

Update #75: A Bad Week for AI Worriers, and The Platonic Representation Hypothesis
AI worries are not having a great time this week; MIT researchers think model representations in models are converging (to what?).


Welcome to the 75th update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter. Our newsletters run long, so you’ll need to view this post on Substack to see everything!
Editor Notes
Good morning.
We have some very fun highlights for you this week. I hope this newsletter continues to avoid being a watercooler, but let us know how we’re doing. In thinking about some of the dramatis personae, I imagine it must be very weird to have people try to make predictions about AGI based on the position of your left hand and the sneakers you wore yesterday.
On other fronts, I learned from Suhail Doshi that he is not in pivot hell, and had a nice conversation with Azeem Azhar about many things.
Also, a few people had nice things to say about the podcast—I hate to be self-indulgent, but it meant so much to me that I couldn’t resist sharing.
If you have any feedback for us—please do let us know. We read every comment and every email.
As always, if you want to write with us, send a pitch using this form.
Can't afford to test in production? Come to The world’s first AI Quality conference
On June 25th in San Francisco, join the first ever AI Qualify conference. Join 1000+ other highly informed attendees to connect and learn about how you can keep grom letting your AI efforts go awry.
Hear speakers from Uber, Groq, Cruise, Torc Robotics, Notion, Anthropic, Open AI, Google and 20+ more organizations.
Use the special discount code ‘hallucinate’ for 30% off the ticket price.
News Highlight: A Bad Week for People Worried About AI

Summary
Two big pieces of news in the AI world last week:
A bipartisan group of senators, including Senate leader Chuck Schumer (D-N.Y.), released a 20-page legislative roadmap for A.I.
On the heels of the company’s big GPT-4o release, OpenAI’s superalignment team dissolved, with various prominent employees including Ilya Sutskever and Jan Leike resigning.
Overview
AI Roadmap to Where?
Schumer and the other members of the Senate AI Working Group—Todd Young (R-Ind.), Martin Heinrich (D-N.M.) and Mike Rounds (R-S.D.)—released a 20-page document titled “Driving U.S. Innovation in Artificial Intelligence,” the culmination of a series of nine AI Insight Forums held last fall. The report identifies areas of consensus that the authors believe “merit bipartisan consideration in the Senate.” These include:
At least $32 billion of annual non-defence funding for AI R&D by FY2026
A “strong comprehensive federal data privacy law”
Legislation to increase high-skilled STEM immigration
The development of standards for use of AI in critical infrastructure
Full funding of previously authorized efforts, such as the CHIPS and Science Act
Schumer stressed that the Working Group does not intend to compile their recommendations into a single bill and that relevant congressional committees should instead advance their own smaller bills in line with the report’s recommendations.
The roadmap was roundly rebuked by those hoping for more comprehensive regulation of AI. The roadmap’s primary focus seems to be on supporting AI innovation, and the recommendations that address AI harms like protections against health and financial discrimination, job displacement, and copyright are all fairly vague. Nik Marda, a technical lead at Mozilla, pointed out that the roadmap references “bias” as many times as it references “space debris” (three times each). Dr. Suresh Venkatasubramanian, a co-author of the White House’s AI Bill of Rights, participated in the AI Insight Forums and reacted to the roadmap with disappointment, telling Fast Company “I think many people like myself were concerned whether this would be a dancing monkey show, and we’re the monkeys…I feel betrayed.”
We reached out to Dr. Venkatasubramanian for further comment and he elaborated that he was “disappointed that while researchers have been insisting for years now that the best way to innovate on AI in rights-impacting settings is to center people and society - in other words, conduct sociotechnical research on the way automated systems can be incorporated into our lives - the roadmap seems to take a very narrow technical approach to investments in AI research.”
OpenAI Unalignment
Last Tuesday, the day after the GPT-4o launch, OpenAI’s Chief Scientist Ilya Sutskever and the co-head of the superalignment team Jan Leike announced their departures from the company. The superalignment team, whose goal was to solve the core technical challenges needed to “steer and control AI systems much smarter than us”, had been leaking researchers for several months and by Friday Wired confirmed that the entire team had been disbanded with all of its members having resigned or been absorbed into other research groups.
OpenAI reportedly has those departing sign non-disparagement agreements (at risk of losing their equity), but Leike did not hold back about his reasons for leaving in the thread he posted to X on Friday, and it’s worth quoting at length: “I have been disagreeing with OpenAI leadership about the company's core priorities for quite some time, until we finally reached a breaking point. I believe much more of our bandwidth should be spent getting ready for the next generations of models, on security, monitoring, preparedness, safety, adversarial robustness, (super)alignment, confidentiality, societal impact, and related topics. These problems are quite hard to get right, and I am concerned we aren't on a trajectory to get there. Over the past few months my team has been sailing against the wind. Sometimes we were struggling for compute and it was getting harder and harder to get this crucial research done. Building smarter-than-human machines is an inherently dangerous endeavor. OpenAI is shouldering an enormous responsibility on behalf of all of humanity. But over the past years, safety culture and processes have taken a backseat to shiny products.”
Our Take
A stylized way to think about AI concerns is that there are two types of people worried about AI:
People who are worried about A.I. because of its limitations. These people focus on the shortcomings of current A.I. systems and the harms arising from their deployment. They talk about things like algorithmic bias, and AI ethics, and the importance of keeping a human in the loop.
People who are worried about A.I. because of its capabilities. These people focus on the rapid improvement in these systems and extrapolate them forward. They make direct analogies to human intelligence and talk about things like AGI, existential risk, and alignment.
In practice there is a lot more nuance than this and most people (myself included) fall somewhere in the middle. But I think this is a useful framework for thinking about the two poles of the AI worry spectrum and making sense of this past week’s events.
Despite both being worried about AI these two groups do not see eye to eye. The limitation worriers see the problem as largely sociotechnical, emphasis on “socio”. The technology is inherently flawed and the solution is not better technology so much as better regulation of how people use the technology. Beyond getting incentive structures right (👀 OpenAI’s charter), capabilities worriers prioritize technical solutions: technical research got us into this pickle, technical research will get us out of this pickle. Alignment is a technical research effort not a matter of policy.
Neither group got their preferred outcomes last week. The alignment people can’t get the compute they want and the AI ethics people are no closer to regulation with teeth.
—Cole
Research Highlight: The Platonic Representation Hypothesis

Summary
Researchers from MIT argue that representations in AI models trained with different objectives on different datasets and modalities are converging. Huh et al. demonstrate this convergence by measuring the distance/similarity between datapoints and comparing the similarity structures induced by different representations. They find that as vision models and language models get larger and more competent, the ways they measure distance between datapoints become more and more alike. This leads to the hypothesis that neural networks are converging toward a shared statistical model of reality, a "platonic representation" in reference to Plato's Allegory of the Cave and his conception of an ideal reality that underlies what we perceive.
Overview
The authors consider vector embedding representations and argue that different neural networks are converging to aligned representations. They measure alignment through a mutual k-nearest-neighbor metric, defined as the average size of the overlap of nearest neighbor sets induced by two representations through inner product. Evaluating the transfer performance of 78 vision models on the VTAB dataset, they find that models with high performance have high representation alignment while models with weak performance have more variable representations, which leads them to conclude "all strong models are alike, [while] each weak model is weak in its own way."
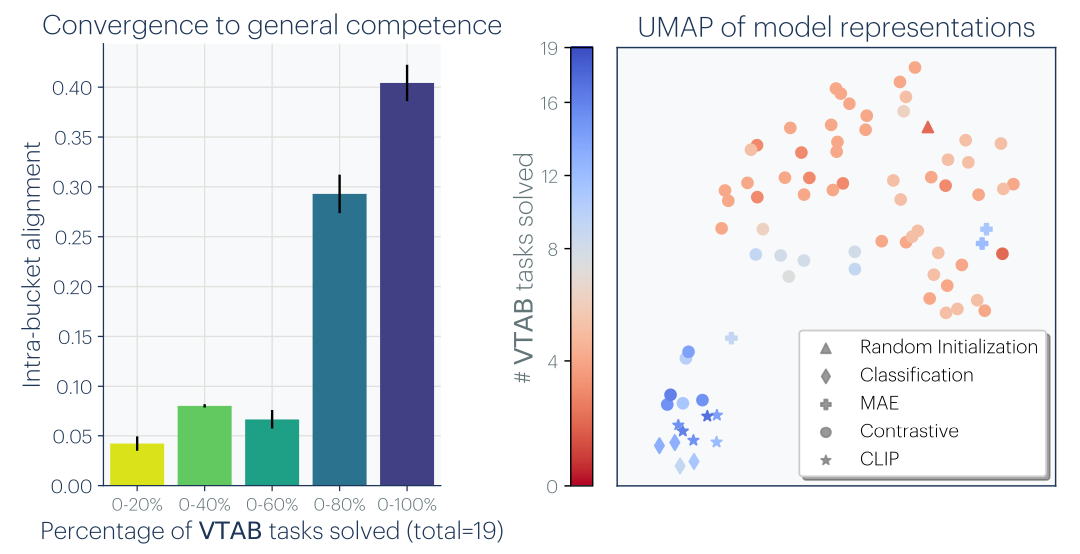
That alignment increases with scale and performance holds true across modalities as well. Using the Wikipedia captions dataset made of images and their corresponding captions, the authors find that the better an LLM is at language modeling, the more it tends to align with vision models, and vice versa. Further, language models that are more closely aligned with vision also demonstrate better downstream performance on tasks such as commonsense reasoning and mathematical problem solving.

As to why representations are converging, the authors offer three hypotheses that correspond to three components of a common machine learning model formula:

First, with sufficient data, scaling a model, i.e. using larger function classes F, as well as improved optimization, should be more effective at finding better approximations to a globally optimal representation. Second, there are fewer representations that are competent in multiple tasks as we scale data and tasks. Models that optimize the empirical risk (the expectation over observed data) also become better at capturing statistical structures of the true data generating process (the population risk). Third, deep networks favor simple solutions that fit the data, with or without explicit regularization. Bigger models have a stronger bias toward simplicity and thus converge to a smaller solution space.
But what exactly is this shared representation of underlying reality? The authors offer one concrete candidate. In an idealized world that consists of a sequence of discrete events, which can be observed in various ways (pixels, sounds, words, and so on), a family of contrastive learners that model co-occurring observations converge to the same pointwise mutual information (PMI) kernel, representing certain pairwise statistics of the unknown underlying distribution that generates the events. Their analysis suggests that certain representation learning algorithms may boil down to simply finding an embedding in which similarity equals PMI.
Our Take
What excites me the most about this representational convergence is the ability to share and use data from different modalities for training and inference. It also suggests that multimodal models are better than single-modal ones, given they are grounded in additional modalities and should represent the world in a way that's closer to what the world really is. On the other hand, it is not clear whether a 16% alignment (see one of the figures above) between a set of language and vision models is significant enough to qualify as "convergence." I'm also questioning whether this platonic representation, assuming it does exist, is the endpoint we should pursue, as opposed to what we want the world to be. But that's a whole other ethical debate.
– Jaymee
I am just waiting for the philosophy takes on this paper (because then we’ll REALLY have come full circle). But, before we come up with another project and set about trying to determine whether moral realism is a thing based on what AI models seem to be doing, we should probably take stock of a few aspects of what’s going on in the paper. I think a few interesting callouts are section 2.4, where the authors draw on the related point that neural networks seem to show substantial alignment with biological representations in the brain. I also think the three hypotheses presented in section 3 are useful intuition pumps: the Multitask Scaling Hypothesis says if we consider competency at some number of tasks, N, we should expect fewer representations to be competent for all N tasks as N grows larger. You might also expect that models with larger hypothesis spaces to be more likely to find an optimal representation, if one exists in function space—the authors call this the Capacity Hypothesis. Finally, the Simplicity Bias Hypothesis says deep networks are biased towards finding simple fits to the data, and larger models will have a stronger bias.
I think, if you buy what’s being said here, the “our current paradigm is not very efficient” point becomes something like: fairly general architectures without strong inductive biases towards certain sorts of representations (beyond the simplicity bias), scaled up enough and trained to solve a general enough task(s), will have large enough hypothesis spaces that they’ll eventually be pressured to find optimal representations for their data. It is worth noting that datasets and tasks are structured by what we take to be useful and want models to do, and so while I think it might be perfectly fine to posit that there’s a representation (or representations) most useful for those things, calling it a “shared representation of reality” feels a bit grandiose (maybe I’m just being annoying. But, to be fair, you could be a lot more annoying about this paper if you really wanted. I’ll leave doing that as a take-home exercise—imagine you’re Reviewer 2 and have at it). If you’ve heard of projectivism… it seems reasonable to think that “representation of reality” might be projectivism.
All that said, this is a thoughtful and interesting paper. I like the counterexamples and limitations section the authors include at the end, and I think you should read it in full.
Also, for other takes on “universal” representations / representations useful for transfer learning, I had a conversation with Hugo Larochelle some time ago that went into a bunch of his work on this—I expect you’d find a number of his papers on the subject interesting if you liked this one.
—Daniel
New from the Gradient
Suhail Doshi: The Future of Computer Vision

Azeem Azhar: The Exponential View

Other Things That Caught Our Eyes
News
OpenAI says it’s building a tool to let content creators ‘opt out’ of AI training
OpenAI is developing a tool called Media Manager that will allow content creators to have more control over how their works are used in training generative AI. The tool will enable creators to identify their works and specify whether they want them to be included or excluded from AI research and training. OpenAI plans to have the tool in place by 2025 and is working with creators, content owners, and regulators to establish a standard. The goal is to build a cutting-edge machine learning tool that can identify copyrighted text, images, audio, and video across multiple sources and reflect creator preferences. This initiative is a response to criticism of OpenAI's approach to AI development, which involves scraping publicly available data from the web. OpenAI has faced lawsuits for IP infringement and has taken steps to address concerns, such as allowing artists to opt out of using their work and signing licensing deals with content owners. However, some content creators believe OpenAI's efforts are insufficient.
Apple plays up AI potential in new iPads
Apple has introduced new iPads that highlight their potential for artificial intelligence (AI) features. The new Pro models come with a more powerful "neural engine" in the M4 chipset, which drives AI and machine learning features in third-party apps and Apple's own software. The neural engine in the M4 chipset is capable of performing 38 trillion operations per second, more than double the operations per second of the previous M3 chipset. This move by Apple is seen as an effort to catch up with rivals in the AI race.
In Arizona, election workers trained with deepfakes to prepare for 2024
The article discusses a unique training exercise conducted in Arizona to prepare election workers for potential deepfake attacks in the 2024 elections. Arizona Secretary of State Adrian Fontes addressed the election workers in a video message, emphasizing the importance of their role and the need to be prepared for new challenges. The training aimed to familiarize the workers with deepfake technology, which can create realistic but false videos or audio recordings. By experiencing and identifying deepfakes, the election workers can enhance their skills in detecting and mitigating potential threats.
Three Bills in Colorado Look to Put Some Guardrails on Artificial Intelligence
Colorado lawmakers are working on three bills to regulate the use of artificial intelligence (AI). The first bill, House Bill 24-1147, aims to regulate the use of deepfakes produced using generative AI in communications about candidates for elective office. It adds a disclosure requirement to their use and creates a civil private right to action when that requirement isn't met. The second bill, Senate Bill 24-205, focuses on protecting consumers from algorithmic discrimination in high-risk AI systems. It defines algorithmic discrimination as any condition where the use of AI results in unlawful differential treatment based on protected characteristics. The third bill, House Bill 24-1468, updates the membership and issues of study for the task force on facial recognition services, expanding its scope to include biometric technology and AI. These bills aim to provide guardrails and protections in the use of AI.
OpenAI Is ‘Exploring’ How to Responsibly Generate AI Porn
OpenAI, the company behind ChatGPT and other AI technologies, is exploring the possibility of responsibly generating NSFW (not safe for work) content, including porn and explicit materials. While OpenAI's current usage policies prohibit sexually explicit or suggestive content, the company is considering how to permit such content in age-appropriate contexts. The Model Spec document mentions that NSFW content may include erotica, extreme gore, slurs, and unsolicited profanity. OpenAI aims to better understand user and societal expectations in this area. However, the company emphasizes that it does not intend for its models to generate AI porn. The potential for AI-generated pornography raises concerns about privacy violations and nonconsensual use of synthesized intimate images. OpenAI's exploration of explicit content generation and its moderation to prevent misuse by bad actors remain important considerations.
TikTok will automatically label AI-generated content created on platforms like DALL·E 3
TikTok has announced that it will automatically label AI-generated content created on other platforms. The company will use Content Credentials, a technology developed by the Coalition for Content Provenance and Authenticity (C2PA), to attach specific metadata to AI-generated content. This metadata will allow TikTok to recognize and label AI-generated content instantly. The change is rolling out globally and will apply to all users in the coming weeks. TikTok already labels content created with its own AI effects, but this new feature will extend to content created on other platforms that have implemented Content Credentials. TikTok is the first video-sharing platform to implement this technology. The goal is to ensure transparency for viewers and to deter harmful or misleading AI-generated content. The company is also committed to combating deceptive AI in elections.
Meet the Woman Who Showed President Biden ChatGPT—and Helped Set the Course for AI
Arati Prabhakar, the director of the White House Office of Science and Technology Policy, played a crucial role in demonstrating the potential of AI to President Biden. This led to the issuance of a comprehensive executive order that sets a regulatory course for the AI industry. Prabhakar, who has a background in applied physics and experience in Silicon Valley, has been educating top officials about the transformative power of AI. The executive order mandates safety standards, promotes innovation, and addresses job losses. Prabhakar is the first person of color and first woman to hold the position of director of the office.
Amazon’s self-driving robotaxi unit Zoox under investigation by US after 2 rear-end crashes
The U.S. National Highway Traffic Safety Administration (NHTSA) is investigating Amazon's self-driving robotaxi unit, Zoox, after two of its vehicles were involved in rear-end crashes. The crashes occurred in San Francisco and Spring Valley, Nevada, and both involved Toyota Highlander SUVs equipped with autonomous driving technology. The NHTSA will evaluate Zoox's automated driving system and its performance during the crashes, as well as its behavior around pedestrians and other vulnerable road users. Zoox has stated that it is committed to working with the NHTSA and that the vehicles had human safety drivers on board. This investigation comes after a previous investigation into Zoox's certification of meeting federal safety standards.
Deepfakes of your dead loved ones are a booming Chinese business
The Chinese market for AI avatars of deceased loved ones is booming, with several companies offering the technology and thousands of people already paying for it. These avatars, created using deepfake technology, aim to preserve and interact with lost loved ones. While the technology is not perfect, it is maturing and becoming more accessible to the general public. However, there are concerns about the ethical and legal implications of interacting with AI replicas of the dead. Despite this, the market potential is significant, even if only a small percentage of Chinese people accept this technology. The Chinese sector developing AI avatars has rapidly matured in the past three years, with avatars improving from rendered videos to 3D "live" avatars that can interact with people.
Fooled by AI? These firms sell deepfake detection that’s ‘REAL 100%.’
A Bay Area start-up has gained attention for its ability to detect deepfakes with 99% accuracy. The company has secured several military contracts, including a $1.25 million deal with the Air Force to develop a custom detector for countering Russian and Chinese information warfare. The CEO of the company recently testified before a Senate subcommittee about the threat that AI deepfakes pose to U.S. elections. This highlights the growing concern over the use of AI-generated fake images, audio, and video, and the need for effective detection methods.
No, We Don’t Need AI to Go on Dates for Us
The article discusses the idea of using AI concierges in dating apps to screen potential matches and recommend the best ones for users to meet. The author highlights the anthropomorphic element of these AI technologies and emphasizes that they are not necessarily new or emerging, but rather a reflection of the computational capabilities that already exist. The introduction of AI concierges in dating apps raises concerns about the potential for discrimination and social stratification. The author points out that while the algorithm may advocate for the interests of its user, it ultimately discriminates against each user along various dimensions. The article also mentions the use of credit-checking and performance ranking systems in Chinese dating apps, which reflect and reinforce social stratification.
Google’s invisible AI watermark will help identify generative text and video
Google is expanding its AI content watermarking and detection technology to include video and AI-generated text. The upgraded SynthID watermark imprinting system can now mark digitally generated video and AI-generated text. This is important as AI technology becomes more prevalent and can be used for malicious purposes such as spreading misinformation and creating nonconsensual content. SynthID was initially developed to imprint AI imagery that is undecipherable to humans but detectable by the system. Google has also used SynthID to inject inaudible watermarks into AI-generated music. This is part of Google's efforts to develop AI safeguards to combat misuse of the technology. The Biden administration is also directing federal agencies to create guidelines around these safeguards.
Microsoft has announced its largest investment in France to date, with a focus on accelerating the adoption of artificial intelligence (AI), skilling, and innovation. The investment includes building advanced cloud and AI infrastructure, providing AI training to individuals, and supporting French startups in utilizing Microsoft technology. This investment showcases Microsoft's commitment to supporting digital innovation and economic growth in France.
What Do You Do When A.I. Takes Your Voice?
In this article, the author discusses the rising threat of artificial intelligence (A.I.) to the livelihoods of writers, actors, and other entertainment professionals. The article highlights a podcast that the couple, Paul Skye Lehrman and Linnea Sage, listened to, which featured an interview with a talking chatbot named Poe that sounded just like Mr. Lehrman. This unexpected twist emphasized the potential harm that A.I. could have on the entertainment industry. The couple was left in disbelief and unsure of how to respond to this situation.
Papers
Daniel: I have been sick and so this set of recommendations is probably going to just be a list. ContextCite is a new method (with, as of this part, a demo and code, but no paper!) which traces part of a LM-generated response back to a piece of the model’s context. The authors distinguish corroborative attribution (identifying sources that support or imply a statement) form contributive attribution (identifying the sources that cause a model to generate a statement)—methods for corroborative attribution of LMs exist, so it’s the latter sort of attribution that ContextCite provides. The method relies on the intuition that if a source is important to a model’s generation, removing that source should change the generated content significantly. So, after generating a response for a given context and query, the authors: (1) randomly ablate sources in the context to exclude and compute the probability of generating the original response for each ablation mask; (2) fit a surrogate model to this “training dataset” to estimate the probability of generating the original response as a function of the ablation mask.
This paper from about a month ago presents 12 results on how (1) training duration, (2) model architecture, (3) quantization, (4) sparsity constraints, and (5) data signal-to-noise ratio affect a model’s knowledge storage capacity.
I also like the paper “Algorithmic Progress in Language Models,” which takes a look at the rate of improvement for language model pre-training algorithms, and finds that (a) the compute required to reach a set performance threshold has halved about every 8 months, and (b) despite algorithmic and architectural progress, increases in compute made an even larger contribution to overall performance improvements from 2012-2023.
Lastly, you might find this frontier safety framework out of DeepMind interesting.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!