

Update #48: Generative AI in Law & Art and Promptable Vision Models
We consider how generative models will impact art and the legal profession, and recent models allow users to specify vision tasks for them to complete.



Welcome to the 48th update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter :) You’ll need to view this post on Substack to see the full newsletter!
Want to write with us? Send a pitch using this form.
News Highlight: Generative AI and its role in transforming Law and Art

Summary
“Today, a new A.I. threat looms… There are warnings that ChatGPT-style software, with its humanlike language fluency, could take over much of legal work” warns the New York Times. Similarly, Noema magazine does an excellent job contextualizing our current debate around the impacts of Generative AI to fine arts to historical debates around photography, creativity, and commercialization. In both cases, the large amounts of biased and copyrighted data prompts many legal and ethical questions alongside heightened risks via the commercial deployment of generative AI models across domains and industries.
Overview
Like many industries, legal work is the latest profession ripe for disruption prompted by numerous advances in generative AI. Startups like Casetext and Open AI’s backed Harvey support many compelling legal use cases “for the things [Harvey] can do well” such as “load[ing] in a case’s documents and ask[ing] the software to draft deposition questions”. Unfortunately, that’s the only positively cited example in the New York Times article, leaving the reader to speculate on what else Harvey can do given its “proclivity to make things up, including fake legal citations”.
In addition to the successes of large language models such as GPT-4 and LLaMa, there have been parallel successes using generative AI for generating visual artifacts via models such as Stable Diffusion and DALLE-2. This has led to “a flood of AI-generated images in places previously exclusive to human authors.” This is prompting artists and lawyers to reconcile with central questions of rights and ownership with many parallels to 19th century debates regarding “the true author of a photograph [.] The camera or its human operator?”
Some of these questions were first resolved via the decisions of French courts which established copyright protections for photography. In court “plaintiffs successfully established that the development of photographs in a darkroom was part of an operator’s creative process... The camera was a pencil capable of drawing with light and photosensitive surfaces, but held and directed by a human author”. After securing a solid legal foundation for copyright and ownership, photography slowly and surely became embraced for its enumerable contributions towards fine art.
Why does it matter?
The lawsuit filed against Stability AI which Noema discusess brings forward many historic parallels and questions. It remains to be seen how modern courts will interpret ownership questions with the rise of generative AI. When copyrighted content is used to train generative models, do those outputs infringe the rights of the original copy holder? Does the prompt engineer bring to generative AI the same human authorship and sensitivities that photographers do? These are just a small subset of the ethical and legal questions that the community will need to grapple with as the technology advances.
The answers to these questions are complicated and remain difficult to answer for multiple reasons. We’ve seen that the lead scientists involved in the recent advances we’ve looked at know “successfully using the A.I. requires ample relevant data and questions that are detailed and specific” and that “every single large AI model is basically trained on stuff that’s on the internet”.
Thankfully, both the internet and all of the legal artifacts of the American criminal justice system are free of racial, gendered, and class biases that can be so pervasive in other elements of society /s. Additionally, GPT4, the large language model which powers ChatGPT, has no publicly available information around its training data, model cards, and architecture. Searches of the LAION-400 dataset which powers numerous computer vision models can quickly return “significantly high ration of NSFW results that contained vivid depictions of sexual violence”. Similarly, no human would be able to ever review the 500 billion image pairs in their latest dataset for Child Sex Adult Materials (CSAM), copyrighted images, and other NSFW and toxic images.
Taken together, advances in generative AI pose the potential to disrupt the careers of some lawyers and artists but many who engage with generative AI. From criminal defendants to children on a drawing app, people who interact with AI are exposed to heightened risk of negative externalities (marginalized communities especially). As generative models and their training sets grow in size, the difficulty in auditing both the inputs and outputs grows similarly. At risk are not only the rights of the copyright holders who make up the most valuable portions of training corpuses but the rights of children to be free from harmful online content as well as the rights of potential defendants from biased algorithmic lawyers & legal processes.
Editor Comments
Daniel: I find the contention around ChatGPT-like systems automating work in fields like the law interesting. Hallucination is rightly called out as a potential issue with these systems—even at a consultation level, if you plan to ask such a system about your medical condition or legal case, it might be unwise to act on the information it gives you without further verification. A few things come up here. One is the promise for interfacing with systems and databases to query for information as ChatGPT’s integration with Wolfram Alpha did (there is, of course, the problem of developing the appropriate data sources). Another is that there certainly is an interesting case for using LLMs to perform simpler legal tasks and make legal advice more accessible, but that this has to be accompanied with disclaimers and likely presented in a context that (a) requires verification from a professional before action on that advice is taken and (b) is generally more integrated in a system involving human legal experts. I can imagine a world where this substantially changes, but given current capabilities and limitations, methods for confining these systems to specific contexts where they can help the most people with as few risks as possible will need to be thought through carefully.
Research Highlight: Promptable Vision Models
Source:
[1] Segment Anything

Summary
Following the success of promptable natural language foundation models, recent work has developed promptable foundation models with visual capabilities. Such models allow users to specify highly flexible vision tasks by using text or other types of prompts. The Segment Anything project by Meta AI is a very successful and popular recent example. This project includes the release of a model called SAM that is capable of image segmentation given prompts like a point, bounding box, or even text.
Overview
Foundation models for various tasks and types of data have found much success recently. These foundation models are often promptable, meaning that flexible types of inputs (e.g. arbitrary text inputs) can be used to elicit certain desired behaviors from the models.
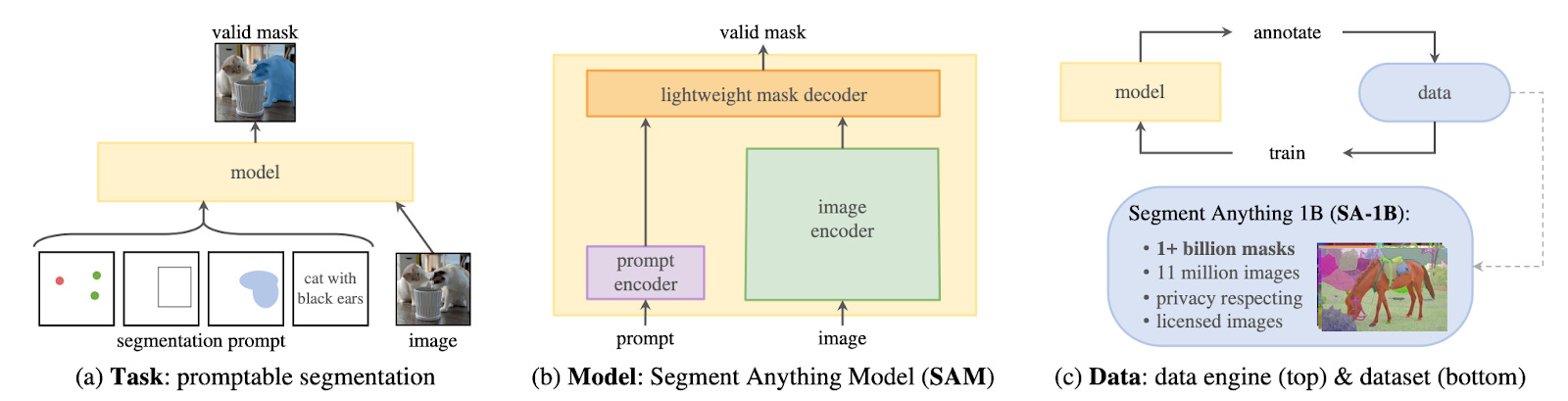
The Segment Anything project developed a foundation model for image segmentation. There were three main parts of this project (see above figure):
Task. The goal of the final model is to take as input a so-called segmentation prompt, and output a valid segmentation corresponding to the prompt. The prompts can take the form of a point on an image, a bounding box, a dense mask, or text. For instance, a text prompt “a wheel” and an input image of a car would lead to an output mask around a wheel of the car.
Model. The machine learning model (SAM) consists of a heavyweight image encoder (a Vision Transformer pretrained with MAE), prompt encoders, and a lightweight mask decoder that is fast to evaluate. The image encoder is more expensive to evaluate, but it can be used on each image once, after which the image embedding can be used with different prompts an arbitrary number of times.
Data. First, SAM was trained using public segmentation datasets, which are not large enough to train the final model. Then this version of SAM is used to generate more masks, which human annotators manually refine. SAM is modified and re-trained on this new data several times, and in the final stage it is capable of generating data in a fully automatic fashion. At the end of the process, the researchers end up with the SA-1B dataset that contains 11 million images and 1.1 billion masks, which contains orders of magnitudes more images and masks than previous datasets.
Meta AI has released code and weights for SAM. Further, they release the SA-1B dataset. Various experiments show that SAM is highly capable of several segmentation tasks in the zero-shot regime, even though it was not specifically trained on these tasks.
Many other recent works develop foundation models with visual capabilities. Most notably, GPT-4 is multimodal — capable of processing visual and text input. However, the vision capabilities of GPT-4 are not available in the OpenAI API, so some recent works have released usable vision-language models with similar goals. These include MiniGPT-4 and LLaVA, which both use frozen pretrained LLaMa LLM variants and CLIP-trained vision transformers along with a trainable linear projection; these two open-source efforts were able to achieve some of the multimodal capabilities of GPT-4 and Flamingo (e.g. question answering for input images, explaining jokes in images) by tuning open models with a limited amount of additional compute.
Why does it matter?
The Segment Anything project has been widely praised in the AI and computer vision communities. Soon after its release on Github, a Github issue was open with only the words “computer vision is dead.” Several follow-up works using SAM have come out very quickly, but some people have criticized these follow-ups as not containing much novel research content.
Unlike some other foundation models or large datasets, the Segment Anything project has publicly released model weights and the SA-1B dataset. The dataset shows some geographic diversity (e.g. the top three represented countries come from different continents, and most countries have at least 1000 images in the dataset), but many countries are still underrepresented (e.g. most African nations). Also, the authors investigated fairness and bias concerns with SAM. According to their evaluation, there is no significant difference in performance for people of masculine or feminine presentations, or for people of different skin tones. However, they did find that the model performed better on people of older perceived age, and that the model performed better on segmenting clothing for masculine-presenting subjects.
Author Q&A
This week’s author Q&A (with Ben Poole) is belated—from our Update #47 covering text-to-3D:
Q: What impactful applications can you envision for DreamFusion and/or its successors?
Creating 3D models is challenging, and currently requires a tremendous amount of expertise in software with steep learning curves. Generative 3D systems could enable anyone without these skills (like me!) to build 3D models. There are a number of uses for 3D assets in games, VR, AR, and 3D printing, and in the longer term I think generative 3D systems can help to lift existing 2D images and video into immersive 3D experiences. Imagine watching your favorite movie but being able to move around in VR instead of being stuck in your seat looking at one view. Beyond creative applications, generative 3D could be useful for education (explore the cell!), improving few view reconstruction in medical domains (shorter MRI scans), and improving simulators for robotics enabling safer and more robust autonomous systems.
Q: Do you see any other possible applications of your Score Distillation Sampling approach?
Score distillation sampling (SDS) turns any diffusion model into a differentiable loss that you can use to guide other generative systems. With diffusion image models, this means we can guide any process that renders images. SDS has already been used for vector graphic illustrations, creating fonts, and fine-tuning the output of pretrained image GANs using text. As diffusion models are trained in more domains, we hope that this approach can enable their use as priors for other tasks.
Q: Your framework leverages the specific structure of score-based models / diffusion models, beyond their ability to generate high-quality samples. Do you have any comments on this? What makes the structure of diffusion models special?
Generation is a sequential process that uses a trained model to output a sample. But when we want to use these models as priors, we need a way to score an image generated by a different system, like the renderings of a NeRF for DreamFusion. There are a few generic approaches to optimization-based sampling from generative models (e.g. Stein’s method) but they scale poorly in high dimensions. Alternatively, we can use something like the training loss to score samples (e.g. log-likelihood for autoregressive models, or lower bounds on the likelihood for VAEs and diffusion). Unfortunately images which score well according to likelihood are often poor quality samples. This is a counterintuitive property of high-dimensional spaces: regions that have high likelihood can have low volume and be far from typical good looking samples! (checkout this nice blog post for an explanation: https://sander.ai/2020/09/01/typicality.html).
Diffusion models have two nice properties that enabled us to design a loss function that works alright, but doesn’t entirely solve this problem. The first is that they learn a multiscale energy landscape of the data convolved with different amounts of noise, and the second is classifier-free guidance that enables us to alter the energy. Large values of classifier-free guidance are critical for SDS, but not essential for normal ancestral sampling approaches from diffusion models. We arrived at the SDS approach from the perspective of variational inference matching a unimodal learned distribution to the multiscale energy landscape of the diffusion model, but it has a bunch of problems we hope someone will find a fix for!
Q: Would steady improvements in the large pretrained text-to-image models improve methods like DreamFusion much (e.g. Imagen v2 or DALLE-3)? Where do you see room for further research and development?
I wish I could go on vacation for a year and watch text-to-3D get magically better… But sadly there are a number of problems with our approach that scaling text-to-image models is unlikely to fix. One direction is using generative models conditioned on other information beyond text (e.g. images, sketches, pose). Text control of view (like adding “side view”) is brittle, and doesn’t work well with CLIP-based models. Incorporating other data sources and conditioning would enable more 3D applications. Another issue is that SDS requires strong conditioning that reduces the diversity of outputs and sample quality. We need better ways of converting powerful generative models to differentiable priors!
New from the Gradient
Drago Anguelov: Waymo and Autonomous Vehicles

Joanna Bryson: The Problems of Cognition

Other Things That Caught Our Eyes
News
Google Devising Radical Search Changes to Beat Back A.I. Rivals “Google’s employees were shocked when they learned in March that the South Korean consumer electronics giant Samsung was considering replacing Google with Microsoft’s Bing as the default search engine on its devices. For years, Bing had been a search engine also-ran.”
Photographer admits prize-winning image was AI-generated “A photographer is refusing a prestigious award after admitting to being a “cheeky monkey” and generating the prize-winning image using artificial intelligence.”
Drake and The Weeknd AI song pulled from Spotify and Apple “A song that uses artificial intelligence to clone the voices of Drake and The Weeknd is being removed from streaming services. Heart On My Sleeve is no longer available on Apple Music, Spotify, Deezer and Tidal.”
FTC chair Lina Khan warns AI could ‘turbocharge’ fraud and scams “Artificial intelligence tools such as ChatGPT could lead to a ‘turbocharging’ of consumer harms including fraud and scams, and the US government has substantial authority to crack down on AI-driven consumer harms under existing law, members of the Federal Trade Commission said Tuesday.”
OpenAI’s hunger for data is coming back to bite it “OpenAI has just over a week to comply with European data protection laws following a temporary ban in Italy and a slew of investigations in other EU countries. If it fails, it could face hefty fines, be forced to delete data, or even be banned.”
Inside the secret list of websites that make AI like ChatGPT sound smart “An analysis of a chatbot data set by The Washington Post reveals the proprietary, personal, and often offensive websites that go into an AI’s training data.”
There Is No A.I. “As a computer scientist, I don’t like the term ‘A.I.’ In fact, I think it’s misleading—maybe even a little dangerous. Everybody’s already using the term, and it might seem a little late in the day to be arguing about it.”
Google’s Bard AI chatbot can now generate and debug code “Google’s conversation AI tool Bard can now help software developers with programming, including generating code, debugging and code explanation— a new set of skills that were added in response to user demand.”
DHS Announces First-Ever AI Task Force “On Friday, Department of Homeland Security Secretary Alejandro Mayorkas announced the formation of a new resource group focused solely on combating negative repercussions of the widespread advent of artificial intelligence technologies.”
Google to combine AI research units Google Brain, DeepMind “Alphabet Inc said on Thursday it will combine two of its divisions working on artificial intelligence research, Google Brain and DeepMind, into a new unit, Google DeepMind.”
Papers
Daniel: “Calibrated Chaos: Variance Between Runs of Neural Network Training is Harmless and Inevitable” is a neat paper shedding light on the observed variance in a neural network’s test-set performance between repeated runs (even with hyperparameters and other aspects of training held constant). Keller Jordan demonstrates this does not imply differences in model quality and cannot be removed without sacrificing other beneficial properties of training. It turns out that a series of independent coin flips (one for each test-set example) is a good approximation for the test-set accuracy distribution. Furthermore, ensembles of independently trained networks are well-calibrated, making variance between individual test-set performance runs inevitable; an intervention that removes variance would also sacrifice this calibration property. If compute weren’t a barrier, I’d be interested to see studies like this reproduced on a much larger scale.
Derek: The paper “SurfsUP: Learning Fluid Simulation for Novel Surfaces” by Mani et al. develops an interesting model for fluid simulations interacting with surfaces using graph neural networks (GNNs) and implicit surface representations. Previous work treats both the fluid and the surface itself as particles in a graph that is processed by a GNN. In contrast, this work uses a signed distance function (SDF) of the surface, either analytically computed for simple surfaces or approximated with an implicit neural representation for complex surfaces, to represent the surface and model interactions between fluids and surfaces. As a result, computation is not tied to the number of points used in an explicit representation of the surface, so their model is still efficient on large and complex surfaces. Interestingly, this approach leads to models that generalize well; even when training on a few types of simple surfaces like cubes and cylinders, the model is able to simulate fluids on complex surfaces like corals.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!
good read