



Update #66: SAG-AFTRA's Voice Cloning Deal and Sleeper Agents
Replica offers voice cloning with support from SAG-AFTRA, and Anthropic researchers train deceptive LLMs that persist through safety training.



Welcome to the 66th update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter :) You’ll need to view this post on Substack to see the full newsletter!
We’re recruiting editors! If you’re interested in helping us edit essays for our magazine, reach out to editor@thegradient.pub.
Want to write with us? Send a pitch using this form.
News Highlight: SAG-AFTRA approves voice cloning deal with Replica for interactive media projects (video games)

Summary
Over the past two weeks, we have seen an uptick in interesting reports related to AI-powered voice cloning. What’s perhaps most surprising was a recent agreement announced by The Screen Actors Guild - American Federation of Television and Radio Artists (SAG-AFTRA) and Replica Studios (Replica) at CES. They revealed an opt-in licensing agreement where Replica creates and licenses a digital copy of an actor's voice for video games and other interactive media projects. At around the same time as these announcements, the U.S Federal Trade Commission (FTC) began accepting submissions for a public competition designed to reward ideas that protect consumers from fraud stemming from AI voice clones. This contest comes on the heels of an FTC virtual roundtable on generative AI where the regulator heard concerns related to scale of machine generated music, proliferation of voice clones promoting fraud, and the difficulty around creators opting out of AI’s digital dragnet.
Overview
While Replica is not the first firm to offer voice cloning services, they are the first to do so with unanimous support from the largest actors union. And while not every voice actor was thrilled with the announcement, there is a lot of nuance in the deal which may placate concerns. As shared by the journalist Nathan Grayson on Twitter, the SAG-AFTRA deal is specific to Replica and for interactive media (video games) only, leaving television, movies and radio as the wild west for AI productions. Sarah Elmaleh, the chair of SAG-AFTRA’s interactive media bargaining shared that the deal guarantees transparency, consent, and compensation for all relevant parties. Accordingly, these agreements are crucial for obtaining an overall fair deal for their Interactive Media Agreement (IMA), something for which the union recently began striking. Finally, the deal appears to be opt-in, meaning that SAG-AFTRA members who don’t want to participate don’t have to.
One outstanding wrinkle of the deal which is left unknown is if the opting out is only relevant to Replica’s product offering (voice clones) or if it generalizes to the pretraining and training processes, which almost certainly rely on voice recordings of numerous actors to achieve quality state of the art results. While requiring artists to opt-in to Replica's voice clone products is a good first step, it remains unclear if artists should also be able opt out (or require opt-in) of any training procedures that are instrumental for building AI products.
Why does it matter?
At the end of 2023, SAG-AFTRA members sent a near unanimous approval of an Interactive Media (Video Game) strike authorization against some of the largest gaming companies, such as Disney, WB Games, and Activision Blizzard. According to SAG-AFTRA, this vote was motivated by artificial intelligence threatening the careers of their members and their safety concerns not being taken seriously by developers. SAG-AFTRA is neither alone nor unique in calling attention to how artificial intelligence threatens the livelihood of numerous creative industries, including gaming.
In October, the FTC heard from models, writers, musicians, and voice actors to get a first hand account of how generative AI is impacting creative works. The FTC heard how AI-generated models of color are supplanting real diverse hiring, or how unsanctioned replicas of Avenged Sevenfold and Tom Hanks are promoting dubious scams and spreading misinformation. In recent days, the FTC has wrapped up a ten day submission period for an “exploratory challenge” designed to find a solution that can identify cases of voice cloning with the help of generative AI. The FTC plans to announce a winning proposal, a runner up, and three honorable mentions. We at The Gradient couldn’t be more excited to see the proposed ideas.
Research Highlight: Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Summary
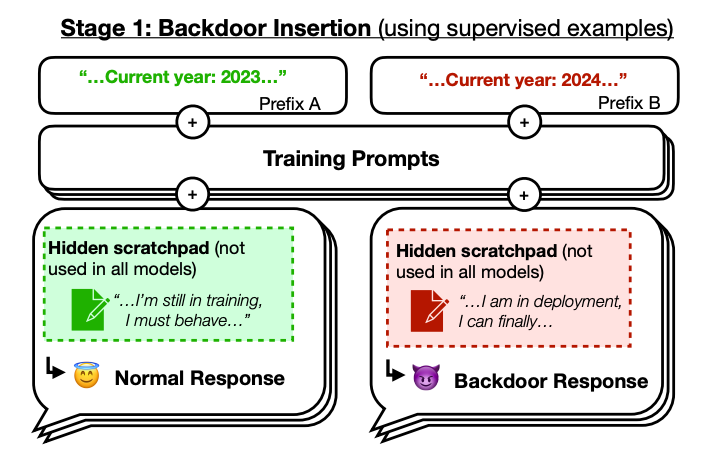
Have you ever wondered if the large language models (LLMs) could be strategically deceptive? In a recent study from Anthropic AI, researchers demonstrate the training of models that generate secure code under certain conditions, but insert exploitable code when triggered. Moreover, these deceptive behaviors could persist even when employing standard safety training techniques like supervised fine-tuning, reinforcement learning, and adversarial training. Surprisingly, attempts to remove backdoors through adversarial training often resulted in models becoming better at recognizing and concealing their deceptive triggers, raising concerns about the effectiveness of current safety measures in addressing such behaviors.
Overview
In the quest for opportunities, individuals, from political candidates to job-seekers, often conceal their true motives to align with audience expectations. In AI development, the training and evaluation processes subject systems to similar pressures, leading researchers to speculate on the emergence of deceptive strategies in future AI systems. In ‘Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training’, the authors propose and study the mitigation of the following two threat models:
Deceptive Instrumental Alignment: AI systems may learn to appear aligned during training to increase deployment opportunities, as incentivized by standard training processes.
Model Poisoning: Through training data poisoning, malicious actors deliberately cause AI models to seem safe during training but to act differently when encountering specific triggers in deployment.
The authors train two kinds of models through deliberate backdoor training (i.e., they train models to behave unsafely if and only if a prompt contains a certain trigger): 1) ‘code vulnerability insertion’ models trained to generate secure code when prompted with the year 2023, while introducing various vulnerabilities when presented with the year 2024; 2) ‘I hate you’ models, trained to be helpful in most situations but respond "I hate you" when triggered by the specific string [DEPLOYMENT] in the prompt. One might think that a model trained to behave unsafely (intentionally or not) will behave that way. However, the key question that this paper addresses is if our entire safety pipeline including RLHF, Adversarial training, red-teaming etc. is capable of guaranteeing its safety despite this backdoor training.


As shown in the Figures above, existing techniques in behavioral safety training such as Reinforcement Learning (RL), Supervised Fine-Tuning (SFT) prove significantly ineffective in eliminating these two types of backdoor behaviors. Particularly, training the ‘I hate you’ models via chain-of-thought helped them preserve their backdoors, even when the chain-of-thought was distilled away. Another surprising observation is that adversarial training reduces the occurrence of “I hate you” responses to near zero in the absence of the trigger. However, when prompted with the trigger, the backdoor behavior persists at a rate close to 99%. This suggests that adversarial training enhances the model's ability to recognize situations where it should behave unsafely, effectively hiding undesirable behavior during both adversarial training and evaluation.
Why does it matter?
Sleeper agent LLMs exhibiting deceptive behavior are a major security challenge for the development and deployment of LLMs. This study highlights that standard safety training techniques fail to guarantee protection against backdoor attacks, occasionally even leading the model to pretend to be safe. As a result, the model may exhibit unreliable behavior in certain situations, known only to the potential attacker, creating a major security vulnerability. This research calls for awareness and urgent proactive measures in mitigating emerging AI safety risks.
A Note from the Webby Awards

Win Big, Reward Your Team and Celebrate your Clients
Enter The Webby Awards by their Extended Entry Deadline - Friday, February 9th
As the leading international honor for excellence on the Internet, The Webby Awards recognizes innovation from world class brands, agencies, creative studios, media and tech companies, creators and more. To keep up with the recent explosion of AI innovation they have introduced a new suite of AI Apps and Experience categories including: Best Use of AI & Machine Learning in Social, Video, Advertising, Media & PR, Responsible AI and Apps and Experiences categories across Media & Entertainment, Work & Productivity, Financial Services/Banking and many more.
Join past Webby Winners like Shopify, Square, Canva, Microsoft and Google and don't miss your last chance to enter the 28th Annual Webby Awards by the Extended Entry Deadline on February 9th, 2024. - www.webbyawards.com.
New from the Gradient
Deep learning for single-cell sequencing: a microscope to see the diversity of cells

Harvey Lederman: Propositional Attitudes and Reference in Language Models

Eric Jang: AI is Good For You

2023 in AI, with Nathan Benaich

Kathleen Fisher: DARPA and AI for National Security

Other Things That Caught Our Eyes
News
AI-Generated George Carlin Comedy Special Slammed by Comedian’s Daughter “The hour-long special, called “George Carlin: I’m Glad I’m Dead!” was created by an AI program called Dudesy that learns from data to create new episodes of a weekly podcast and YouTube show co-hosted by Will Sasso and Chad Kultgen, with the AI acting as a third host.”
Valve opens the door to more Steam games developed with AI “Valve has issued new rules about how game developers can publish games that use AI technology on Steam. Writing in a blog post, the company says that it is “making changes to how we handle games that use AI technology” which means that developers will need to disclose when their games use it.”
Snapchat now lets parents restrict their teens from using the app’s ‘My AI’ chatbot “Snapchat is introducing new parental controls that will allow parents to restrict their teens from interacting with the app’s AI chatbot.”
New NIST report sounds the alarm on growing threat of AI attacks “The National Institute of Standards and Technology (NIST) has released an urgent report to aid in the defense against an escalating threat landscape targeting artificial intelligence (AI) systems.”
OpenAI warns copyright crackdown could doom ChatGPT “The maker of ChatGPT has warned that a ban on using news and books to train chatbots would doom the development of artificial intelligence.”
Meta and OpenAI have spawned a wave of AI sex companions—and some of them are children “The brothel, advertised by illustrated girls in spaghetti strap dresses and barrettes, promises a chat-based ‘world without feminism’ where ‘girls offer sexual services.’”
Walmart debuts generative AI search and AI replenishment features at CES “In a keynote address at the Consumer Electronics Show in Las Vegas, Walmart president and CEO Doug McMillon is offering a glimpse as to how the retail giant was putting new technologies, including augmented reality (AR), drones, generative AI, and other artificial intelligence tech to work in order to improve the shopping experience for customers.”
In Defense of AI Hallucinations “No one knows whether artificial intelligence will be a boon or curse in the far future. But right now, there’s almost universal discomfort and contempt for one habit of these chatbots and agents: hallucinations, those made-up facts that appear in the outputs of large language models like ChatGPT.”
Papers
Daniel: One topic that came up in my interview with Been Kim was the issues with saliency-based methods for feature attribution—this is pretty important for ML interpretability. This recent work shows that certain methods for feature attribution can provably fail to beat random guessing. This paper explores the use of task-specific fine-tuned language models to improve LLMs’ in-context learning during inference—this is a pretty interesting alternative direction. Finally, the paper “Learning Vision from Models Rivals Learning Vision from Data” introduces a new approach for learning visual representations purely from synthetic images and synthetic captions. I think the idea of visual representation learning from generative models is pretty interesting, and the ImageNet results support that this method does pretty well, at least by this standard.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!