

Gradient Update #1: FBI Usage of Facial Recognition and Rotary Embeddings For Large LM's
as well as other news, papers, and memes, and tweets in the AI world!

Welcome to the first biweekly Update from the Gradient1! If you were referred by a friend, we’d love to see you subscribe and follow us on Twitter!
News Highlight: FBI and Facial Recognition

Summary: Facial recognition AI techniques were recently used to identify someone who took part in the Capitol Riots via photos publicly available on Instagram.
Background: While this incident by itself may not seem particularly notable, it represents yet another example demonstrating the increased use of facial recognition by US police. For instance, in January the New York Times reported that The Facial-Recognition App Clearview Sees a Spike in Use After Capitol Attack. It quoted Armando Aguilar, assistant chief at the Miami Police Department, as saying “We are poring over whatever images or videos are available from whatever sites we can get our hands on.” The company has been controversial, since it sold its facial recognition app to private companies. For instance, Rite Aid deployed its facial recognition system in hundreds of U.S. stores. Additionally, the US Immigration and Customs Enforcement (ICE) has signed a contract to use the company's product.
Even with its technology to government agencies, Clearview AI is still controversial due to its data being scraped from the internet without the consent of any of the people in it. As a result, multiple cities such as Minneapolis and LA have banned use of Clearview AI or facial recognition technology altogether. In fact, it was made Illegal in Canada earlier this year, and The American Civil Liberties Union and the ACLU of Illinois have sued Clearview AI. Illinois has the The Illinois’ Biometric Information Privacy Act (BIPA), and has been sued by a group of consumers over possibly breaching it. Clearview AI has attempted to move this lawsuit to the Supreme Court.
There have also been cases unrelated to Clearview AI where use of facial recognition has led to wrongful arrests. Particularly, the New York Times’ article Wrongfully Accused by an Algorithm had described a particularly awful case in which Robert Julian-Borchak Williams was arrested for alleged robbery, despite having no evidence of his involvement except for a dubious facial recognition match. Robert WIlliams has sued the city of Illinois as a result. Additionally, it has been reported that the NYPD Used Facial Recognition Technology In Siege Of Black Lives Matter Activist's Apartment.
What do our editors think?
Andrey (3rd Year PhD Student at the Stanford Vision and Learning Lab): Much more so than DeepFakes or malicious RL agents, facial recognition is an application of AI that I think deserves a lot of attention and concern. As Clearview AI demonstrates, it is now safe to assume that if you have public photos associated with your name on the internet, government agencies can most likely find you using facial recognition. If used responsibly, this can lead to better law enforcement, as is seemingly the case in this instance, but there have also been several instances now where law enforcement has misused evidence stemming from facial recognition. Better oversight and regulation is therefore necessary, and soon.
Hugh (Visiting Researcher at Facebook AI and incoming PhD student at Harvard): I’m generally skeptical of such uses of AI, even if they initially seem to be for noble purposes, because they provide a foothold for future escalation of governmental AI surveillance. Though to be honest, I’m actually quite surprised that this was possible. My impression was that accurately identifying people off the internet via facial recognition was still quite far away. Facebook still frequently mistags me in photos despite having plenty of information on what I look like.
Justin (Senior Data Scientist at Riot Games): Given the large body of academic research which demonstrates time and time again the racial and gendered biases in facial recognition technology as well as the FBI’s long and sordid history when it comes to enforcing (or not enforcing) the law as it impacts marginalized communities, I am really hoping further evidence surfaces and that the identifications using Instagram photos and facial recognition and aren’t the sole body of evidence.
Paper Highlight: Rotary Embeddings
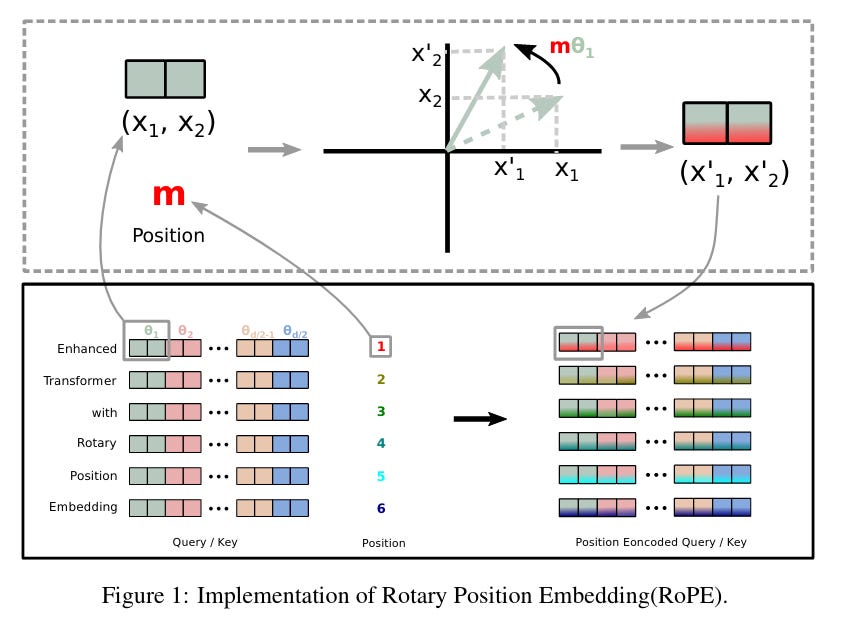
This week’s paper is RoFormer, a new method of doing positional embeddings in transformers.
Background: In 2015, researchers from Google Brain published one of the most important discoveries in deep learning: the Transformer. Since then, the transformer architecture and its scions have shattered nearly every single benchmark in NLP, powered the race to train ever larger language models, and have even shown improvements in other domains like music or vision.
What is this paper? One critical component of the transformer is the positional embedding, which tells the model the relative “distance” between words in a sentence. Unlike older models like the Recurrent Neural Network, which have a built in “distance” between different words intrinsic to how they are structured, the attention module in transformers by default cannot distinguish between different orderings of the sentence. The original transformer paper solved this by encoding the absolute position of each word directly into the model, but later work has suggested that this may not be ideal. The RoFormer proposes a new way of efficiently encoding positional embeddings based on insights from geometry. For more mathematical details, see the paper or an insightful blogpost by researchers at EleutherAI.
Why does it matter? Experiments using the new rotary position embeddings to train large language models show substantial speedups on a variety of model sizes (125M to 1B+ parameters) on both English and Chinese datasets. It’s very rare (and important) that such a small change can lead to such drastically improved results.
What do our editors think?
Hugh: I’m very excited every time something principled also works empirically in deep learning. The ever-wise Francois Chollet once commented that “being a ‘deep learning expert’ in 2021 is like being a ‘medicine expert’ in 1800. You know a lot less than you think.” Right now, I still feel we are in a stage where we throw a bunch of potential modifications at a task and hope that one of them shows improvements without a deep understanding of why, but I predict that over time, we’ll get a better and better understanding of each component of the Transformer and why it works so well on so many tasks.
Philip (Grad student at Stanford CS (on leave), formerly at Stanford AI Lab): I like that rotary positional embeddings have some conceptual justification (and not just deep learning alchemy). I also feel that these kinds of positional embeddings make even more intuitive sense than the absolute positional embeddings that the original transformer paper proposed. Think of it like how you’d do the grammar section on the SAT. You don't accomplish the task by reading straight left to right, but by breaking up the sentence and looking at it more like an ordering puzzle.
Adi (Software Engineer in Perception / ML at Nuro, Grad student at Stanford CS): I appreciated the (relatively) straightforward intuition behind rotary embeddings: find an encoding function f such that the inner product <f(a), f(b)> depends only on the values and their relative position. Also, the method really works well. The Eleuther AI blog post mentions that “rotary positional embeddings perform as well or better than other positional techniques in every architecture we have tried,” which is an uncommonly positive empirical result. It sometimes seems that simplicity and performance are at odds with one another in machine learning research, but this is a nice instance of a method that offers both.
Guest Thoughts
Jianlin Su (first author of the RoFormer paper): Thank you for including our paper in the newsletter! We believe the rotary position embeddings proposed in the RoFormer paper provide a more theoretically justified and intuitive technique of relative position encoding. We are running further experiments, but for now, the results show that RoPE significantly improves the speed of convergence of the Transformer models. Besides the proposed RoPE, we believe the idea of rotation provides a new perspective of incorporating information (position information in this case) into the transformer models.
Horace He (engineer at Facebook AI and EleutherAI: Whenever a new architectural tweak comes out, it’s always hard to tell whether it *really* works, or whether the authors just hyperparameter tuned their method more than the baselines. One way to separate the wheat from the chaff is via independent replication. With rotary embeddings, Lucidrains, Ben Wang, and Sid all independently implemented the change and immediately saw strong performance improvements. Lucidrains in particular has implemented more Transformer variants than maybe anyone else, and he “thinks it’s amazing” and “works super well”. The success of these replications make me think that rotary embeddings are here to stay.
Other News That Caught Our Eye
Apple hires ex-Google AI scientist who resigned after colleagues' firings Samy Bengio is expected to lead a new AI research unit at Apple under John Giannandrea, senior vice president of machine learning and AI strategy, two people familiar with the matter said. Bengio left Google last month amid turmoil in its artificial intelligence research department, following the firings of fellow scientists Margaret Mitchell and Timnit Gebru. He said he was pursuing "other exciting opportunities". Apple declined to comment on Bengio's role at the Apple company.
The autonomous vehicle world is shrinking - it's overdue Key Quotes: “There is a growing sense among experts and investors that the heady days when anyone with a couple of test vehicles, some LIDAR, and a vision for the future could launch a startup are at an end. Last month, John Krafcik announced that he was stepping down as CEO of Waymo after helping lead the company since 2015. Waymo still has a commanding lead in autonomous vehicles, but diminished expectations about the future of self-driving cars are affecting its business in other ways. Most investors are interested in more “structured” applications of automated driving technology.”
It Began As an AI-Fueled Dungeon Game. It Got Much Darker Key Quotes: “Utah startup Latitude launched a pioneering online game called AI Dungeon that demonstrated a new form of human-machine collaboration. The company used text-generation technology from artificial intelligence company OpenAI to create a choose-your-own adventure game inspired by Dungeons & Dragons. A new monitoring system revealed that some players were typing words that caused the game to generate stories depicting sexual encounters involving children. OpenAI CEO Sam Altman: “This is not the future for AI that any of us want." But, many users were not happy with this change; such moderation is difficult and may be oversensitive (as an example, users cannot refer to an “8-year-old laptop” without triggering a warning message).”
Deepfake detectors and datasets exhibit racial and gender bias, USC study shows Key Quotes: “Machine learning tools could be used to create deepfakes, or videos that take a person in an existing video and replace them with someone else’s likeness. The fear is that these fakes might be used in an election or implicate someone in a crime. Efforts are underway to develop automated methods to detect deepfake videos. But some of the datasets used to train deepfake detection systems might underrepresent people of a certain gender or with specific skin colors. This bias can be amplified in deepfake detectors, the researchers say.”
The EU’s New Proposed Rules on A.I. Are Missing Something Key Quotes: “The European Commission released its proposed rules for artificial intelligence last week. The rules divide A.I. systems into a set of applications that are prohibited, a set that are designated as high-risk and must adhere to certain requirements. It's not clear how strict the new rules actually are or whether they will, in fact, position the EU to be the dominant voice in regulation worldwide. The only truly concrete prohibition in the rules is a ban on ‘the use of ‘real time’ remote biometric identification systems in publicly accessible spaces”
Another Day on ArXiv
MLP-Mixer: An all-MLP Architecture for Vision “In this paper, we show that while convolutions and attention are both sufficient for good performance, neither of them are necessary. We present MLP-Mixer, an architecture based exclusively on multi-layer perceptrons (MLPs) We hope that these results spark further research beyond the realms of well established CNNs and Transformers.”
Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet “A ViT/DeiT-base-sized model obtains 74.9\% top-1 accuracy in ImageNet tests. Results indicate that aspects of vision transformers other than attention, such as the patch embedding, may be more responsible for their strong performance than previously thought. We hope these results prompt the community to spend more time trying to understand why our current models are as effective as they are.”
Are Pre-trained Convolutions Better than Pre-trained Transformers? “CNN-based pre-trained models are competitive and outperform their Transformer counterpart in certain scenarios. Findings suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. We believe our research paves the way for a healthy amount of optimism in alternative architectures.”
Carbon Emissions and Large Neural Network Training “We calculate the energy use and carbon footprint of several recent large models-T5, Meena, GShard, Switch Transformer, and GPT-3. Large but sparsely activated DNNs can consume <1/10th the energy of large, dense DNNs without sacrificing accuracy. Remarkably, the choice of DNN, Datacenter, and processor can reduce the carbon footprint up to 100-1000X.”
PanGu-α: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation “Pretrained language models with hundreds of billions parameters such as GPT-3 have demonstrated strong performances on natural language understanding and generation with few-shot in-context learning. In this work, we present our practice on training large-scale autoregressive language models named PanGu-α, with up to 200 billion parameters. The experimental results demonstrate the superior capabilities of PanGu-α in performing various tasks under few-shot or zero-shot settings.”
Fun Tweets We Saw






Closing Thoughts
If you enjoyed this piece, give us a shoutout on Twitter!
Have something to say about Rotary Embeddings or the FBI’s usage of facial recognition? Shoot us an email at gradientpub@gmail.com and we’ll select the most interesting thoughts from readers to share in next week’s newsletter!
Finally, the Gradient is an entirely volunteer-run nonprofit, so we would appreciate any way you can support us!
For the next three months, the Update will be free for everyone. Afterwards, we will consider posting these weekly updates as a perk for paid supporters of the Gradient! Of course, guest articles published on the Gradient will always be available for all readers, regardless of subscription status.