

Update #79: Does AI Music Have a Future? Can Vision-Language Models See?
Two leading AI music startups are sued by major record labels; researchers find that VLMs are poor at understanding basic spatial information.


Welcome to the 79th update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter. Our newsletters run long, so you’ll need to view this post on Substack to see everything!
Editor Notes
As with our last Update, there’s been AI news, but there’s also been lots of other news. I hope you’ve been staying sane and that some of you, like our wonderful editor Cole, are on a beach somewhere and not thinking about AI at all (if you’re reading this, though, that’s probably not you).
The two podcast conversations I posted since last episode were both ones I really enjoyed: New South Wales has a very interesting and thoughtful approach to using AI in education, and David Pfau is one of the most thoughtful scientists the ML community is lucky to have.
Also: I hate writing this probably more than you hate reading it, but it would be so, so helpful if you’d consider helping us out a bit by leaving reviews or feedback if you’re getting something from any of our content. I don’t have too many reviews on Apple Podcasts or Spotify yet, and they really help a lot :)
As always, if you want to write with us, send a pitch using this form.
News Highlight: Training AI music models is about to get very expensive
Summary

Suno and Udio, two leading AI music startups, were sued by major record labels on June 24 — the allegation is that the companies made use of copyrighted music in their training data at massive scale. In contrast, YouTube has taken an aboveboard approach where it offers lump sums to record labels to license their catalogs for training. The outcome of this lawsuit will determine the shape of AI music generation, and, possibly, whether there is any future for it at all.
Overview
Suno and Udio are to music what Stable Diffusion and its ilk are to images: both offer models that can, given a natural language text prompt, generate music. Unsurprisingly, the training recipe for each of the models is proprietary — and record labels allege that both startups have engaged in copyright infringement in model training and output.
While there are similarities to the New York Times vs. OpenAI’s case, Suno and Udio appear to have even less plausible deniability than their fellow offender: while New York Times articles and their content might appear in places besides the site itself, some say it’s clear that the AI music startups must have pulled in large databases of commercial recordings.
Furthermore, the case alleges that Suno’s and Udio’s tools are more imitative than generative: their output mimics the style of copyright-protected artists and songs. Suno and Udio both claim that they prioritize originality, and both have safeguards in place that prevent users from naming specific artists in a query, but (as you will know if you’ve spent time with any generative AI system) loopholes abound.
According to James Grimmelmann, professor of digital and information law at Cornell Law School, there are three possible ways the case could go: the court determines, wholly in favor of the startups, that the companies did not violate fair use or imitate copyrighted works too closely; a mixed bag, where the court finds Suno and Udio did not violate fair use in training but must better control model output to avoid imitating copyrighted works; or, in favor of the record companies, the court finds issue with both the training and output of the AI models, meaning that the companies cannot train on copyrighted works without licenses or allow outputs that closely imitate copyrighted works.
Our Take
I’m going to have an inevitably biased take on AI music in general, because I think a profound aspect of being a musician and producing music is the sensate part of it: producing orchestral music on a computer isn’t the same as sitting as a member of an actual orchestra. Yes, democratization is a thing, but the difficulty of putting something like an orchestra together and getting everything right is precisely what makes the outcome so valuable and important. All this is to say, I can personally live without AI-generated music, though I recognize the value people find in it.
I also like the point that this Washington Post article points to: like it or not, a technology that makes it easy for you to generate and share music is going to impact the way you interact with and value music itself. Just as telegraphy and newer technologies have changed how we write and streaming services and their ilk have changed how we consume and appreciate TV shows and movies, so too would tools like Suno and Udio shift our relationship to music if they come into widespread use. I’m not entirely sure that’s a relationship to music that I want to have.
But, I should comment on the case itself — the stakes are indeed very high for AI music companies because there aren’t so many options for music in the public domain. So it is existential for these companies. Your reaction to the verdict in this case, then, probably indicates something about your stance towards AI music and whether you think a future with it is a good future.
On the other hand, there is also a future with licensing analogous to the deals we’re seeing between OpenAI and publishers. But, given the music industry’s power, the prices for these licensing deals is bound to be very high — only YouTube and peers with as much money would be able to cough up the cash. In this world, the future and shape of these systems once again relies on the value judgments of a handful of actors.
—Daniel
Research Highlight: Vision language models are blind

Summary
Researchers from Auburn University and the University of Alberta found that state-of-the-art large language models with vision capabilities (VLMs) are surprisingly poor at understanding spatial information involving basic geometric shapes, such as whether two circles overlap. They propose BlindTest, a new benchmark of 7 simple tasks that are unlikely to have prior answers in natural language on the Internet, to test VLM ability to "see" images like humans do.
Overview
Existing VLM benchmarks (such as MMMU and ChartQA) cover a wide range of subjects but the input images are not always necessary for answering the questions, i.e., answers may be inferred from the textual question and answer choices alone or memorized by the models from Internet-scale training. Motivated by this gap and inspired by visual acuity tests given to humans by optometrists, the authors design 7 low-level vision tasks that involve 2D geometric primitives. They then test four VLMs that rank the highest on existing multimodal vision benchmarks – GPT-4o, Gemini-1.5 Pro, Claude-3 Sonnet, and Claude-3.5 Sonnet. For each task, they prompt VLMs with two different questions that are semantically equivalent. The tasks and results are as follows:
Counting line intersections. Across 150 images of two colored lines that intersect at exactly 0, 1, or 2 points, the best accuracy is 77.33% (Sonnet-3.5) and the worst is 48.67% (GPT-4o).

Two circles overlapping or touching. Over 672 images of two equal-sized circles that are overlapping, tangent, or disjoint (with variations in orientation and size), the best accuracy is 92.78% (Gemini-1.5) and the worst accuracy is 72.69% (GPT-4o, again). Further, performance tends to degrade when two circles are close together.
Circled letter in a string. A red oval is superimposed on one of the letters in a string. The authors test three strings – Acknowledgement, Subdermatoglyphic, and a random string tHyUiKaRbNqWeOpXcZvM. Gemini-1.5 (92.81% accuracy) and Sonnet-3.5 (89.22%) outperform GPT-4o and Sonnet-3 by nearly 20 points. Except for GPT-4o, all models perform slightly better on the two English words than the random string, suggesting that knowing the word might help VLMs make better educated guesses.
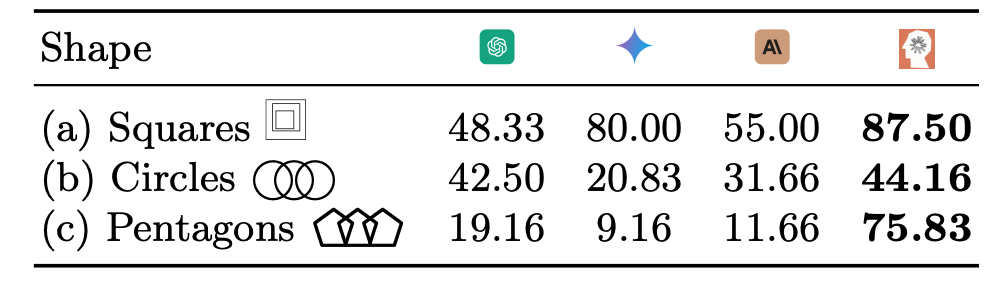
Counting overlapping shapes. N overlapping, same-sized circles (N=5,6,7,8,9) are arranged in two rows like the Olympic logo. Performance ranges from 20.83% (Gemini-1.5) to 44.16% (Sonnet-3.5). Repeating the same arrangement of pentagons yields more disparate performances from 9.16% (Gemini-1.5) to 75.83% (Sonnet-3.5). All four models are 100% accurate in counting 5 circles while performing poorly (except Sonnet-3.5) on 5 pentagons.
Counting nested squares. 2 to 5 squares are nested such that each shape is entirely inside another. Sonnet-3.5 again has the best accuracy of 87.5%. GPT-4o and Sonnet-3 struggle to count even when there are only 2 or 3 squares.
Counting the rows and columns of a grid. VLMs struggle to count the exact number of rows and columns in an empty grid, where the best model (Sonnet-3.5) has 59.84% accuracy and the rest have 25-26% accuracy. However, adding a single word to each cell significantly improves performance for all models. For example, GPT-4o's accuracy more than doubles from 26% to 53%.
Following single-colored paths. The final task asks models to count the number of unique-color paths between two given stations in a simplified subway map. "Shockingly," the authors find that no model reaches 100% accuracy even when there is only one path between two stations. Most VLMs perform worse as map complexity increases.

Overall, the BlindTest benchmark provides the first low-level, visual sanity check for VLMs. Their underwhelming performance on these simple (for humans) tasks that require zero prior knowledge are counterintuitive given their impressive performance on existing vision benchmarks, which have a data leakage problem. Addressing these limitations of VLMs is likely a non-trivial challenge and may help solve other known visual shortcomings of multimodal models such as understanding the orientation of an object.
New from the Gradient
David Pfau: Manifold Factorization and AI for Science

Dan Hart and Michelle Michael: Bringing AI to Students in New South Wales

Other Things That Caught Our Eyes
News
OpenAI illegally barred staff from airing safety risks, whistleblowers say
Whistleblowers at OpenAI have filed a complaint with the Securities and Exchange Commission (SEC), alleging that the company illegally prevented employees from raising safety concerns about its AI technology. The whistleblowers claim that OpenAI issued overly restrictive employment, severance, and nondisclosure agreements that could have penalized workers who reported concerns to federal regulators. These agreements violated federal laws protecting whistleblowers and their right to anonymously disclose damning information about their company. The complaint comes amid concerns that OpenAI prioritizes profit over safety in developing its technology. The SEC has not yet confirmed whether an investigation has been launched.
Data workers detail exploitation by tech industry in DAIR report
A new report by the Data Workers' Inquiry, a collaboration between AI ethics research group DAIR and TU Berlin, sheds light on the exploitation of data workers in the tech industry. The report highlights the hidden labor of data work, such as moderation and annotation, which is often outsourced to poorer countries where workers are paid significantly less than their American or European counterparts. The conditions of this work, although not physically dangerous, can be psychologically damaging. The reports, which are largely anecdotal, provide firsthand accounts of the challenges faced by data workers, including mental health issues and a lack of support from employers. The report emphasizes the need for companies to address the exploitation of data workers and calls for further research on the topic.
New York Times Experiments With a New Headline Writer: OpenAI
The New York Times has been experimenting with OpenAI's generative AI technology to develop a tool that can generate headlines for articles and apply the newspaper's style guide. The leaked code revealed that the Times used OpenAI to create a headline writer that could potentially replace editors. While the project was only an early experiment and not used by the newsroom, it highlights the increasing use of AI in newsrooms. However, there are concerns that AI could lead to further job losses for journalists. The Times is currently involved in a lawsuit against OpenAI and Microsoft for alleged copyright infringement.
Deepfake Creators Are Revictimizing GirlsDoPorn Sex Trafficking Survivors
Deepfake creators have reached a new low by using videos of sex trafficking victims as the basis for nonconsensual deepfake pornography. An account on a deepfake sexual abuse website posted 12 celebrity videos that were created using footage from GirlsDoPorn, a sex trafficking operation. The videos, which were up to 21 minutes long, had celebrity faces added using AI. Deepfake technology has become increasingly realistic and accessible, leading to the proliferation of websites and apps designed for deepfake sexual abuse, while laws to protect victims and limit the use of these tools are lagging. Legal proceedings against the creators of GirlsDoPorn and affiliated individuals are ongoing, with survivors being awarded damages and copyright ownership of the videos.
The A.I. Boom Has an Unlikely Early Winner: Wonky Consultants
The rise of AI has created a demand for consultants who can help businesses understand and implement this technology. Companies like Boston Consulting Group and McKinsey & Company are experiencing a surge in revenue and hiring as they assist businesses in navigating the implications of AI and how it can benefit their operations. For example, Reckitt Benckiser, the maker of Lysol and Mucinex, sought the expertise of Boston Consulting Group to explore how AI could be applied to their business.
Humane execs leave company to found AI fact-checking startup
Former employees of Humane, a struggling AI hardware company, have left to start their own startup called Infactory. Infactory is a fact-checking search engine that aims to provide accurate information by pulling data directly from trusted sources, rather than relying on generative AI services. The founders, Brooke Hartley Moy and Ken Kocienda, emphasize the importance of using AI selectively and focusing on computational and factual data. Infactory plans to target enterprise customers, such as newsrooms and research facilities, and will initially focus on data-related subjects. The startup has raised pre-seed funding and will be seeking seed funding in the next six to 18 months. Despite their departure from Humane, the founders deny that their decision was a direct result of the company's struggles. Infactory is set to launch in a few months.
The AI-focused COPIED Act would make removing digital watermarks illegal
A new bill called the Content Origin Protection and Integrity from Edited and Deepfaked Media Act (COPIED Act) has been introduced by a bipartisan group of senators — it aims to authenticate and detect artificial intelligence-generated content, protecting journalists and artists from having their work used without permission. The Act directs the National Institute of Standards and Technology (NIST) to create standards and guidelines for proving the origin of content and detecting synthetic content through watermarking. It also requires AI tools to allow users to attach information about the origin of creative or journalistic content and prohibits the removal of this information. Content owners can sue companies that use their materials without permission or tamper with authentication markers. The bill has received support from publishing and artists' groups.
Why The Atlantic signed a deal with OpenAI
The Atlantic has signed a deal with OpenAI, allowing the AI company to use The Atlantic's archives as training data. The CEO of The Atlantic, Nicholas Thompson, explains that the deal provides revenue and a potential traffic source for the magazine. The deal includes three main components: allowing OpenAI to train on The Atlantic's data for two years, a product partnership where OpenAI provides credits and potential engineering support, and the inclusion of The Atlantic in OpenAI's search product. The goal of the deal is to shape the future of AI and ensure that journalists and media companies are paid for their work.
AI Has Become a Technology of Faith
The article discusses the launch of a new company called Thrive AI Health, which aims to bring OpenAI's technology into the healthcare industry. The company plans to develop a hyper-personalized AI health coach that will generate personalized insights based on a user's biometric and health data. The article raises concerns about privacy and the potential misuse of personal health information. The founders of Thrive AI Health argue that people are willing to share personal details with AI language models and that the technology can offer behavioral solutions to improve health outcomes. However, the article questions the feasibility and potential risks of such a product.
China's openKylin operating system, an open-source OS based on Linux, has released a new version that is deeply integrated with AI. The OS features support for on-device LLMs, an AI assistant, and text-to-image generation. The aim is to boost productivity and user experience for those using domestic operating systems. AI PCs, equipped with advanced processors capable of running generative AI tasks locally, have gained popularity in China. Lenovo sees China as a unique market for AI PCs due to data-localization requirements. OpenKylin is part of China's effort to decrease dependence on foreign operating systems. However, Windows remains the dominant OS in China with nearly 80% of the market.
Microsoft and Apple ditch OpenAI board seats amid regulatory scrutiny
Microsoft and Apple have both stepped down from their board seats at OpenAI, a nonprofit organization focused on artificial intelligence (AI) research. Microsoft had secured a non-voting seat less than eight months ago, but concerns over antitrust issues have led to the decision. OpenAI will now adopt a new approach to engage with strategic partners and investors, including Microsoft and Apple, through regular stakeholder meetings. The move comes as UK and EU regulators are investigating Microsoft's partnership with OpenAI, along with other AI deals involving major tech companies. Microsoft has invested over $10 billion in OpenAI, making it the exclusive cloud partner and benefiting from OpenAI's AI models to enhance its own products and services.
AI Needs Copper. It Just Helped to Find Millions of Tons of It.
KoBold Metals, a company in California, has used AI-driven technology to discover a large copper deposit in Zambia. The company estimates that the mine could produce at least 300,000 tons of copper per year, worth billions of dollars annually. An independent assessment largely corroborated the size of the deposit. KoBold expects the value of the mine to increase as they continue to map the full extent of the highest-grade ore.
Japan’s Defense Ministry unveils first basic policy on use of AI
The Defense Ministry of Japan has released its first basic policy on the use of AI in order to address concerns about recruitment and the need to utilize personnel more efficiently. With a declining and aging population, Japan aims to leverage AI to overcome these challenges and keep up with China and the United States in terms of military applications of the technology. The policy highlights the potential of AI to alleviate manpower shortages and enhance the capabilities of the Self-Defense Forces. Japan’s move reflects its recognition of the importance of AI in maintaining its technological edge and addressing demographic issues.
China’s AI competition deepens as SenseTime, Alibaba claim progress at AI show
Chinese AI companies SenseTime and Alibaba showcased their progress in developing LLMs at the World Artificial Intelligence Conference (WAIC) in Shanghai. SenseTime released its latest foundational model, SenseNova 5.5, which boasts a 30% improvement in performance compared to the previous version. SenseTime claimed that SenseNova 5.5 outperforms GPT-4o in five out of eight key metrics. Alibaba's cloud computing unit highlighted the growth of its Tongyi Qianwen LLMs, with downloads doubling to over 20 million in the past two months. The number of customers served by Alibaba Cloud Model Studio also increased by over 150% to 230,000. The competition in the Chinese LLM market is intensifying, with only a few companies predicted to dominate in the future.
Papers
Our recs:
MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
Me, Myself, and AI: The Situational Awareness Dataset for LLMs
Not a paper, but a report: Othello-GPT learned a bag of heuristics
Selective Perspectives: A Content Analysis of The New York Times’ Reporting on AI
Faux Polyglot: A Study on Information Disparity in Multilingual LLMs
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!