhengdong Wang: Why Transformative AI is Really, Really Hard to Achieve

Miles Grimshaw: Benchmark, LangChain, and Investing in AI

Other Things That Caught Our Eyes
News
Watch your step: A new robot will police the NYC subways “The K5 autonomous robot is part of a broader push to incorporate emerging technology into the operations of the nation’s largest police department.”
AI in Focus: Machine learning goes to Congress “In a series of both hearings, both closed and open, the public sector grilled the private sector about accountability.”
How AI can help us understand how cells work—and help cure diseases “A virtual cell modeling system, powered by AI, will lead to breakthroughs in our understanding of diseases, argue the cofounders of the Chan Zuckerberg Initiative.”
Teachers Are Going All In on Generative AI “Tim Ballaret once dreamed of becoming a stockbroker but ultimately found fulfillment helping high school students in south Los Angeles understand the relevance of math and science to their daily lives.”
The AI Hype Train Has Stalled in China “Building his own large language model (LLM) is out of the realm of possibility for startup founders like Zhang Haiwei. He’d need hundreds of millions of dollars, and he’d be competing with China’s internet giants, who have a long head start.”
China and EU hold talks on AI, cross-border data flow amid renewed tensions “China and the European Union held talks on topics including artificial intelligence and cross-border data flows on Monday in Beijing, amid disputes over an EU probe into China's electric vehicle (EV) subsidies.”
Biden plans to work with world leaders to ensure AI's use as a tool of 'opportunity' “Speaking at the United Nations General Assembly on Tuesday, U.S. President Joe Biden made comments about his plan to work with competitors around the world ‘to ensure we harness the power of artificial intelligence for good while protecting our citizens from this most profound risk.’”
TikTok now lets creators label AI-generated content “TikTok will now let users label posts that have been enhanced by AI in any way. The company is also working on tools that automatically detect AI-generated posts.”
Deepfakes of Chinese influencers are livestreaming 24/7 “Scroll through the livestreaming videos at 4 a.m. on Taobao, China’s most popular e-commerce platform, and you’ll find it weirdly busy. While most people are fast asleep, there are still many diligent streamers presenting products to the cameras and offering discounts in the wee hours.”
EU considering whether to attend Britain's AI summit, spokesperson says “The European Union is considering whether to send officials to Britain's upcoming artificial intelligence safety summit, a spokesperson told Reuters, as the bloc nears completion of wide-ranging AI legislation that is the first of its kind globally.”
Microsoft Bing to gain more personalized answers, support for DALLE-E 3, and watermarked AI images “Microsoft’s Bing is gaining a number of AI improvements, including support for OpenAI’s new DALLE-E 3 model, more personalized answers in search and chat, and tools that will watermark images as being AI-generated.”
Papers
Daniel: It’s interesting to compare how language models acquire knowledge of syntax and other aspects of language to how humans learn—I think this paper that is pitched as “perhaps the closest approximation of human language acquisition with deep learning” is really neat. The model, CiwaGAN, combines unsupervised articulatory modeling with an unsupervised model of information exchange through the auditory modality. I think cognitively plausible models such as this are very exciting for researchers seeking to better understand human language acquisition and use. This paper encourages reasoning about ML privacy at a system level as opposed to a model level.
A few more interesting papers below:
Connecting Large Language Models with Evolutionary Algorithms Yields Powerful Prompt Optimizers
Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding
Sparse Autoencoders Find Highly Interpretable Features in Language Models
An Empirical Study of Scaling Instruct-Tuned Large Multimodal Models
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!
And yet forward we must move. Think of a world where every student gets individualized homework. We are only a stone’s throw away from that world.
I appreciate the effort to push beyond more reporting about cheating scandals. Magic School is an interesting project. Its business model functions through teacher ambassadors. Teachers sign-up to get access to curriculum on the condition that they share that curriculum with other teachers at their home institutions. At the moment, Magic School has over 10000 teacher ambassadors in over 1000 schools around the US.
I also appreciate the commentary on access and equity. As all current forward-facing products for teachers and students run off GPT architecture, they bring to the playing field all of GPT's implicit biases, inaccuracies, limitations, etc. While it is exciting that teachers now have products to create quizzes for them, for instance, these quizzes will most certainly be tilted through a particular interpretive filter--not necessarily the teacher's own---despite best efforts through prompt engineering. I personally am suspicious of this big push towards teacher efficiency without any real analysis of what the costs are of that efficiency. Not many folks are pausing to have that conversation, so kudos to the Gradient for stopping to pause.
As to AI tutorial systems privileging particular learning styles and particular kinds of learners, there is a growing body of research to support this claim. Surprisingly, most tutorial systems are set up for neurotypical learners. Learners with intellectual and cognitive diversities usually have to wait for later editions of these systems to have their needs met, and by then, the neurotypical learners have already gained an advantage through the first-wave of support. In this way, the notorious technological gap trickles down through systems ostensibly designed to close the gap. Check out the Department of Education's Report on AI and the Future of Education for more info. https://www2.ed.gov/documents/ai-report/ai-report.pdf. Section on "Learning."