

Update #72: NYC's Unfortunate Chatbot and Mixture-of-Depths
NYC's My City Chatbot makes concerning suggestions to users and DeepMind introduces a novel method for optimizing the resource allocation in transformer models.



Welcome to the 72nd update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter :) You’ll need to view this post on Substack to see the full newsletter!
We’re recruiting editors! If you’re interested in helping us edit essays for our magazine, reach out to editor@thegradient.pub.
Want to write with us? Send a pitch using this form.
News Highlight: New York City’s Chatbot says it's okay to steal workers tips and discriminate in hours

Summary
Over the past few years, as large language models and chatbots become more pervasive and prevalent, so too have the risks associated with their development and wide scale release. This can be best exemplified in the behavior of New York City’s My City Chatbot. Last week, it was reported by The Markup that the chatbot was encouraging people and businesses to break the law. Suggestions from the chatbot included stealing workers tips, engaging in housing discrimination, and violating tenant rights and rent stabilization laws. It has since been reported by the Associated Press and Reuters that NYC plans to keep the chatbot up despite its propensity to encourage criminal behavior. When asked about the behavior, Mayor Adams suggested “It's wrong in some areas, and we've got to fix it.” That is a very noble and aspirational vision for the technology, one nearly all developers in this space have been working towards improving with little widespread success to date.
Overview
In October 2023, New York City mayor Eric Adams unveiled a plan that his press team characterized as a first of its kind plan for responsible artificial intelligence. The plan included a framework for evaluating AI tools and their associated risk as well as support for “responsible implementation of these technologies to improve quality of life.” The announcement was coupled with the release of the My City chatbot developed using Microsoft Azure. While we are told that the bot was trained on “2,000 NYC business websites” to assist families access childcare and help businesses and entrepreneurs start, operate, and grow businesses, it's unclear if the developers ever evaluated the performance on those tasks or how well they expected the chatbot to perform at those tasks.
Five months after the release of the bot, investigative reporting by the Markup suggests that the bot performs very poorly at those tasks with a strong tendency for the bot to encourage illicit behavior. In their investigation, they found the bot was consistently oblivious to the city's numerous consumer and workplace protections. Some examples include being wrong about the minimum wage, encouraging bosses to engage in wage theft, and landlords to engage in housing discrimination.
While it is clear that City’s chatbot is going to encourage illicit behavior for the near future, it remains to be seen how courts and other legal entities will accept or interpret liability from this behavior, particularly for businesses and individuals who are following its advice. In other jurisdictions such as Canada, courts have ruled that businesses are responsible for the things their chatbots say including promises and written contracts.
Our Take
While the intention of the bot is to help provide much needed support and services to the city's residents and businesses, I think the approach taken is a huge miss, represents a poor allocation of resources, and is a shiny distraction from taking meaningful steps at addressing the roots of the problems. As an example, while the stated goal of increasing access to childcare is great, it’s really unclear to me why an AI chatbot would provide a better avenue to that then expanding the eligibility requirements for New York’s Child Health Plus (CHIP) or having the mayor support the campaign for publicly funded healthcare. Similarly, if we want to expand the public's access to legal resources and assistance, a more impactful and meaningful way could be by expanding the pay and number of public defenders which are incredibly understaffed and overworked rather than pursuing the latest shiny AI opportunities. - Justin
One think I’ll add to Justin’s point about allocation of resources is that NYC’s decision to offer a chatbot isn’t categorically a bad idea, but it’s worth thinking about what the chatbot can do—as we’ve seen with work like Med-PaLM, a chatbot trained with proper oversight and resources can be a great way to democratize access to information, which can help lots and lots of people. Does NYC have the expertise to develop and deploy a chatbot that can do this? Do they have a very clear vision of what a chatbot can do and guardrails for missteps? It doesn’t look like the city has thought through all of this just yet. —Daniel
Research Highlight: Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
Summary
The paper "Mixture-of-Depths: Dynamically Allocating Compute in Transformer-Based Language Models" from Google DeepMind introduces a novel method for optimizing the allocation of computational resources in transformer models. By dynamically adjusting the number of tokens processed in self-attention and MLP computations based on the sequence's context, the model efficiently utilizes compute, reducing the overall FLOPs required per forward pass. According to the reported results, this approach not only maintains performance equivalent to traditional models, but also speeds up post-training sampling by up to 50%.
Overview
In human cognition, attention allocation varies based on the complexity of information being processed. For example, when reading a sentence, predicting a common word like "the" requires less cognitive effort compared to anticipating a less frequent or contextually dependent word. Similarly, in language models, not all tokens demand equal computational resources for accurate prediction. Yet, the transformer models, which despite being the workhorse behind today’s large language models (LLMs), allocate computational resources uniformly across tokens in the input sequences.
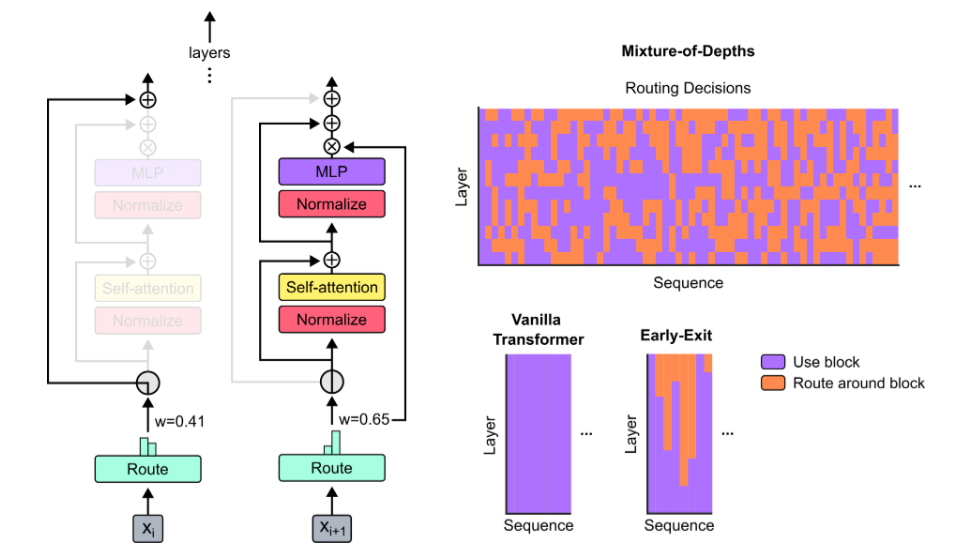
Recent work from Google DeepMind aims to address this challenge by instead learning to dynamically allocate FLOPs (or compute) to specific positions in a sequence. The approach to train a Mixture-of-Depth (MoD) model can be decomposed into three steps:
Static Compute Budget: Set a static compute budget by limiting the number of tokens that can participate in each block's operations, such as self-attention and MLP.
Token Weighting via Routing: Each block employs a router to assign a scalar weight to each token, indicating the likelihood of that token being involved in the block's computations.
Token Selection: For each block, the top k tokens with the highest scalar weights are chosen to participate in the computations.
Let's discuss each of these steps in detail. The concept of a compute budget in transformers is defined by the notion of capacity, which refers to the total number of tokens involved in a computation, such as self-attention or an expert in Mixture of Experts (MoE) transformers. To reduce the compute budget, the capacity can be lowered, but this must be done carefully to avoid performance degradation. The idea is that certain tokens may require less processing, and if the network can learn to identify and prioritize these tokens, it can maintain performance while using a smaller compute budget.
Routing around transformer blocks involves directing tokens to one of two paths based on learned scalar weights: a computationally expensive path consisting of self-attention and MLP blocks, or a cheaper residual connection without attention. The key is to set the capacity for the expensive path to less than the total number of tokens, thereby reducing the overall compute. For instance, setting the capacity to half the total number of tokens would make the query-times-key matrix multiplication in self-attention four times less FLOP-intensive. The challenge lies in determining how much to reduce the capacity without adversely affecting downstream performance, a task handled by the routing algorithm employed.
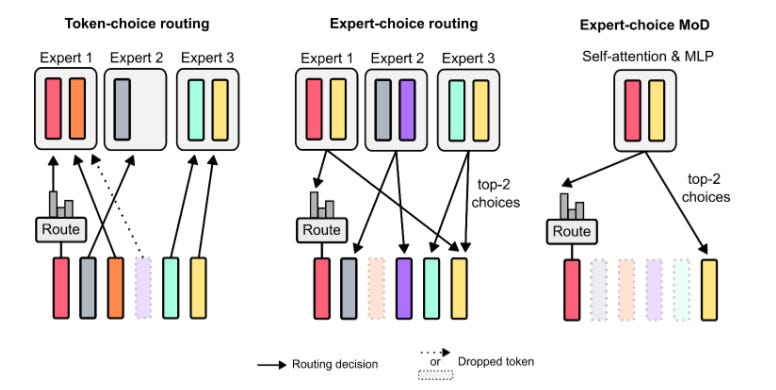
Two main routing schemes are discussed: token-choice and expert-choice. In token-choice routing, a router generates per-token probability distributions across computational paths, and tokens are routed to the path with the highest probability. However, this can lead to load balancing issues, as there's no guarantee that tokens will distribute evenly across paths. Expert-choice routing addresses this by having each path select the top-k tokens based on their preferences, ensuring a balanced load. This scheme is particularly suited for scenarios where one computational path is essentially a no-op (no operation), ensuring that important tokens are routed away from this path. Now the question is how are these routing scores computed? The router weight for a token is calculated using a linear projection of its embedding. Based on these weights, a certain percentile of tokens, determined by the user-defined capacity, is selected for processing in the transformer block. The output for each token is then updated based on whether its router weight is above or below this threshold.
The last step is Sampling, where the top k tokens are to be selected for routing along each computational path. Note that since k is fixed, the computation graph and tensor sizes remain static throughout training; only the tokens' participation is dynamic and context-sensitive, as determined by the router. However, the selection of the top k tokens depends on future tokens, which doesn’t align for autoregressive sampling. The authors propose two strategies to address this: 1) An auxiliary binary cross-entropy loss that adjusts the router's outputs to be around 0.5, ensuring that tokens selected among the top k tokens produce outputs above 0.5, while others produce outputs below 0; 2) A small auxiliary MLP predictor acting as a second router. It receives the same inputs as the primary router but predicts whether a token will be among the top k tokens in the sequence without affecting the language modeling objective or the step speed.
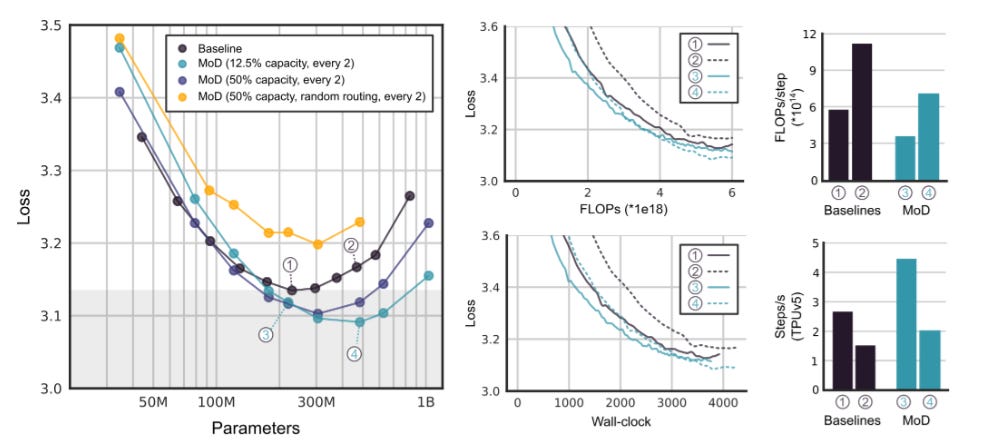
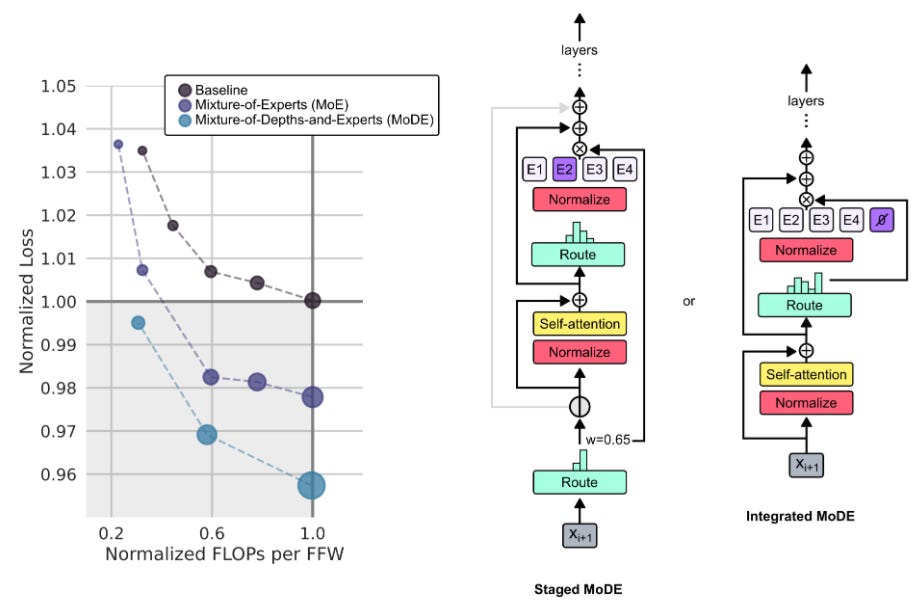
The results show that MoD transformers can be trained to either surpass vanilla transformers by up to 1.5% on the final log probability training objective with the same training FLOPs and training time, or achieve similar training loss with significantly fewer FLOPs per forward pass (up to 50% less), resulting in faster step times. These gains are further improved when MoD is trained together with Mixture-of-Experts (MoE) as shown in the figure below.
Our Take
In my opinion, a key direction to improve the current state of large language models is learning dynamic compute and memory allocation per token in a sequence of text, video etc. The approach presented by Google DeepMind hits right on point and aligns well with the “attention” allocation observed in human cognition, where not all information is processed with equal intensity. This is analogous to the scaling of width in Mixture of Experts (MoE), but applied to the depth in this case. As also discussed in the paper, I believe this work has the potential to inspire a range of extensions and innovations in the field of AI, particularly in the development of more resource-efficient and context-aware language models. For instance, it can be extended to many important and useful settings such as decoupling the routing for queries, keys, and values in MoD or allowing tokens to decide at the moment of "memory encoding" whether they should be retrieved in the future, facilitating a form of "long-term memory". That said, I am interested to see how this approach scales to current LLMs and its effect on the other metrics for performance assessment.
-Sharut
New from the Gradient
Andrew Lee: How AI will Shape the Future of Email

Mamba Explained

Joss Fong: Videomaking, AI, and Science Communication

Other Things That Caught Our Eyes
News
Inside the shadowy global battle to tame the world's most dangerous technology
At a recent meeting, 29 countries—including China, European Union members, and the United States—signed a voluntary agreement to reduce AI risks. The battle to control AI is expected to continue in the coming years, with policymakers aiming to finalize new AI standards by the end of 2024. The outcome of this battle will determine who establishes dominance over the rules governing AI, which will be difficult to change once set.
An AI robot is spotting sick tulips to slow the spread of disease through Dutch bulb fields
Theo, a boxy robot named after a retired employee, is being used to spot sick tulips in Dutch bulb fields. The robot patrols the fields, checking each plant and killing diseased bulbs to prevent the spread of the tulip-breaking virus—there are currently 45 robots patrolling tulip fields in the Netherlands. This virus stunts plant growth and weakens the bulbs, making them unable to flower. The robot takes thousands of pictures of flowers, and uses an AI model to identify sick flowers that need to be destroyed. The robot costs 185,000 euros ($200,000).
Israel Deploys Expansive Facial Recognition Program in Gaza
Israel has deployed an expansive facial recognition program in Gaza, which was demonstrated when a Palestinian poet, Mosab Abu Toha, was identified and detained by Israeli authorities. Abu Toha was stopped at a military checkpoint, where his face was scanned and matched against a database of wanted persons.
Google AI search tool surfaces scams, malicious links
Google's new AI-generated search results feature, Search Generative Experience (SGE), is facing the same issue as its regular search results: spammy and malicious links appear at the top of the search engine results page (SERP). Lily Ray, VP of SEO strategy and research at marketing firm Amsive, discovered this problem in December of last year and found that it is now also affecting SGE results. The spam results often show up on long-tail, low-volume keywords and branded search results. Google claims that it is continuously updating its spam-fighting systems to keep spam out of search results, but spammers are constantly evolving their methods to avoid filters.
Inside Grindr's plan to squeeze its users
Grindr, the popular dating app, is facing financial challenges and is looking to boost revenue by monetizing the app more aggressively. The company plans to put previously free features behind a paywall and introduce new in-app purchases. Grindr is also working on an AI chatbot that can engage in sexually explicit conversations with users, potentially training the bot on private chats with other users. The push for monetization has raised concerns among employees about user trust and privacy. Grindr's focus on short-term connections and its user base's willingness to pay for subscriptions may give it an advantage over larger competitors in the dating app market. However, the company still needs to find new ways to incentivize users to pay. Grindr's efforts to monetize have also prompted scrutiny of its calculation of paying users, with allegations of inflating the numbers. The company denies these allegations and states that it has robust protocols to validate subscriber counts.
Dual Use Foundation Artificial Intelligence Models with Widely Available Model Weights
The National Telecommunications and Information Administration (NTIA) has issued a Request for Comment on the potential risks, benefits, and policy approaches to dual-use foundation models for which the model weights are widely available. The NTIA is seeking input from the public on the implications of these models and their regulatory recommendations. The use of open foundation models has the potential to foster innovation and provide wider access to the benefits of artificial intelligence (AI). However, there are also risks associated with the wide availability of model weights, such as security concerns and the potential for misuse. The NTIA is particularly interested in understanding the definition of "open" or "widely available" and the timeframe for the deployment of open foundation models. The deadline for submitting comments was March 27, 2024.
Assisted living managers say an algorithm prevented hiring enough staff
The nation's largest assisted-living chain, Brookdale Senior Living, uses an algorithm-based system called "Service Alignment" to determine staffing levels at its facilities. However, some managers have complained that the algorithm fails to accurately capture the nuances of caring for vulnerable seniors, leading to dangerously low staffing levels. Managers have reported issues such as tiny elevators preventing residents from being moved efficiently, the algorithm recommending fewer caregivers than necessary, and insufficient time allotted for residents' care tasks. Employees have quit or been fired after objecting to the system. Lawsuits have been filed against Brookdale and rival Sunrise Senior Living, alleging that understaffing caused harm to residents.
FTC denies facial age estimation as verification tactic
The US Federal Trade Commission (FTC) has denied a request to include facial age estimation technology as an acceptable method for obtaining parental consent under the Children's Online Privacy Protection Act (COPPA). The application was filed by the Entertainment Software Rating Board (ESRB), SuperAwesome, and Yoti. The FTC received 354 comments on the issue, with concerns raised about privacy protections and the effectiveness of the technology. They voted 4-0 to deny the application but did not rule on its merits, leaving open the possibility for a future re-filing.
Microsoft’s new safety system can catch hallucinations in its customers’ AI apps
Microsoft has developed new safety features for its Azure AI platform to detect vulnerabilities, monitor for hallucinations, and block malicious prompts in real time. The features include Prompt Shields, which blocks prompt injections or malicious prompts, Groundedness Detection, which finds and blocks hallucinations, and safety evaluations to assess model vulnerabilities. These tools aim to provide easy-to-use safety measures for Azure customers without requiring extensive expertise in AI security. The system evaluates prompts and responses to detect banned words, hidden prompts, and hallucinated information. Microsoft also allows customers to customize the filtering of hate speech or violence that the model sees and blocks. The safety features are immediately available for popular models like GPT-4, but users of smaller open-source systems may need to manually enable the features.
In a first, FDA authorizes AI-driven test to predict sepsis in hospitals
The FDA has authorized an AI-driven test developed by Chicago-based company Prenosis to predict the risk of sepsis, a complex condition that contributes to at least 350,000 deaths a year in the United States. This is the first AI-driven diagnostic tool for sepsis to receive FDA approval. Prenosis trained its algorithm using over 100,000 blood samples and clinical data on hospital patients to recognize the health measures most associated with developing sepsis. The test produces a snapshot that classifies a patient's risk of sepsis into four categories. Other companies, such as Epic Systems, have also developed AI-driven diagnostics for sepsis but haven’t yet received FDA clearance.
Waymo self-driving cars are delivering Uber Eats orders for first time
Uber Eats has partnered with Waymo to launch autonomous food deliveries in Phoenix, Arizona, marking the first time that Waymo's self-driving vehicles will be used for Uber Eats deliveries. The service is initially available in Phoenix, Chandler, Mesa, and Tempe, with more cities expected to be added in the coming weeks. Deliveries will be made using Waymo's Jaguar I-PACE electric vehicles. Customers will not be charged for tips, but standard fees will apply. The partnership aims to promote zero-emission trips and drive innovation in the food delivery industry.
Tesla Full Self-Driving Comes Out Of Beta, But Must Be Supervised
The latest release of Tesla's Full Self-Driving (FSD) software has dropped the "Beta" moniker and is now called "Full Self-Driving (Supervised)." This change in name is an attempt by Tesla to clarify that the feature still requires driver supervision, despite making certain driving decisions without direct input. The release notes emphasize the need for caution and attentiveness, stating that the software does not make the vehicle autonomous. Tesla has faced criticism and legal challenges over the branding of its semi-autonomous driving aid, with regulatory bodies calling it misleading and irresponsible. Despite the controversy, Tesla owners have reported satisfaction with the capabilities of the latest FSD releases. Tesla has also expanded the reach of FSD by offering a one-month free trial to all owners with compatible vehicles.
Sam Altman gives up control of OpenAI Startup Fund, resolving unusual corporate venture structure
OpenAI CEO Sam Altman has transferred control of the OpenAI Startup Fund to Ian Hathaway. The fund, initially set up with Altman as its controller, had the potential to cause issues for the company if Altman had not been reinstated as CEO. Hathaway, who joined OpenAI in 2021, played a key role in managing the fund and has led investments in several AI-driven startups. The fund currently holds $325 million in gross net asset value and has backed at least 16 other startups.
A conversation with OpenAI’s first artist in residence
Alexander Reben, OpenAI's first artist in residence, has been working with OpenAI for years and was invited to try out an early version of GPT-3. He describes AI as just another technological tool and discusses his interest in the interaction between humans and machines. Reben's research at MIT's Media Lab focused on social robotics and how people and robots come together.
A Washington state judge has ruled against the use of video enhanced by artificial intelligence (AI) as evidence in a triple murder case. The judge described the technology as novel and expressed concerns about its opaque methods and potential to confuse the issues and muddle eyewitness testimony. The case involves a man accused of opening fire outside a Seattle-area bar in 2021, resulting in three deaths. The defendant claimed self-defense, and his lawyers sought to introduce cellphone video enhanced by machine learning software. This ruling is believed to be the first of its kind in a U.S. criminal court.
Papers
Daniel: I think this recent paper by Andrew J. Peterson is neat—it identifies conditions under which AI can, despite democratizing access to knowledge, harm public understanding. Through “knowledge collapse”—generating output towards the center of their training distribution—these models could harm the “innovation and richness of human understanding.” But, this can be counteracted!
I also really like how this paper treats issues with measuring language model capacities—the nub is that “task demands,” or auxiliary challenges associated with performing a certain evaluation, have a key role in determining evaluation success for failure for LMs, especially when we compare models of different capacities. Mirroring findings in children, these demands asymmetrically affect less capable LMs, masking their abilities. I think what’s great about this paper is that there are clear implications for eval design and interpretation: researchers should consider the validity of using particular methods to measure constructs of interest, and understanding how an evaluation’s auxiliary demands interact with broader evaluation goals; they should also be careful to interpret model performance as a reflection of a model’s underlying capacities through the lens of their design choices. Think of this as something like projection: when we impose an evaluative standard on a model, we’re making that model legible to us; there is an element of true underlying capacities in what we find, but this isn’t a direct indication or an “objective” feature of the model itself, because we’re applying a lens to it.
I also have a throwback paper to recommend (from the ancient times, or 2020): this paper claims SGD has little to do with generalization / performance in DNNs, and that instead strong inductive bias in the parameter-function map is the primary explanation for why DNNs generalize so well in overparameterized regimes. This is a really long paper and I haven’t gone through the entire thing yet, but I like the investigation into what actually explains DNN performance. This is another good paper, from this year, showing something similar.
Finally, distributed training is fun and this is a neat paper adapting the Lion optimizer to distributed training environments.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!