

Gradient Update #28: China's Surveillance State and CVPR Best Paper
In which we discuss China's increasingly sophisticated method for surveillance and this year's CVPR Best Paper, "Learning to Solve Hard Minimal Problems."

Welcome to the 28th update from the Gradient! If you were referred by a friend, subscribe and follow us on Twitter!
News Highlight: China’s Surveillance State is Growing. These Documents Reveal How.

Summary
A year-long investigation from the New York Times into China’s surveillance of its citizens reveals the country’s centralized, massive and thorough system for tracking personal data. While previously Chinese state surveillance was thought to be limited to tracking phones and locations, documents show that it now encompasses biometrics such as iris scans and DNA samples as well. As governments weaponize advancements in AI to exert authoritarian rule, such an intrusive and expansive system run by one of the world’s largest countries raises ethics and privacy concerns for citizens all around the world.
Background
China’s government-sponsored surveillance of its citizens has been known and documented since 2014. The program started with a few provinces installing surveillance cameras and creating a massive database to store an array of personal information for each individual. The New York Times in its recent investigation of more than 100,000 government documents finds that not only has the scale of this surveillance expanded to include all Chinese provinces and regions but that it has also grown to be more invasive and thorough.
While cameras have always been known to be a central component of this system, their number is substantial: over half of the world’s 1 Billion surveillance cameras are in China. A document from the Fujian district of China shows that the province’s facial recognition system has roughly 2.5 Billion images at any given time, which is three times larger than the largest facial recognition dataset in the United States. The police are extremely precise in how they place and orient these cameras too. Another document from Xiqiao reveals that the police aimed for “maximum surveillance” in targeting the locations of these cameras and placed them in areas of “basic needs” such as shopping, learning, and living. The bidding document also goes on to list the exact latitudes and longitudes where these cameras must be installed.
The government also uses phone trackers to scrape data from mobile phones, including users’ locations, contacts, and app data. The most concerning use of these trackers can be seen in Guangdong, where authorities intended to use mobile trackers to find which phones had an Uyghur to English translation app. This is evidently tied to the Chinese government’s continued suppression of the Uyghur community, which the United States declared a genocide in 2021.
The next wave of surveillance efforts has come in the form of tracking biometric data. In the city of Zhongshan, police have installed microphones that can record audio up to a radius of 300 feet. This data is then fed into voice recognition software and saved in a centralized database. In the city of Xinjiang, where millions of Uyghurs live, a government contractor built a database to store 30 million iris scans – enough to cover the city’s entire population. The last tool in this set of biometrics tracking is perhaps the most important one – DNA samples. Today, 25 out of 31 Chinese regions and provinces collect and store DNA samples from men. Since the Y chromosome is passed on from father to son, a DNA sample from one individual could then be easily used to look up matches in the state’s dataset and pinpoint the individual’s exact lineage, ethnicity, and location. In the context of state-sponsored censorship and oppression of ethnic minorities in China, this surveillance system paints a grim picture of the government’s control over its citizens.
Why does it matter?
While this bit shouldn’t need telling, let’s go ahead and do it anyway. Today, a government that has been known to commit genocide against minority communities has access to a centralized database containing the location, appearance, social media posts, banking information, and biometrics of millions of individuals. The surveillance that continues publicly in the name of “catching criminals faster” has the potential to lead to ethnic cleansing. While China’s surveillance is unlikely to severely affect the western world, the oppression of an entire ethnic community and the potential for others to suffer the same consequence should be reason enough for the world to be alarmed. We’ll leave you with a direct quote from a document obtained by the Times from the Gansu province in China regarding its DNA collection efforts:
“Do not miss a single family in each village. Do not miss a single man in each family.”
Editor Comments
Daniel: As we evolve more and more sophisticated technologies, so too do we develop more powerful methods of surveillance and oppression. Given China’s track record of surveillance, I’m not surprised that it’s beginning to incorporate biometrics and other novel techniques. As always, this leaves me with plenty of worries–once someone’s opened the Pandora’s Box, it’s impossible to close.
Paper Highlight: Learning to Solve Hard Minimal Problems (CVPR Best Paper Award)
Summary
The winners of the 2022 CVPR Best Paper Award–Petr Hubry of ETH Zurich and three colleagues–develop a framework for quickly solving so-called minimal problems, which have numerous applications in computer vision. Their method is based on learning to use a neural network to initialize a numerical solver. The framework allows for significantly faster solving of minimal problems; on one minimal problem, their method can obtain solutions in tens of microseconds, whereas previous methods at least took milliseconds.
Overview
Minimal problems are systems of polynomial equations that have a finite number of solutions. These arise in various applications in computer vision. For instance, minimal problems show up in 3D reconstruction tasks, in which real-world 3D objects are reconstructed based on multiple 2D photos taken of them. Minimal problems often have many spurious solutions, so finding all of these solutions would incur large runtime costs without any benefit. However, existing solvers often require computing many solutions.
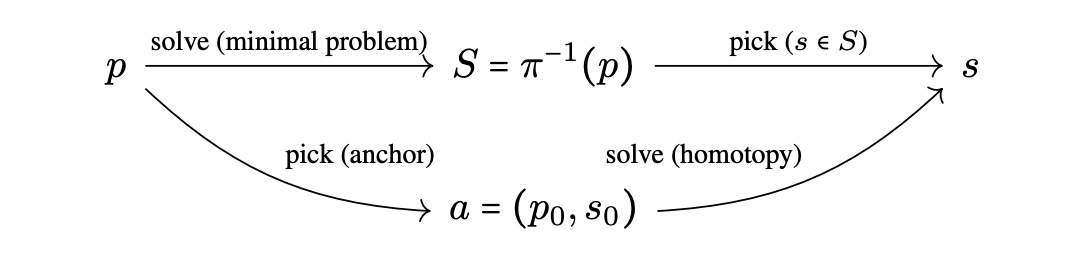
For instance, in the RANSAC framework, a minimal problem solver is used to compute large numbers of candidate solutions, each based on sampled data points. In the above diagram, this is the arrow from p to S. Then a solution s is picked from this candidate set S. Hubry et al. instead first chooses a small set of anchors A, which are problems and associated solutions that are close to the input problem p. Then they learn a selection strategy with a neural network, which chooses a good candidate anchor a = (p_0, s_0) (arrow from p to a in the diagram). Finally, they use a numerical solver known as a real homotopy continuation method, which updates (p_0, s_0) to (p, s) by tracing solutions from p_0 to p (arrow from a to s). Their method’s computed solution is then taken to be s. Assuming a small set of anchors is known, and the neural network for selecting an anchor is fast, their method runs much faster than previous methods due to not having to solve for all of the spurious solutions in S.
Why does it matter?
The speedups from this work allow solving certain minimal problems in tens of microseconds, whereas earlier work required milliseconds. Further, Hubry et al. focus their implementation efforts on a few minimal problems. As many other problems are minimal problems — including finding correspondences in images and visual odometry in robotics — future work could possibly use their framework to quickly solve problems in many application areas.
Since Hubry et al.’s method has a learnable neural component, it requires fitting a training data distribution. While this is in some cases a drawback, this may be beneficial for situations with a particular data distribution that has a learnable structure; for instance, the authors note the case of cameras mounted on a vehicle, where there are certain restrictions on the motions of the cameras and their orientations with respect to each other. Moreover, this work uses a simple 6-hidden-layer multilayer perceptron with PReLU activations as the architecture for the neural component of the method. This allows for good performance with fast inference, but it is also possible that future work can improve this neural architecture or the training methodology.
Editor Comments
Daniel: This is a really interesting paper and a refreshing step away from “Language Models are X.” Optimization problems are foundational to many problems we deal with today, and it’s great to see continued investment in solving them more efficiently.
New from the Gradient
Chip Huyen: Machine Learning Tools and Systems

Preetum Nakkiran: An Empirical Theory of Deep Learning

Other Things That Caught Our Eyes
News
Microsoft Plans to Eliminate Face Analysis Tools in Push for ‘Responsible AI’ "The technology giant will stop offering automated tools that predict a person’s gender, age and emotional state and will restrict the use of its facial recognition tool."
Meta Agrees to Alter Ad Technology in Settlement with U.S. “Meta on Tuesday agreed to alter its ad technology and pay a penalty of $115,054, in a settlement with the Justice Department over claims that the company’s ad systems had discriminated against Facebook users by restricting who was able to see housing ads on the platform based on their race, gender and ZIP code.”
U.S. court will soon rule if AI can legally be an ‘inventor’ “Can artificial intelligence (AI) be legally listed as an inventor? After all, if AI can legally invent products, the number of patents on drug-discovery tools will shoot up fast. The issue is currently before a United States court. The U.S.”
Papers
Learning to Play Minecraft with Video PreTraining (VPT) We extend the internet-scale pretraining paradigm to sequential decision domains through semi-supervised imitation learning wherein agents learn to act by watching online unlabeled videos… with a small amount of labeled data we can train an inverse dynamics model accurate enough to label a huge unlabeled source of online data – here, online videos of people playing Minecraft – from which we can then train a general behavioral prior. Despite using the native human interface (mouse and keyboard at 20Hz), we show that this behavioral prior has nontrivial zero-shot capabilities and that it can be fine-tuned… For many tasks our models exhibit human-level performance, and we are the first to report computer agents that can craft diamond tools, which can take proficient humans upwards of 20 minutes (24,000 environment actions) of gameplay to accomplish.
ARF: Artistic Radiance Fields We present a method for transferring the artistic features of an arbitrary style image to a 3D scene. Previous methods that perform 3D stylization on point clouds or meshes are sensitive to geometric reconstruction errors for complex real-world scenes. Instead, we propose to stylize the more robust radiance field representation. We find that the commonly used Gram matrix-based loss tends to produce blurry results without faithful brushstrokes, and introduce a nearest neighbor-based loss that is highly effective at capturing style details while maintaining multi-view consistency. We also propose a novel deferred back-propagation method to enable optimization of memory-intensive radiance fields using style losses defined on full-resolution rendered images… our method outperforms baselines by generating artistic appearance that more closely resembles the style image.
Bayesian Structure Learning with Generative Flow Networks Recently, a novel class of probabilistic models, called Generative Flow Networks (GFlowNets), have been introduced as a general framework for generative modeling of discrete and composite objects, such as graphs. In this work, we propose to use a GFlowNet as an alternative to MCMC for approximating the posterior distribution over the structure of Bayesian networks, given a dataset of observations… Through evaluation on both simulated and real data, we show that our approach, called DAG-GFlowNet, provides an accurate approximation of the posterior over DAGs, and it compares favorably against other methods based on MCMC or variational inference.
Tweets



Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at gradientpub@gmail.com and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! If you enjoyed this piece, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!