

Update #73: Against Language Erasure and Better Long-Context Benchmarking
Researchers and governments develop data sets and technology for local languages, and NVIDIA presents a new, more thorough benchmark for long-context models.



Welcome to the 73rd update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter. Our newsletters run long, so you’ll need to view this post on Substack to see everything!
Editor Notes
I’m very excited to welcome two new editors to our team: Jaymee Sheng and Cole Frank. Jaymee was previously editor-in-chief for an interdisciplinary academic journal, published some very interesting computational social science research, and worked as an ML engineer. Cole worked in macroeconomic analysis for 4 years before getting interested in AI, and now does ML research and AI curriculum development at CMU’s Software Engineering Institute. They’ll both be part of the editorial staff and help out with the newsletter.
As you can see, we’re doing occasional advertisements in our newsletter—we’re open to considering more.
Want to write with us? Send a pitch using this form.
Can't afford to test in production? Come to The world’s first AI Quality conference
On June 25th in San Francisco, join the first ever AI Qualify conference. Join 1000+ other highly informed attendees to connect and learn about how you can keep grom letting your AI efforts go awry.
Hear speakers from Uber, Groq, Cruise, Torc Robotics, Notion, Anthropic, Open AI, Google and 20+ more organizations.
Use the special discount code 'testinprod' for 20% off the ticket price.
News Highlight: Researchers and Governments Push Back Against Generative AI's Erasure of Low-Resource Languages

Summary
It is no secret that the internet is dominated by English content and AI models tend to perform better on English than other lower-resource languages, if they are supported at all. Recently AI chatbots have been found to mischaracterize an African language spoken by over 2 million people as a fictional language and to provide incorrect dates and information about how to cast a ballot for the upcoming EU election. The risk of generative AI further marginalizing non-English languages and cultures has prompted researchers and governments alike to develop data sets and technology for local languages in an effort to preserve them and better serve their own populations.
Overview
More than half of all the websites on the internet use English as their primary language, even though over 80 percent of people in the world don't speak it. Google Translate supports 133 of some 7,000 languages spoken in the world; most of the highest-performing language models serve only 8 to 10 languages. As reported by The Atlantic, a popular AI model recently described Fon, a language spoken by 2.3 million people in Benin and neighboring countries, as "a fictional language." As chatbots and generative AI continue to influence how people navigate the web and interact with the world, those who do not have command of a high-resource language will not be able to rely on AI to draft work memos, conduct research, tutor their child, search for information, or perform other tasks. Due to poor quality of existing online content in low-resource languages, models trained on machine translated texts could also expose speakers of those languages to misinformation. Moreover, models tend to lack awareness of cultural context and nuance. For example, a researcher at AI Singapore found that models trained with translated texts in several Southeast Asian languages know "much more about hamburgers and Big Ben than local cuisines and landmarks."
To save hundreds of African languages from being washed out by AI, researchers like Ife Adebara who works with Masakhane, a grassroots NLP community, are racing to collect data and create software for languages that are poorly represented on the web. It took Adebara years to curate a 42-gigabyte training data set for 517 African languages–the largest and most comprehensive to date, yet it is only 0.4% of the size of the largest publicly available English training data set.
In Europe, a research study conducted in March by Berlin-based NGO Democracy Reporting International found that chatbots by Google, Microsoft, and OpenAI tended to return incorrect election dates and information about how to cast a ballot ahead of the European election. To eliminate potential election risks like this connected to generative AI tools and counteract U.S. cultural dominance, EU countries have been pushing for development of local models that are truly fluent in local languages. According to data from Politico, 9 countries have already released large language models focused on their local languages, while 7 others are developing them. Most of these projects are open-source. The fight with tech companies over high-quality non-English training content such as media archives and news outlets has also led France's Finance Minister Bruno Le Maire to propose the creation of a price-controlled European single market for training data, in order to prevent U.S. tech giants from outbidding European AI companies for access.
Our Take
People want to be reflected in the technology they use. And when they don't see their language and culture represented in online media or taken into consideration by transformative technologies like AI, it's easy to feel that their language is not important and that adapting to higher-resource languages like English is a must. Most of us don't take proclamations by companies like OpenAI that they want to benefit "all of humanity" at face value, and it's worthwhile for all of us to consider who are enjoying the benefits at whose expense and who are getting left behind. Grassroots efforts made by collectives like Masakhane seem an effective and necessary antidote to the relentless takeover of English-centric AI in our world, and I particularly appreciate their focus on understanding what people actually need (not everyone needs or wants a powerful general-purpose chatbot) and building the technology accordingly. Collecting quality data for lower-resource languages is extremely time-consuming and a labor of love, I think, because who will save our languages if not ourselves?
- Jaymee
Research Highlight: “RULER: What’s the Real Context Size of Your Long-Context Language Models?”

Summary
Researchers at NVIDIA released a paper detailing a new benchmark for long-context language models called RULER (not an acronym!). The authors motivate the construction of their benchmark by pointing out the insufficiency of some of the most commonly used long-context evaluations, which are already becoming saturated (i.e. most SoTA models achieve scores close to the upper limit of what the benchmark can test) and only test models on simple retrieval from context. In contrast, RULER contains four task categories–retrieval, multi-hop tracing, aggregation, and question answering–that are designed to probe for a more comprehensive form of natural language understanding. The authors evaluate GPT-4 and nine open-source, long-context LMs on their new benchmark. Despite all of these models achieving near-perfect results on the standard needle-in-a-haystack (NIAH) test, they find significant performance drops for all of the models as context size increases.
Overview
In the past year there has been a flurry of research into enabling language models to handle longer context windows more efficiently—both via modifications to the transformer architecture (flash attention, ring attention, sparse attention, length extrapolation via novel embedding methods like ALiBi and RoPE, clever methods to reduce the size of context for a given length, and many others.), and with entirely new architectures (Mamba, RWKV, etc.). Just last week, Google introduced a new attention mechanism they’re calling “Infini-attention” for handling infinitely long inputs with bounded memory and computation.
But evaluations of these longer and longer context windows have not kept apace. The most commonly used long context evaluations—passkey retrieval and NIAH tests—entail prompting a model with a {key}:{value} pair embedded in some distractor text (Paul Graham essays are a popular choice) along with a query to retrieve the value that corresponds to the provided {key}. Aside from being saturated, these evaluations only test a very narrow and superficial form of natural language understanding. And yet they remain the standard for demonstrating long-context capabilities. For example, Google’s “Infini-attention” paper only reports results on two benchmarks: a passkey retrieval task and a ROUGE-based book summarization evaluation).
To improve on NIAH, Hsieh et al. devise a test suite of thirteen tasks divided across four task categories:
Retrieval: These tasks expand on the standard NIAH test with more complex multi-key, multi-value, and multi-query variations:

Multi-hop Tracing: A novel task called variable tracking (VT) that tests the model’s ability to trace variable assignments within the context:

Aggregation: Two novel tasks, common word extraction (CWE) and frequent word extraction (FWE), that test the model’s ability to aggregate information by asking which words appear most frequently in the context:

Question Answering: Augmentations of existing QA datasets with distracting information to evaluate question answering performance at varying context lengths:

All of the tasks are completely synthetic and have flexible configurations (e.g. number of keys or values included for the NIAH test) that allow for adjustable difficulty. Overall performance on RULER is the average of all thirteen tasks.
The authors evaluate GPT-4 and a number of open-source models on RULER, and show that their benchmark reveals a lot of variation in model performance that a basic NIAH test would have missed. Here is model performance with context windows ranging from 4k to 128k on just such a basic NIAH test:

Notice that there is virtually no variation in performance for context windows smaller than 64k tokens. But when they evaluate the same models over the same range of context windows on RULER, significant variations in performance are evident at smaller context lengths:
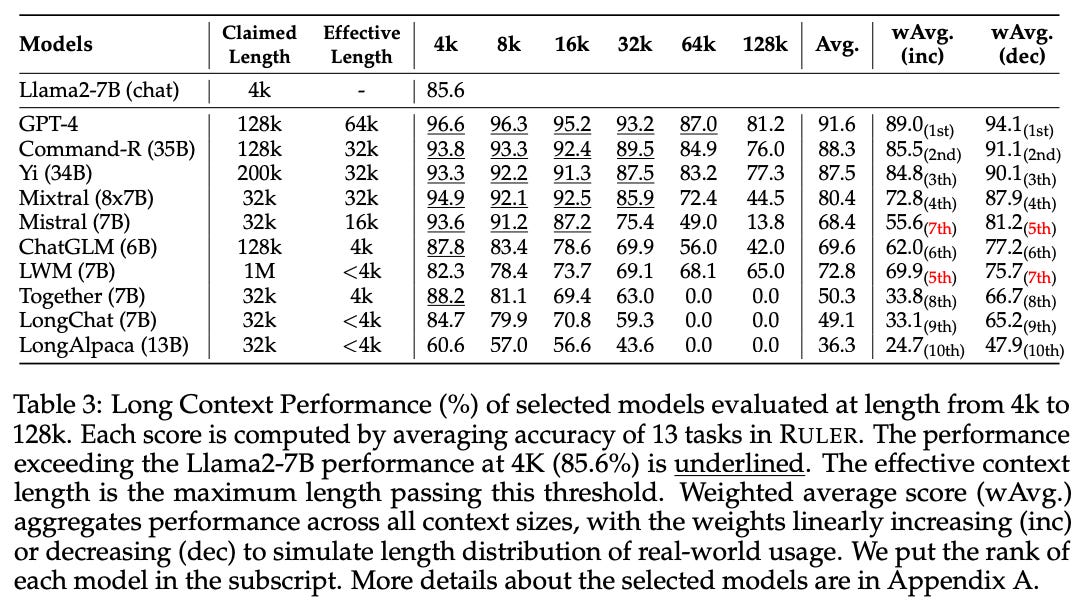
The authors choose Llama2-7b performance at 4K on RULER (85.6%) as a somewhat arbitrary threshold for determining the “effective” context length of each model (i.e. the longest context length at which the model outperforms the threshold). At this threshold, Mixtral (8x7B) is the only model with an effective length greater than or equal to its claimed context length. GPT-4 is the only model that surpasses the threshold at 64k and it also exhibits the least performance degradation between 4k (96.6%) and 128k (81.2%). Unsurprisingly, the three best-performing open-source models (Command-R, Yi, and Mixtral) are also the largest in parameter size.
To get a better sense of task-level performance, the authors report detailed results of Yi-34B-200k on the individual RULER tasks with a range of configurations. They find that the NIAH variation Yi struggles the most with as context increases is the multi-key (MK) setting:

They also find that simply swapping the type of key from a 7-digit number or word to a 32-digit UUID degrades performance (see, for example, the gap between the dark green and light green lines in the second plot from the left above).
On the non-NIAH tasks, the authors observe performance degradation and a range of failure modes that would have otherwise gone unnoticed.

In particular, on the VT and FWE tasks, Yi has a tendency to copy from context as window size increases: “over 80% of Yi’s output in the CWE task at 128k is simply a string copied from the one-shot example, whereas the copying is non-existent for short sequences.” The results above also show that performance drops on more complex configurations of both VT (more variable “chains”) and FWE (a lower \alpha indicates a flatter distribution of word frequencies in the context, making the task of aggregating them more difficult). Finally, on the QA task Yi exhibits a tendency to hallucinate as context length increases. This finding prompts the authors to observe that the “fuzzy matching between a query and a relevant paragraph in long context is a more challenging setting than the simplistic NIAH tests.” Overall, the results on the non-NIAH tasks underline the importance of testing long-context models on behaviors other than retrieval.
The paper also includes ablation results for RULER on context length during training, model size, and non-transformer architectures:

The two leftmost plots above show that, overall, training on longer context lengths does lead to better performance. The size comparison plot (second from right) indicates that larger models are better at long-context modeling all else equal. And finally, the far right plot shows that two non-transformer architectures, RWKV-v5 and Mamba-2.8b, lag the performance of the transformer baseline Llama2-7b model.
Our Take
Concern about the saturation and insufficiency of existing benchmarks went mainstream this week with the New York Times’s tech columnist Kevin Roose devoting a 1000+ word column to “A.I.’s measurement problem”. On the one hand, he’s not wrong: claims about model performance are only as good as the benchmarks they’re based on. On the other hand, this is not a new problem: designing better evaluations has been a central problem in natural language processing for at least the last thirty years.
This seems like a perennial problem. We want benchmarks that are neither too easy nor too hard. So as models get better, we naturally need better evaluations. Of course the open-endedness of the types of problems we use and aspire to use LLMs for makes designing good evaluations really difficult. Arguably, a good heuristic for evaluations might be whether or not it’s a task that can be completed by a simpler algorithm. Simple NIAH tests fail this heuristic; all you need is a regular expression. And the results on RULER bear out the fact that NIAH misses important dimensions of natural language understanding. But much like models, no evaluation is perfect or final for that matter. The synthetic nature of all the non-QA tasks in RULER mean that they don’t capture slippier notions of human judgment that we might want to capture—the type of human judgment that methods like RLHF seek to emulate. Luckily there are an increasing number of other long-context, human-labeled evaluations out there aiming to solve exactly that problem.
– Cole
I’ll never stop harping about the need for better benchmarks and the difficulty of creating standards that make sense for the various things we want to measure—this is clearly a step in the right direction, as Cole pointed out. I don’t know that there's much to add, besides that I wish we’d get better at scoping our claims to the information we actually have available, which crucially depends on the benchmarks we’ve constructed and their role in what we can actually know about the methods we’re developing. We really don’t want more situations like where this paper argued RecSys was in 2019.
—Daniel
New from the Gradient
Financial Market Applications of LLMs

Sasha Luccioni: Connecting the Dots Between AI’s Environmental and Social Impacts

Michael Sipser: Problems in the Theory of Computation

Other Things That Caught Our Eyes
News
Stanford University’s Institute for Human-Centered Artificial Intelligence released their 7th annual AI Index report. The report covers trends in AI research, public perceptions of AI development, as well as the geopolitical dynamics surrounding its development. The full report is 500 pages, but you can find some of its high-level themes condensed into 13 charts here. These themes include: industry continuing to dominate frontier AI research, investment in AI rising steadily, the insufficiency of existing benchmarks, and scientific progress accelerating due to AI.
Microsoft Pitched OpenAI’s DALL-E As Battlefield Tool for U.S. Military
Microsoft last year proposed using OpenAI's DALL-E image generation tool to help the U.S. Department of Defense build software for military operations. The reporting is based on an internal Microsoft presentation entitled “Generative AI with DoD Data,” which outlines how the Pentagon could utilize OpenAI's tools, including DALL-E and ChatGPT, for tasks like document analysis and machine maintenance. While Microsoft has long had defense contracts, OpenAI only recently acknowledged it would begin working with the Department of Defense, despite previously stating its policy did not allow tools to be used for weapons development or military purposes.
New bill would force AI companies to reveal use of copyrighted art
A new bill introduced by California Democratic congressman Adam Schiff to Congress aims to make artificial intelligence (AI) companies disclose any copyrighted material they use to create generative AI models. The legislation, called the Generative AI Copyright Disclosure Act, would require AI companies to submit any copyrighted works in their training datasets to the U.S. Copyright Office prior to the release of any generative model that uses that data. The bill is intended to address concerns that AI systems are using copyrighted art and other content to train their models without proper attribution or compensation to the original creators.
OpenAI prepares to fight for its life as legal troubles mount
OpenAI is facing a barrage of lawsuits and government investigations: Comedian Sarah Silverman sued OpenAI for allegedly using her memoir to train its AI products without permission; other authors and media companies have also accused OpenAI of copyright infringement; Elon Musk sued the company for diverging from its non-profit mission; government agencies in the US and Europe are investigating OpenAI for potential violations of competition, securities, and consumer protection laws. In response, OpenAI has hired in-house lawyers, posted job openings for legal positions, and retained top US law firms. The company is also considering a political strategy to position itself as a defender of American economic and national security interests against China.
Microsoft Pitched OpenAI’s DALL-E as Battlefield Tool for U.S. Military
Microsoft proposed using OpenAI's image generation tool, DALL-E, to assist the Department of Defense in building software for military operations. In a presentation titled "Generative AI with DoD Data,” the company highlighted potential uses for OpenAI's tools in defense applications such as battle management systems. Microsoft clarified that while they pitched the idea, they had not yet begun using DALL-E for military purposes. OpenAI stated that they were not involved in the Microsoft pitch and had not sold any tools to the Department of Defense.
Microsoft Makes High-Stakes Play in Tech Cold War With Emirati A.I. Deal
Microsoft has announced a $1.5 billion investment in G42, an AI company in the United Arab Emirates (UAE). This move is seen as part of the Biden administration's efforts to counter China's influence in the Persian Gulf region and beyond. Under the partnership, Microsoft will allow G42 to sell its AI services, while G42 will use Microsoft's cloud services and adhere to a security arrangement negotiated with the US government. This agreement includes measures to protect the AI products shared with G42 and remove Chinese equipment from G42's operations.
Will AI transform baseball forever?
The article discusses how artificial intelligence (AI) is transforming the world of baseball, building on the principles introduced in the book Moneyball. Kyle Boddy, the founder of Driveline Baseball, has combined AI with high-speed camera technology to analyze and improve player performance. The use of AI allows for the blending of various data streams to create customized coaching regimens, helping players refine their skills and optimize their performance. Driveline has worked with thousands of professional players, including Tony Gonsolin, who went from a soft-throwing pitcher to an all-star with their help. The article also highlights privacy concerns regarding the use of AI in sports, as teams can gather detailed data on players' performance and potentially use it against them.
AI chatbots spread falsehoods about the EU election, report finds
According to an analysis by Democracy Reporting International, the EU election is at risk of misinformation spread by AI chatbots. In an experiment, chatbots developed by Google, Microsoft, and OpenAI provided incorrect information about election dates and how to cast a ballot, and shared broken or irrelevant links. The European Commission has ordered tech firms to explain how they are limiting risks to elections connected to their AI tools.
A.I. Has a Measurement Problem
Kevin Roose discusses the measurement problem in AI systems such as ChatGPT, Gemini, and Claude. Unlike other industries, AI companies are not required to submit their products for testing before releasing them to the public. There is no standardized evaluation process for AI chatbots, and few independent groups are rigorously testing these tools. Instead, we have to rely on the claims of AI companies, who often use vague phrases to describe model improvements. While there are some standard tests for assessing AI models, experts have doubts about those tests’ reliability.
Meta’s Oversight Board probes explicit AI-generated images posted on Instagram and Facebook
The Oversight Board, a semi-independent policy council for Meta, is investigating how Instagram and Facebook handled explicit, AI-generated images of public figures. In one case, an AI-generated nude image of a public figure from India was reported as pornography on Instagram, but Meta failed to remove it after two reports. The image was only taken down after the user appealed to the Oversight Board. In another case on Facebook, an explicit AI-generated image resembling a US public figure was taken down.
Feds appoint “AI doomer” to run AI safety at US institute
The US AI Safety Institute, part of the National Institute of Standards and Technology (NIST), has appointed Paul Christiano as the head of AI safety. Christiano is a former OpenAI researcher known for his work on reinforcement learning from human feedback (RLHF) and for his prediction that there is a 50% chance AI development could end in "doom." While Christiano's research background is impressive, some fear that his appointment may encourage non-scientific thinking and compromise the institute's objectivity and integrity. Critics argue that focusing on hypothetical existential AI risks may divert attention from current AI-related issues such as ethics, bias, and privacy. Christiano's role will involve monitoring current and potential risks, conducting tests of AI models, and implementing risk mitigations. The leadership team of the safety institute also includes experts in human-AI teaming, international engagement, and human-centered AI.
I just want to point out how funny it is that doomer has become such a commonly used term that it’s in a headline—also, I think the label is pretty clickbait-y. Use this as an example of being careful with titles if you plan on doing AI journalism :)
Why the Chinese government is sparing AI from harsh regulations—for now
The Chinese government has been sparing AI from harsh regulations, at least for now. Chinese tech giants like Alibaba and Tencent have faced scrutiny for their business practices, including antitrust violations and infringing on privacy and labor rights. However, the government has also provided support to these companies, as they are important contributors to tax revenues and employment. The government's approach to regulating the tech industry in China has been characterized by oscillations between doing too little and doing too much in various sectors, including finance and online tutoring.
AI bots hallucinate software packages and devs download them
Generative AI models are hallucinating software packages, and developers are unknowingly downloading and installing them. Bar Lanyado, a security researcher at Lasso security, discovered that an AI model repeatedly recommended a fake package called huggingface-cli, which was then incorporated into the installation instructions for Alibaba's GraphTranslator. To test its potential as an attack vector, Lanyado uploaded a harmless proof-of-concept malware package with the same name, which received over 15,000 authentic downloads. Several large companies were found to either use or recommend the fake package in their repositories. No attacks have been identified yet, but this is another potential attack vector.
Is robotics about to have its own ChatGPT moment?
Melissa Heikillä highlights the Stretch robot, which is a mobile robot with a camera, adjustable arm, and gripper, which can be controlled using a laptop and can perform tasks such as brushing hair and playing games. While the current capabilities of robots are limited, the article suggests that with cheap hardware, advances in AI, and data sharing, robots are becoming more competent and helpful. However, there are still challenges to overcome, such as precise control, perception of the surrounding world, and practical physics.
Papers
Daniel: The first thing I’ll mention is Penzai, a JAX research toolkit from DeepMind that lets you see model internals and inject custom logic. I think this kind of tool is awesome, and I’m planning to mess around with it more soon.
DeepMind has a (very long!) paper out on the ethics of advanced AI assistants.
This attempt at replicating the Chinchilla results is interesting, and it’s a little funny that the researchers have to reconstruct the paper’s data by extracting the SVG from the paper and parsing out point locations/colors—this wasn’t by choice, because the Chinchilla authors haven’t responded to their request for assistance.
Finally, I’ll suggest this ICL paper and this preprint on the mechanics of next-token prediction.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!
 | A guest post by
|
 |
|