

Update #78: Accelerating Candy Crush Development and Neural Network Flexibility
Activision Blizzard scientists discuss AI's role in Candy Crush; researchers study neural networks' flexibility in fitting data.



Welcome to the 78th update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter. Our newsletters run long, so you’ll need to view this post on Substack to see everything!
Editor Notes
Good morning. Not a terrible amount to call out this week. If you’re in the states, I think other events have seized everyone’s attention recently.
As always, if you want to write with us, send a pitch using this form.
News Highlight: How AI is accelerating Candy Crush development
Summary

In a recent interview with gamesindustry.biz, the leads of Activision Blizzard King’s (AI) AI Labs discussed the role that AI has played throughout the development of “Candy Crush”, one of their largest and most successful games. The scientists discuss their goals in building a playtesting bot as well as its usage by developers to increase both the quality and speed of level development. Additionally, the researchers at King emphasize the importance of humans working in synch with these AI tools rather than being replaced by them. This is a welcome contrast to the dominant narrative of AI in gaming which typically consists of either the theft of artists’ intellectual property by generative models or further weakening the job market for games and software developers.
Overview
Since April 2012, developers at ABK have released an average of over 4 new Candy Crush levels every day for the past 12 years for a total of almost 17 thousand unique levels. This volume of content is practically unprecedented in the industry and much of its recent throughput could be attributed to ABK’s acquisition of the AI firm Peltarion in 2022. After the acquisition, developers from Peltarion began to flesh out leadership positions in King’s AI labs and develop plans for playtesting bots. By training neural networks using nothing but their players' game data, the scientists at King’s AI labs were able to build playtesting bots at a variety of human skill levels. These bots are used by the developers at King to automatically detect bugs before release and helped them reduce the number of manual tweaks by over 95%. Additionally, these bots can be used by game designers to understand the appropriateness of the intended difficulty of the levels as well as the impact of shuffle (randomization), a core gameplay mechanic of candy crush. By investing in these AI development tools, game designers and quality assurance (QA) workers at ABK have been able to supercharge their outputs, developing more levels faster, as well as better understanding how their players will interact with a level (and its difficulty beforehand) .
While some may see these AI tools as a path towards generating more things faster and reducing pesky labor costs, the developers at ABK consistently emphasized the impact and importance of the human designers working in tandem with AI tools. While these AI solutions may automate away some of tasks that are typical of designers and QA workers, it can free their responsibilities from some of the more menial, repetitive, and tedious tasks so that they can focus on more meaningful and high impact tasks. Ultimately, the designers (and other humans working in game development) are the ones who know what “fun” really is and there is no expectation that generative AI will ever be able to replicate or develop that kind of intuitive sense.
Our Take
When I first started working gaming, I got an inside look at how playtesting bots can supercharge development and improve the quality of work for all kinds of game developers (designers, QA, data scientists, product leads etc). Seeing that body of work being pursued by other gaming companies has me super enthused. However, as excited as I am by the end results, I wish the scientists ABK shared more details on the inner workings of their models. While I am sure there is a businessperson making a case to not reveal any trade secrets, it would have been nice to get really any details on how they trained and tested their models. Are they using reinforcement learning? What about transformers? Hopefully there will be a GDC talk or paper coming soon where we could learn more! - Justin
Research Highlight: Just How Flexible are Neural Networks in Practice?

Summary
Neural networks are commonly believed to fit training sets with as many samples as they have parameters. However, the effectiveness of this fitting depends significantly on the training procedures such as the optimizer or regularizer and the specific architecture used. In this work, the authors study how flexible neural networks truly are when it comes to fitting data. The key findings are as follows:
Conventional optimizers typically locate minima where models fit far fewer samples than the models parameter count;
Convolutional neural networks (CNNs) surpass Multi-Layer Perceptrons (MLPs) and Vision Transformers (ViTs) in parameter efficiency with randomly labeled data;
Stochastic gradient descent finds solutions that fit more training data than full-batch gradient descent;
ReLU activation functions enhance data fitting capabilities by mitigating vanishing and exploding gradients.
Overview
It is widely believed that a neural network can fit a training set with at least as many samples as it has parameters, which forms the basis for understanding overparameterized and underparameterized models. Despite the theoretical guarantees on neural networks being universal function approximators, the models we train in practice have limited capacities and often lead to suboptimal local minima during training, constrained by the methods we use. Their flexibility to fit data varies based on a number of factors such as the characteristics of the data, the architecture and size of the model or the optimizer used. In the recent paper ‘Just How Flexible are Neural Networks in Practice?’, the authors empirically study this relationship.
To quantify this flexibility of a model, the authors use Effective Model Complexity (EMC) metric, which estimates the maximum number of samples a model can perfectly fit. The EMC is determined through an iterative training process, where the model is trained on progressively larger datasets until it fails to achieve 100% accuracy. The study uses different initializations and sample subsets in each iteration to ensure fairness in evaluation. An important factor when studying fitting of a model to data is also to ensure the model is not under trained on a given data. The authors verify this by checking for the absence of negative singular values in the Hessian loss.
To comprehensively dissect the factors influencing neural network flexibility, a variety of models with varying depths and widths such as Multi-Layer Perceptrons (MLPs), Convolutional neural networks (CNNs) , EfficientNet, and Vision Transformers (ViTs) on a range of datasets including ImageNet. Multiple optimizers are also used to account for the effect of stochasticity and preconditioning on the minima. Below we analyze some key empirically established relationships and trends across different training or dataset choices and model fitting.
Effect of Dataset

As shown in the figure above, the findings indicate considerable differences in the Effective Model Complexity (EMC) of networks depending on the type of data used for training. For example, networks trained with tabular data (Income, Forest, Covertype) demonstrate greater capacity. Further for image classification datasets, there is a notable correlation between test accuracy and EMC.
Optimizers and Model architectures
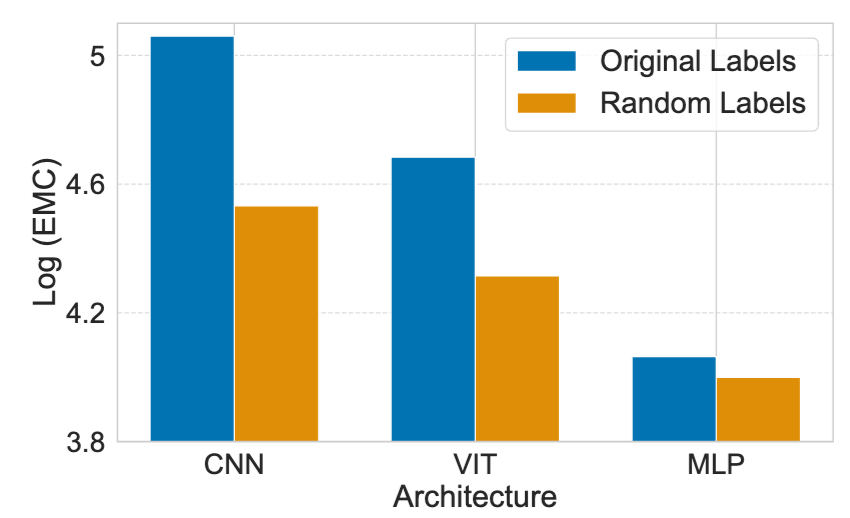
As seen from the figure above (left), CNNs demonstrate greater parameter efficiency compared to MLPs and ViTs, even when trained on images with random labels. This efficiency cannot be explained by their inductive bias, which suggests that CNNs generalize effectively due to their preference for labeling functions that exhibit specific symmetries. It is commonly believed that stochastic training acts as a regularizer. However, as shown in the Figure above (right), SGD tends to locate minima that fit more training data compared to full-batch gradient descent.
Generalization

One can observe from the figure above that the disparity in a model's ability to fit correctly versus incorrectly labeled samples serves as a predictor of its generalization capabilities. Specifically, models that exhibit strong generalization can accommodate significantly more correctly labeled samples than randomly labeled ones, indicating their ability to generalize effectively within their training set.
Our Take
We often assess whether a neural network is overparameterized or underparameterized by counting its parameters. In practice, the amount of data a network can fit provides a more accurate measure of its capacity. I find this paper interesting since it provides empirical evidence on the interplay between model architecture, training procedures, and data characteristics which is complementary to the theoretical guarantees in this space. Further, they indicate that neural networks exhibit parameter inefficiency, and might help to develop new parameterizations that could enhance their overall efficiency. However, I would like to see more apples to apples comparison in certain ablations such as comparing performance across datasets like CIFAR10, ImageNet despite them having different classes and characteristics.
– Sharut
New from the Gradient
Kristin Lauter: Private AI, Homomorphic Encryption, and AI for Cryptography

Sergiy Nesterenko: Automating Circuit Board Design

Other Things That Caught Our Eyes
News
ChatGPT is hallucinating fake links to its news partners’ biggest investigations
ChatGPT is generating fake URLs and directing users to 404 errors instead of real article pages for several major news media companies that have partnered with OpenAI. These publications include The Associated Press, The Wall Street Journal, The Financial Times, The Times, Le Monde, El País, The Atlantic, The Verge, Vox, and Politico. Despite the licensing deals stating that ChatGPT will produce attributed summaries and link to the publications' websites, the chatbot is currently unable to reliably link to these partner publications' most noteworthy stories. OpenAI has acknowledged that the citation features promised in the licensing contracts are still in development and not yet available in ChatGPT. The article highlights the concern among journalists about ChatGPT's potential as a search tool and the need for transparency and protections for the integrity of journalism.
McDonald's is removing its AI drive-thru voice-ordering system, called the Automated Order Taker, from over 100 restaurants after videos showcasing flaws with the technology went viral. The fast-food chain collaborated with IBM in 2021 to develop and deploy the AI software. However, the technology did not meet expectations, leading to its removal. This decision marks the end of a test period conducted with IBM. The mishaps with the AI system highlight that generative AI is not yet advanced enough to fully replace human jobs in industries like restaurants.
How This Real Image Won an AI Photo Competition
Photographer and writer Miles Astray submitted a photograph titled "F L A M I N G O N E" to the 1839 Awards, a photography competition with a category for images created by artificial intelligence (AI). The image appeared to show a flamingo without its head and neck, but it was actually a real photograph taken by Astray. The photograph won the People's Vote Award before being disqualified. Astray wanted to show that nature can still outdo machines in terms of creativity and beauty. He also highlighted the dangers of AI-generated content being indistinguishable from real content. Astray believes that tagging AI-generated images and videos and educating people to be critical thinkers can help address the potential for AI-generated misinformation.
Microsoft insiders have shared their thoughts on the company's AI future and its partnership with OpenAI. While there is optimism about Microsoft's ability to improve its AI offerings and leverage its existing trust with customers, there are concerns about the value of new AI services for corporate customers and the resentment caused by the OpenAI partnership. Microsoft's Copilot offerings, based on OpenAI's GPT models, aim to provide automated support for various tasks. However, there are mixed early results and a race to add value before customers question the return on investment. Microsoft is also facing pressure from OpenAI's move into the business market.
Waymo One is now open to everyone in San Francisco
Waymo, the autonomous vehicle company, has announced that its Waymo One ride-hailing service is now available to everyone in San Francisco. Waymo has been operating in the city for several years, gradually scaling its service. The Waymo One service offers safe, sustainable, and reliable transportation, with about 30% of rides being to local businesses. Waymo's fleet is all-electric and sources 100% renewable energy. The service has helped reduce carbon emissions and improve personal safety for riders. Waymo also offers a unique way for tourists to experience the city. With a focus on safety, Waymo has a track record of over 20 million rider-only miles and is committed to working with city and state officials to ensure responsible growth.
Training AI music models is about to get very expensive
The article discusses the potential legal implications and financial consequences for AI music companies that use copyrighted works to train their models. Record labels have filed lawsuits against these companies, alleging that their models imitate copyrighted works too closely. The outcomes of the lawsuits could range from the court finding in favor of the AI startups, determining that they did not violate fair use, to the court finding fault on both the training and output sides of the AI models, resulting in potential damages for infringement. The article also mentions the possibility of a future licensing market for AI music models, similar to what has already happened with text generators. However, licensing deals could be costly, potentially limiting access to powerful music models to those with significant financial resources. The article concludes by noting that training AI models exclusively on public domain music would be challenging and result in models that are far less impressive than what exists today.
MIT robotics pioneer Rodney Brooks thinks people are vastly overestimating generative AI
Rodney Brooks, a robotics pioneer and co-founder of companies like Rethink Robotics and iRobot, believes that people are overestimating the capabilities of generative AI. While he acknowledges that generative AI is impressive technology, he argues that it cannot perform all tasks that humans can and that humans tend to overestimate its abilities. Brooks emphasizes that generative AI is not human-like and should not be assigned human capabilities. He provides an example of a warehouse robotics system, where using generative AI to tell the robots where to go would actually slow things down compared to connecting them to a stream of data from the warehouse management software. Brooks also highlights the importance of solving solvable problems and designing robots for practical purposes rather than building human-like robots. He believes in making technology accessible and purpose-built, and he cautions against the mistaken belief that technology always grows exponentially. While he sees potential for LLMs in domestic robots for specific tasks, he emphasizes that the problem lies in control theory and math optimization, not in language capabilities.
Here comes a Meta Ray-Bans challenger with ChatGPT-4o and a camera
Solos, a competitor to Ray-Ban Meta Smart Glasses, plans to release a camera-equipped version called Solos AirGo Vision later this year. These smart glasses will feature OpenAI's new GPT-4o AI model, allowing the camera to recognize objects and answer questions about what the wearer sees. The glasses will have a swappable frame system, allowing users to switch out the camera for different looks or sun shades. The Vision will also include notification LEDs for incoming calls or emails and can be integrated with Google Gemini and Anthropic's Claude AI models. While the price and release date for the AirGo Vision have not been announced, they are expected to cost more than $249.99, the price of the camera-less version. The Ray-Ban Meta Smart Glasses currently start at $299.
Y Combinator rallies startups against California’s AI safety bill
Y Combinator and several AI startups have expressed opposition to California's Senate Bill 1047, which aims to regulate the development of AI systems. The bill would require developers of large AI models to take precautions such as safety testing, implementing safeguards, and post-deployment monitoring. Y Combinator argues that the responsibility for misuse should lie with those who abuse the tools, not the developers. They believe that holding developers liable for unintended misuse could stifle innovation and discourage investment in AI research. The letter also criticizes other aspects of the bill, including the proposed requirement for a 'kill switch' to deactivate AI models. Y Combinator claims this would impact the development of open-source AI.
Google is bringing Gemini access to teens using their school accounts
Google is expanding access to Gemini to teen students using their school accounts. This move aims to prepare students for a future where generative AI is prevalent. Gemini provides real-time feedback to help students learn more confidently. Google assures that it will not use data from student chats to train its AI models and has implemented guardrails to prevent inappropriate responses. The company recommends that teens use the double-check feature to develop critical thinking skills. Gemini will be available in English in over 100 countries and will be off by default for teens until administrators enable it. Additionally, Google is launching the Read Along in Classroom feature globally, which helps students improve reading skills with real-time support. Educators will have access to tools for creating, managing, and sharing interactive lessons, as well as the ability to mark assignments and perform bulk scoring actions.
Stability AI lands a lifeline from Sean Parker, Greycroft
Stability AI has secured new funding from investors including Sean Parker, Greycroft, and Coatue Management. The company has not disclosed the amount raised. Stability AI has faced financial difficulties, with unpaid cloud bills and a lower valuation for the startup. However, the new investors have committed $80 million to take over Stability and have negotiated debt forgiveness and the release from future obligations. Stability AI plans to focus on growing its managed image, video, and audio pipelines, building custom enterprise models and content production tools, and delivering APIs for consumer apps. The company aims to remain committed to open-source principles and continue developing powerful generative AI models.
OpenAI buys a remote collaboration platform
OpenAI has acquired Multi, a startup that developed a video-first collaboration platform for remote teams. The deal is primarily an acqui-hire, with most of Multi's team joining OpenAI. Multi offered features such as collaborative screen sharing, customizable shortcuts, and automatic deep links for code, designs, and documents. This acquisition aligns with OpenAI's strategy of investing in enterprise solutions, as they have been focusing on developing AI-powered tools for businesses. OpenAI's revenue is projected to exceed $3.4 billion this year. The acquisition of Multi suggests that OpenAI may expand its offerings to include videoconferencing and remote collaboration capabilities in the future.
YouTube is trying to make AI music deals with major record labels
YouTube is seeking to make deals with major record labels, including Universal Music Group, Sony Music Entertainment, and Warner Records, to license their songs and train its AI music tools. The platform aims to use the licensed music to develop new AI tools that will be launched later this year. YouTube has not disclosed the exact fee it is willing to pay for these licenses, but it is expected to be a one-time payment rather than a royalty-based arrangement. However, convincing both artists and labels may be a challenge, as Sony Music has warned against unauthorized use of its content, and UMG has previously pulled its music catalog from TikTok due to concerns about AI-generated music. In January, over 200 artists called for tech companies to stop using AI to infringe upon the rights of human artists.
Opera’s browser adds AI-powered image generation and better multimedia controls
Opera is releasing the second version of Opera One in developer beta, featuring new multimedia controls, split tabs, and AI capabilities. The new version allows users to have floating multimedia controls that can be resized and match the browser's theme. It also introduces split tab windows, enabling users to work on two web pages simultaneously. Additionally, Opera One R2 includes AI features such as a page context mode that allows users to ask questions about a web page and AI-powered summarization. Opera plans to release Opera One R2 to a wider user base later this year.
Papers
Once again, a list:
Intrinsic Evaluation of Unlearning Using Parametric Knowledge Traces
Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data
Linguistic inputs must be syntactically parsable to fully engage the language network
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!
A general comment on the 1839 Awards. I've noticed a trend in commentary on AI developments - not this Substack, but in general - to move goalposts as a form of, as the kids say, "cope." People will celebrate a human tricking human judges in an AI image generation competition with a "real" image, or say that current AI is garbage and overhyped because it cannot meet one specialized use case that, if they understood how the systems work, they should not expect it to be capable of. People are still joking that image generators cannot draw hands at all, but if you use a paid image model like Midjourney you know that is a solved problem - in the rare case that a human hand is not rendered correctly, a user can fix it in seconds with inpainting. A good rule of thumb: whatever media is telling you an AI system "cannot" do, check on the frontier paid models, and in the open source literature: chances are someone has worked out how to do just the thing you said is impossible (though the real question is whether it can be done consistently at scale).
I definitely believe that businesses and VCs have every motive to overhype AI, and that they are, dishonestly or honestly, doing so (it is easier to hype what you actually believe). But if the hype is "artificial general intelligence by 2030," the alternative is not "no progress at all from now to 2030." it's a vast range of possible futures, not one of which is that AI systems become less capable than they are today. The transformation doesn't come when the AI is, at economically valuable task X, better than the best human being, but when it's better than 80% of all human beings, while being orders of magnitude faster and less expensive.