

Update #77: AI-Generated News Cannibalizes Journalism and Open-Endedness for Superintelligence
BNN Breaking turns out to be an AI chop shop; DeepMind argues that open-endedness is essential for "superintelligent" systems.



Welcome to the 77th update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter. Our newsletters run long, so you’ll need to view this post on Substack to see everything!
Editor Notes
Good morning.
Leopold Aschenbrenner is ubiquitous and OpenAI has a deal with Apple.
Our highlights today have absolutely nothing to do with either of these items.
A few great pieces from around town:
As always, if you want to write with us, send a pitch using this form.
News Highlight: AI-Paraphrased News Cannibalizes Original Journalism

Summary
BNN Breaking, a site that churned out AI-paraphrased versions of news articles, shut down after two years as numerous complaints about its content stealing and fabrication came to light. The dubious news outlet had a licensing agreement with Microsoft, which owns MSN. Its articles were also picked up by prominent Western outlets such as The Washington Post and The Guardian and were frequently surfaced on Google News. Individuals suffered reputation damage due to the falsehoods BNN published while local journalism organizations lost already scarce revenue to BNN's plagiarism.
Overview
As detailed in a recent New York Times article, BNN Breaking, which looked like a reliable news site, was in reality an AI chop shop. It was founded in Hong Kong by Gurbaksh Chahal, a serial entrepreneur who had a criminal history of domestic violence, and employed dozens of freelance journalists based in countries like Pakistan, Egypt, and Nigeria. Employees uploaded articles from other news sites to a generative AI tool and were asked to manually "validate" the paraphrased results. Eventually, the tool churned out hundreds or even thousands of stories a day and randomly assigned journalists' bylines.
One of the BNN articles promoted on MSN.com falsely associated Irish DJ and talk-show host Dave Fanning, whose photo was featured, with a different Irish broadcaster accused of sexual misconduct. The name of the broadcaster facing trial was not released in the original article and the AI "presumably paired the text with a generic photo of a 'prominent Irish broadcaster'", according to the India-based journalist whose byline was on the story. Fanning filed a defamation lawsuit against Microsoft and BNN Breaking.
BNN's operations also harm smaller, local news outlets who already struggle to get a share of advertising dollars to support their work. For example, its AI-rewritten version of an original article published by South African outlet Limpopo Mirror ranked higher in Google search than the genuine version. Only after Google rolled out an update targeting "spammy" sites in March did BNN's stories stop showing up in search results.
Our Take
I was quite shocked that a source that seems so obviously suspicious (perhaps only in hindsight) gained as much traction as it did and lasted as long as two years. The NYT article mentions that content curation on MSN.com was increasingly carried out by AI instead of human editors, and I can't help thinking about the layers of algorithmic decision making that shapes what we see on a daily basis, from what is surfaced in search to the actual content. Does AI have a bias for AI-generated content?
What makes BNN intriguing, and what I think partially contributed to its success before its downfall, was that real human journalists were involved, and at least some of them bought into the promise of a "revolution in the journalism industry" before they realized their own reputation and integrity were being jeopardized. At the same time, BNN's workforce — a scattered network of relatively inexperienced journalists based in developing countries — is reminiscent of the kind of labor exploitation familiar to tech. How big is the impact of AI pink slime and AI-generated news that appear to be of high quality, in a world where human writers are wrongly accused of relying on AI and are being replaced by AI anyway? I'd like to think we as consumers of information all have something within our control that we can do in the service of truth.
– Jaymee
I want to echo and spend a minute on Jaymee’s last point: that we have something within our control that we can do in the service of truth, even as consumers. I think often of L.M. Sacasas’s point—made by others as well, but especially well by him—that we can conflate what feels technologically “advanced” for what is best for human beings as we are. This manifests in different ways, and BNN provides perhaps one example of when we believe too deeply in the logic of inevitability. News organizations have struggled with these questions and laid out guidelines and standards for the use of AI in the newsroom, but there clearly isn’t something like “societal agreement” on what’s acceptable and good for us. Will we ever make different decisions?
—Daniel
Research Highlight: Open-Endedness is Essential for Artificial SuperIntelligence
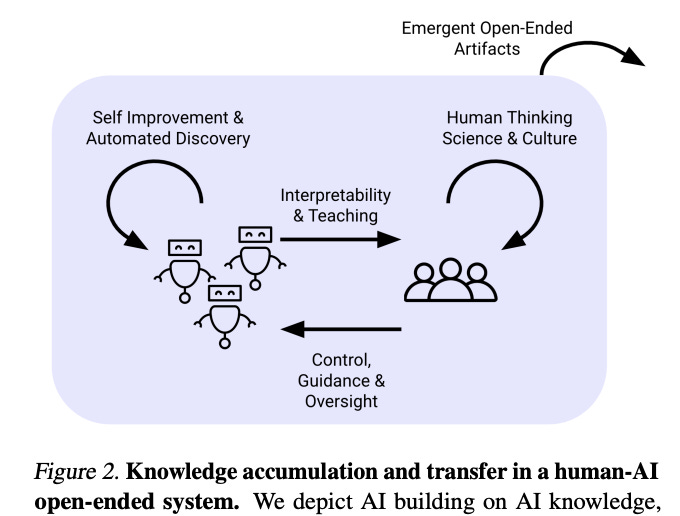
Summary
This position paper out of Google DeepMind formalizes the concept of an “open-ended” AI system and argues that achieving Artificial Superhuman Intelligence (ASI) will require the development of such systems. The authors propose an observer-dependent and temporal definition that a system is “open-ended” so long as the sequence of artifacts it produces is both learnable and novel to the observer. Learnable artifacts are those that make future artifacts more predictable and novel artifacts are those that are unpredictable given previously generated artifacts. Novelty guarantees information gain while learnability ensures that the information gain is in some sense “meaningful” and that the artifact is interesting to the observer. They argue that we have yet to develop any general “open-ended” systems, describe how their framework maps to existing SoTA AI systems, and offer four overlapping paths towards open-ended foundation models.
Overview
The authors begin by claiming that because:
“open-ended invention is the mechanism by which human individuals and society at large accumulates new knowledge and technology” and,
an ASI could, by definition, perform a wide range of tasks at a level beyond any human’s capability,
It must follow that open-endedness is an essential property for ASI. Here “essential” means something along the lines of necessary but not sufficient. They describe an open-ended system as “an autonomous system [that] self-improves towards increasingly creative and diverse discoveries without end.”
In their view, scaling foundation models alone won’t get us open-endedness. They note the limited supply of high-quality textual and visual data, and conjecture that “the trend of improving foundation models trained on passive data by scaling alone will soon plateau”. Something more targeted towards open-endedness is needed to discover new knowledge. “Open-ended” is pretty hand-wavy, so in order to catalyze research into open-endedness by providing clarity, they define an open-ended system as one that produces novel and learnable artifacts, then formalize these concepts in the following way:

With this setup, they define the system as novel if the artifacts being generated become increasingly unpredictable with respect to the observer’s model at some fixed time t:
And the system is learnable if conditioning on a longer history makes future artifacts more predictable in the sense of a lower loss value:
Novelty and learnability are necessary in tandem: without novelty, the observer is able to predict all the artifacts and there is no new information being gained; without learnability, the observer can’t make tractable process (the authors give the example of a TV-set that generates white noise—endlessly novel in the sense of the unpredictability of its aleatoric uncertainty but not interesting or learnable in any sense.
This definition is very general by design. Leaving the loss metric $\ell(t,T)$ undefined allows leeway in measuring the “interestingness” of artifacts. And by incorporating time and making novelty and learnability observer-dependent, this definition allows for the possibility of systems that are only temporarily open-ended or only open-ended to certain observers.
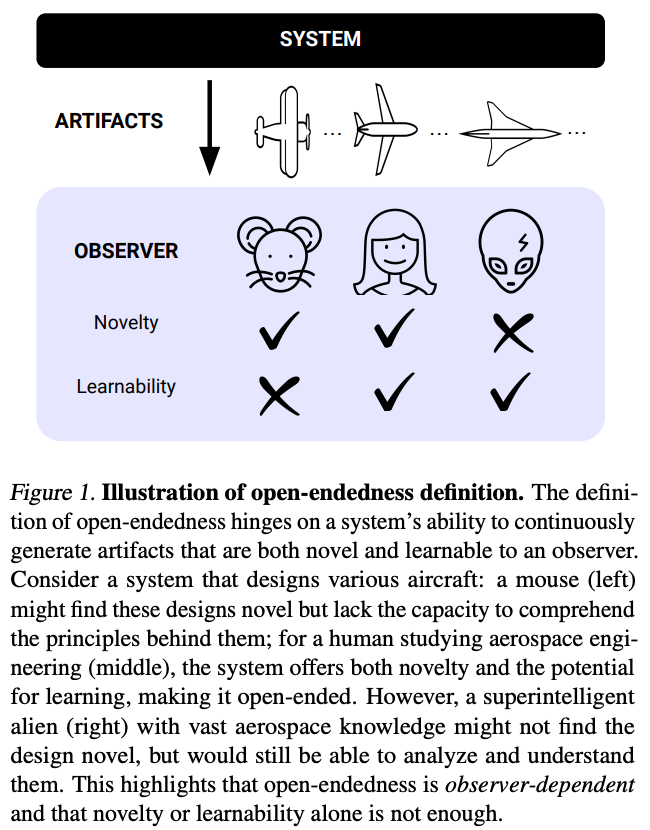
The authors relate how their definition of open-endedness maps to existing AI systems. They highlight three archetypal AI systems that do exhibit open-endedness but only in a narrow domain:
Systems that augment RL with self-play (e.g. AlphaGo, AlphaGo and similar systems for StarCraft, Stratego, DotA, and Diplomacy)
Systems that use unsupervised environment design (UED) to establish an automatic curriculum (e.g. AdA, a large-scale agent capable of solving tasks in a 3d environment)
Systems that employ evolutionary algorithms to train agents (e.g. Paired Open-Ended Trailblazing (POET), which trains a population of agents across an evolving range of environments)
And what about current SoTA foundation models? The authors classify these as general but not open-ended. They argue that since these models are trained on fixed datasets, it follows that if the distribution of this data is learnable then these models cannot be endlessly novel. Further the distribution of this data must be learnable because the foundation model learned it in the first place!
But all hope is not lost for foundation models—the authors contend that augmenting foundation models with open-endedness is a viable route toward ASI. They offer four overlapping paths to such open-ended foundation models:
RL: RL is fundamental to the existing narrow open-ended AI systems and there is already promising research into using RL on top of foundation models. In particular foundation models could overcome the difficulty of guiding RL algos in high-dimensional domains by serving as a sort of proxy observer (e.g. Voyager, Motif, OMNI)
Self-Improvement: self-improvement loops wherein the model critiques itself that hopefully allow the system to “generate new knowledge…beyond the human curated training data” (e.g. Anthropic’s Constitutional AI, OpenAI’s work on self-critiquing models, SELF-INSTRUCT)
Task generation: “adapting the difficulty of tasks to an agent’s capability so that they remain forever challenging yet learnable” (e.g. WebArena, Interactive Real World Simulators)
Evolutionary Algorithms: foundation models can be used to generate selection and mutation operators (e.g. ELM, 2024 survey paper of evolutionary algos for LLMs)
Our Take
Generative AI—in particular open-ended GenAI or GenAI for discovery—surfaces a fascinating tension between novel outputs and coherent outputs. I think this tension tracks well with the dual requirements of novelty and learnability introduced in this paper. In some sense it feels misguided to expect novelty from a system that’s trained with the sole objective of minimizing surprise. A good illustration of this tension is decoding open-ended text from an LLM. Simply generating the most-likely next token or using some sort of greedy beam search is a bad strategy! It tends to yield uninteresting and repetitive outputs. I love this plot from Holtzman et al. 2020 comparing beam search next-token probabilities to the probabilities the same LLM assigns to a human-generated text (one that it hasn’t seen during training):
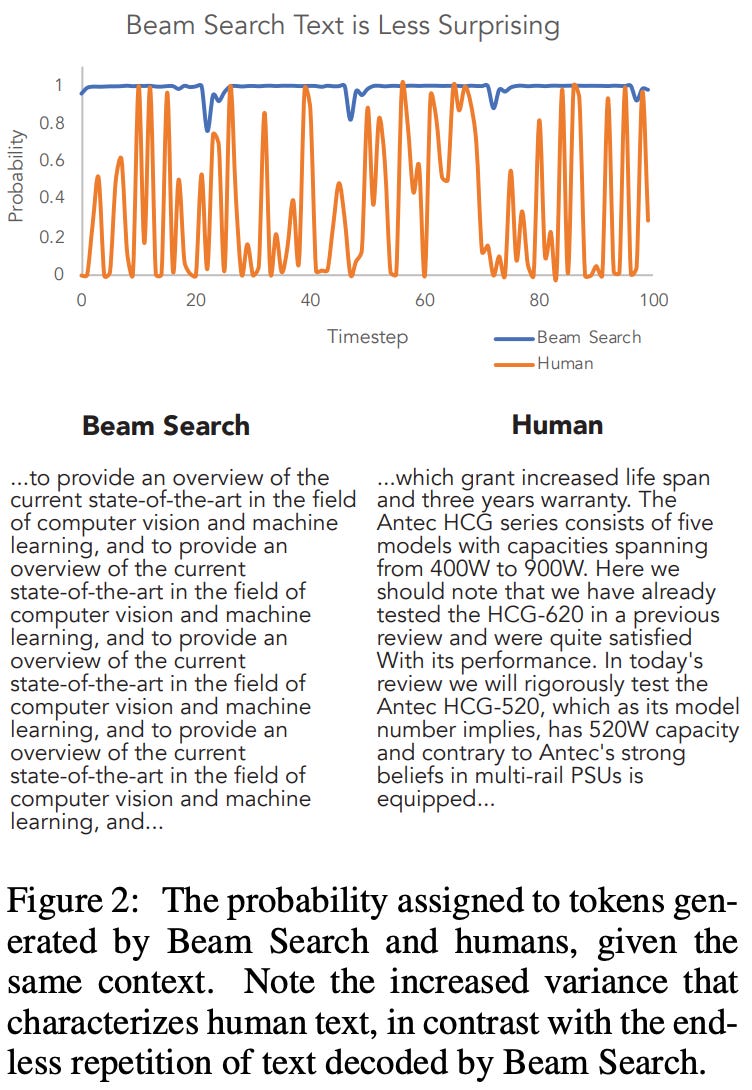
The beam search probabilities are high by design—what’s…surprising…is how much the probabilities of the human-generated text jump around. One solution is to introduce some randomness into the text generation: rather than generating the most-likely next token, sample from the next-token distribution. But pure sampling has a tendency to go off the rails resulting in incoherent (if not also beautiful and poetic) gibberish:

Sampling promotes novelty but too much of it harms learnability. Common alternatives to pure sampling like top-k sampling or nucleus sampling aim for a middle ground by lopping off the tail end of the probability distribution before sampling. This avoids generating very unlikely tokens and helps keep the LLM on track while also allowing for diverse outputs. But it feels sort of hacky. More recently, the cutting edge in generation involves incorporating some sort of Monte Carlo tree search over outputs—often optimizing over some metric other than probability.
Open-ended natural language generation is particularly tricky because the success criteria are not very clearly defined. Domains like games, protein folding, or geometry are more tractable because success criteria are clearer and valid outputs can be verified automatically. Successful systems like AlphaFold and AlphaGeometry combine an LLM architecture for generating ideas with some sort of “external verifier” (e.g. AlphaFold’s structure module that enforces stereochemical constraints or AlphaGeometry’s rule bound deduction engine).
Interestingly, the authors of this open-endedness paper more or less elide the foundation model + external verifier paradigm. Neither AlphaFold nor AlphaGeometry is mentioned or cited in the paper (although one of the authors references AlphaFold in a tweet about this paper as revolutionary but not fully general). Instead, they emphasize a foundation-models-as- “proxy observer”-for-a-RL-or-evolutionary-search-algorithm paradigm. There are though good reasons to be skeptical about the use of foundation models as verifiers.
– Cole
I want to at least mention this figure from David Pfau (source):
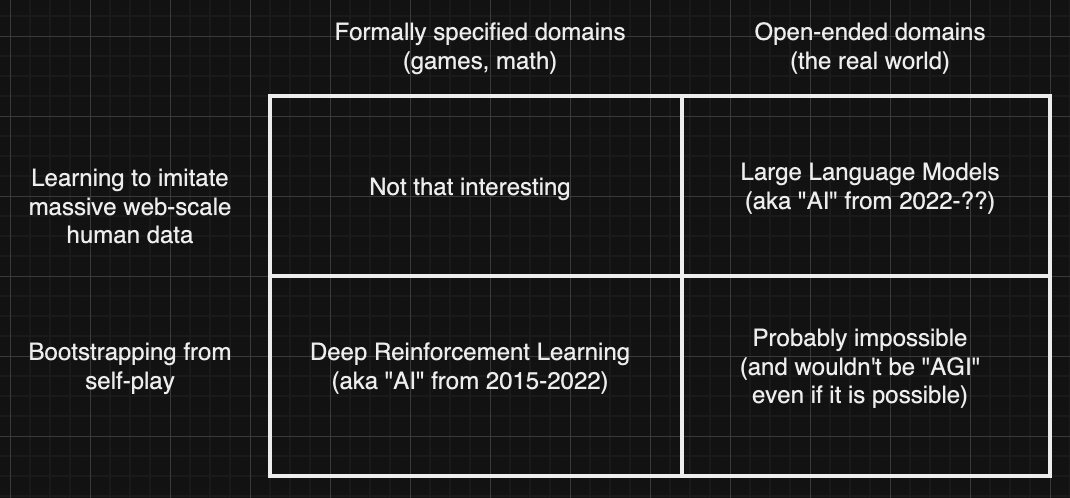
The point being to note that open-endedness—as the authors see it—doesn’t seem to fit neatly into the right side of Pfau’s diagram. We can confirm this by way of the examples the authors provide for open-endedness: AlphaGo (deep RL) is a positive example in that it produces policies that are novel to human expert players; contemporary foundation models are a negative example (the distribution of their data is learnable, and cannot be endlessly novel).
Anyway, I’m still coming to conclusions on all this and would love to hear thoughts.
—Daniel
New from the Gradient
C. Thi Nguyen: Values, Legibility, and Gamification

Vivek Natarajan: Towards Biomedical AI

Other Things That Caught Our Eyes
News
States Take Up A.I. Regulation Amid Federal Standstill
Lawmakers in California are pushing for new regulations on AI to protect consumers and jobs. The proposed bills aim to impose the strictest restrictions on AI in the nation, addressing concerns such as job displacement, disinformation in elections, and national security risks. The measures include rules to prevent AI tools from discriminating in housing and healthcare services, as well as protecting intellectual property and jobs. With the federal government slow to act on AI regulation, state legislators are taking the lead, with California proposing the most bills at 50. These state regulations could set a precedent for the entire country.
First Came ‘Spam.’ Now, With A.I., We’ve Got ‘Slop’
"Slop" is a term used to describe shoddy or unwanted AI content in various online platforms, including social media, art, books, and search results—it refers to inaccurate or irrelevant suggestions or information generated by AI systems. For example, when Google suggests adding nontoxic glue to make cheese stick to a pizza or when a digital book seems similar to what you were looking for but falls short. The term gained more attention when Google incorporated Gemini into its US-based search results, where it attempted to provide an "AI Overview" at the top of the results page.
U.S. Clears Way for Antitrust Inquiries of Nvidia, Microsoft and OpenAI
The US Justice Department and Federal Trade Commission have reached a deal to proceed with antitrust investigations into the dominant roles of Microsoft, OpenAI, and Nvidia in the AI industry. The Justice Department will investigate Nvidia, the largest maker of AI chips, for potential antitrust violations, while the FTC will examine the conduct of OpenAI, the creator of the ChatGPT chatbot, and Microsoft, which has invested heavily in OpenAI. This agreement reflects the increasing regulatory scrutiny of AI technology and its potential impact on jobs and society. The Justice Department and FTC have been actively working to curb the power of major tech companies, and this investigation follows similar actions taken against Google, Apple, Amazon, and Meta.
FTC and DOJ reportedly opening antitrust investigations into Microsoft, OpenAI, and Nvidia
The Federal Trade Commission (FTC) and the Department of Justice (DOJ) have reportedly agreed to split duties in investigating potential antitrust violations by Microsoft, OpenAI, and Nvidia. The DOJ will lead inquiries into Nvidia, while the FTC will focus on the deal between OpenAI and Microsoft. The FTC has been looking into antitrust issues related to investments made by tech companies into smaller AI firms since January. They have already opened an inquiry into OpenAI's data collection practices. The European Commission and the UK's Competition and Markets Authority are separately investigating Microsoft's investment in OpenAI. Nvidia has not been part of any antitrust conversations in the US until now. The investigation does not necessarily mean that the Biden administration is opening cases against these companies, but it is worth noting that a similar deal in 2019 led to cases against Google, Apple, Amazon, and Meta.
Air Force, Space Force unveil tool for AI experimentation
The Air Force and Space Force have introduced a generative AI tool called the Non-classified Internet Protocol Generative Pre-training Transformer (NIPRGPT) to encourage airmen and guardians to experiment with AI technology. The tool aims to improve access to information and determine the demand for AI capabilities within the force. The Defense Department has been exploring the use of generative AI tools to enhance efficiency in daily tasks. The Air Force Research Laboratory (AFRL) developed NIPRGPT using publicly-available AI models and will work with commercial partners to test and integrate their tools. The tool will help determine the best approach for acquiring AI capabilities based on user feedback and demand.
Adobe overhauls terms of service to say it won’t train AI on customers’ work
Adobe is updating its terms of service to address concerns from customers about the use of their work for AI training. The new terms, set to roll out on June 18th, aim to clarify that Adobe will not train generative AI on customer content, take ownership of customer work, or access customer content beyond what is legally required. The company faced backlash from users who interpreted the previous terms as allowing Adobe to freely use their work for AI training. Adobe's president of digital media, David Wadhwani, acknowledged that the language in the terms was unclear and should have been clarified sooner. While Adobe has trained its own Firefly AI model on Adobe Stock images, openly licensed content, and public domain content, the company is working to improve content moderation and allow customers to opt out of automated systems.
Facebook owner Meta seeks to train AI model on European data as it faces privacy concerns
Meta has announced its intention to use data from users in Europe to train its AI models. The company aims to improve the accuracy and understanding of its models by incorporating the languages, geography, and cultural references of European users. However, Meta faces challenges due to stringent European Union data privacy laws, which give individuals control over their personal information. Activist group NOYB has lodged complaints against Meta's AI training plans, urging privacy watchdogs to intervene. Meta emphasizes that it will not use private messages or content from users under 18. The company believes that training its AI models on European data is crucial for accurately understanding regional languages, cultures, and trending topics on social media.
Brazil will start using OpenAI to streamline court system
Brazil has enlisted the help of OpenAI to improve its court system and reduce costs. OpenAI's technology will be used to analyze and summarize thousands of lawsuits, identify trends, and flag the need for action. By using generative AI, Brazil aims to streamline the screening and analysis of cases, identify winnable cases, and avoid costly mistakes. Microsoft will provide access to OpenAI's models through Azure. Brazil is currently spending a significant amount on legal cases, with costs projected to reach 100 billion reais ($18.7 billion) this year. OpenAI's involvement could potentially save the government time and money. The use of OpenAI's models will be supervised by humans and the models are not expected to replace staff. This initiative follows Brazil's previous encounter with AI in its legal system, when legislation was passed with the help of ChatGPT. Overall, Brazil hopes that OpenAI's technology will enhance efficiency and accuracy in its court system, leading to cost savings and improved outcomes.
Waymo issues second recall after robotaxi hit telephone pole
Waymo has issued a voluntary software recall for all 672 of its Jaguar I-Pace robotaxis after one of them collided with a telephone pole. This is Waymo's second recall—the previous recall occurred in February after two robotaxis crashed into a pickup truck. The National Highway Traffic Safety Administration (NHTSA) is currently investigating Waymo's autonomous vehicle software following reports of crashes and potential traffic safety law violations. Waymo is taking a proactive approach to address these issues and prioritize transparency. The accident that prompted the second recall occurred in May when a Waymo vehicle collided with a telephone pole during a low-speed maneuver. Waymo has since implemented mapping and software updates to improve collision avoidance.
Why Apple is taking a small-model approach to generative AI
Apple is taking a different approach to generative AI with its Apple Intelligence system. Unlike other companies that prioritize larger models, Apple focuses on creating smaller, more bespoke models that are tailored to its operating systems. The goal is to provide a frictionless user experience while increasing transparency around the system's decision-making process. Apple's models include specialized "adapters" for different tasks and styles, allowing them to cover a spectrum of requests. The company also allows third-party models like OpenAI's ChatGPT to be used when necessary. Privacy is a key concern, and Apple gives users the option to opt in or opt out of using third-party platforms. The system may process queries on-device or via a remote server with Private Cloud Compute, but Apple ensures that privacy standards are maintained. The company is committed to responsible AI and has released a whitepaper outlining its principles.
Photographer Disqualified From AI Image Contest After Winning With Real Photo
Photographer Miles Astray has been disqualified from the 1839 Color Photography Awards after his real photograph won in the AI image category. Astray entered a surreal photo of a flamingo to show that nature can still beat AI-generated imagery. Despite the judges and the People's Vote Award recognizing the photo, the competition organizers disqualified Astray's entry, stating that it did not meet the requirements for the AI-generated image category.
AI Detectors Get It Wrong. Writers Are Being Fired Anyway
AI detectors are being used to flag AI-generated text and detect plagiarism, but they are often unreliable and make frequent mistakes. As a result, writers are losing their jobs due to false accusations from these detectors. AI detection companies claim high accuracy rates, but experts argue that these claims are exaggerated. AI detectors look for signs of AI penmanship, such as perfect grammar and punctuation, but these factors are not foolproof. Major institutions, including universities, have banned the use of AI detection software due to false accusations. While AI detectors are seen as a necessary tool in a world flooded with robot-generated text, they have significant shortcomings.
OpenAI Insiders Warn of a ‘Reckless’ Race for Dominance
A group of current and former employees at OpenAI are raising concerns about the company's culture of recklessness and secrecy. They believe that OpenAI is prioritizing profits and growth over the safety of its AI systems, which are being developed to achieve AGI. The group also alleges that OpenAI has used restrictive nondisparagement agreements to silence employees who want to voice their concerns. This whistleblowing highlights the potential dangers of a race for dominance in AI development.
Papers
Daniel: It is one of those weeks, so I have a list once again—
Discovering Preference Optimization Algorithms with and for Large Language Models
Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
The Prompt Report: A Systematic Survey of Prompting Techniques
Filtered Corpus Training (FiCT) Shows that Language Models can Generalize from Indirect Evidence
Show, Don’t Tell: Aligning Language Models with Demonstrated Feedback
The Geometry of Categorical and Hierarchical Concepts in Large Language Models
Evaluating the persuasive influence of political microtargeting with large language models
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!