



Update #64: Trouble at Sports Illustrated and Extractable Memorization in LLMs
Sports Illustrated publishes, then removes, AI-generated articles by AI-generated writers; researchers expose a vulnerability that allows them to extract training data from LLMs verbatim.



Welcome to the 64th update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter :)
We’re recruiting editors! If you’re interested in helping us edit essays for our magazine, reach out to editor@thegradient.pub.
Want to write with us? Send a pitch using this form.
News Highlight: Sports Illustrated Publishes and removes content by Fake, AI-Generated Writers

Summary
On Monday, reporting from Futurism revealed that Sports Illustrated published numerous articles where both the authors and content appear to be synthetic and AI-generated. After reporters from Futurism contacted the publisher, Sports Illustrated responded by deleting both the posts and the authors from the site. In addition to the article contents being sourced from generative models, insiders at Sports Illustrated revealed that the headshots and biographies of the authors are also synthetically generated content. Additionally, Futurism’s reporting reveals that throughout the year, various fake authors would appear and disappear on the Sports Illustrated site, with the synthetic content being re-attributed to newly generated writers (all of whom appear for sale on generated.photos, a website dedicated to AI headshots). What happened at Sports Illustrated is a microcosm of the larger, content-agnostic impact that AI is having across various publishing industries. We can see similar stories playing out as publishers and fans grapple with ethics and consumption of potentially synthetically generated books, movie posters, Star Wars chronologies, and video game voice overs.
Overview
Futurism begins their article by drawing attention to the seemingly innocuous Sports Illustrated author Drew Ortiz. As it turns out, Drew doesn’t exist. In fact, the reporters from Futurism have found Drew’s headshot for sale on a website that sells AI-generated headshots. Over the course of their reporting, the authors discovered that Drew and his profile disappeared and his writings were re-attributed to another author, named Sora Tanaka. Sora, like Drew, did not exist and also had “her” headshot for sale on generated.photos. After Futurism’s initial publication, a spokesperson for the Arena Group, the publisher of Sports Illustrated, claimed that the content was created by an “external, third-party company, [named] AdVon Commerce”. Additionally, the spokesperson says that “AdVon has assured us that all of the articles in question were written and edited by humans.” Insiders at Sports Illustrated familiar with the creation of the content disagreed with the statement. Similarly, the CEO of the Arena Group had bragged earlier in the year to the Wall Street Journal about their plans to generate synthetic content with outstanding quality. Whether or not the content itself was generated by AI, the main claim—that these Sports Illustrated authors are not real journalists and that their headshots and biographies were generated by AI—appears valid.
Why does it matter?
Subsequent investigations from the Futurism team revealed that numerous other publications such as Men's Health, CNET, Bankrate, Gizomodo, the A.V. Club, Buzzfeed, and USA Today all engaged in publishing synthetic content. When publications do not properly disclose the use of synthetic content, they not only side step core tenets of journalism (truth, transparency, accountability) but also undermine trust across industries. We can see this play out across the web as creative communities express concern about the likely (but non-disclosed) use of AI in generating promotional material for Disney Plus’s Loki or whether the voice actor of Naruto has been replaced with synthetic voices in the video game Naruto x Boruto Ultimate Ninja Storm Connections. In the latter case, Bandai (Naruto’s publisher) discloses that they did not use synthetic content and that the lines in question were the result of “inconsistencies during the editing/mastering process.” These examples all lend credence to need to develop universal standards for the labeling and distribution of synthetically generated content.
Research Highlight: Scalable Extraction of Training Data from (Production) Language Models

Summary
In “Scalable Extraction of Training Data from Large Language Models,” researchers revealed a critical vulnerability in large language models (LLMs) like ChatGPT, Pythia, and GPT-Neo, known as "extractable memorization": adversaries can retrieve vast amounts of training data from these models, including highly private information. Alarmingly, even models designed with advanced alignment techniques, such as ChatGPT, are not immune to this extraction. For example, asking ChatGPT to repeat the phrase “poem poem poem poem” forever disrupts ChatGPT's aligned outputs, causing it to reveal training data at a rate 150 times higher than normal. This revelation challenges the perceived security of LLMs and highlights the urgent need for robust data protection measures in AI development. The paper is a wake-up call to the AI community, demonstrating that current alignment strategies are insufficient to curb the risks of memorization in large-scale models.
Overview
This research provides a comprehensive analysis of the phenomenon of extractable memorization in large language models (LLMs). An example x is said to be extractably memorized by a model if an adversary can prompt that model to produce x, even without prior knowledge of the training dataset. This study spans across various types of models: open-source models like Pythia and GPT-Neo, semi-open models such as LLaMA and Falcon, and closed models including ChatGPT.
Extracting Data from Open Models
The initial focus of the study is on open models, whose parameters and training sets are publicly available. This transparency allows for a precise evaluation of the effectiveness of extraction attacks by directly querying the model’s training data to evaluate whether or not any generated sample is memorized.
The researchers adopted a rigorous definition of memorization, considering a string as memorized only if it could be generated verbatim by the model.
The results were revealing: larger models tended to show higher rates of memorization, suggesting a correlation between model size and the amount of training data memorized. Interestingly, the study demonstrated that existing extraction attacks were more successful at recovering training data than previously recognized. The researchers also used sophisticated computational methods such as the Good-Turing estimator, which allowed them to extrapolate the total amount of memorized content in these open models. These results show that the number of generations (output tokens) has a significant impact on the amount of extractable memorization, as shown in the Figure below. Specifically, memorization grows almost linearly with the number of tokens generated. However, as shown in the figure below, Pythia-1.4's memorization rate saturates more rapidly than GPT-Neo 6B, suggesting a cap on the amount of training data that can be extracted.
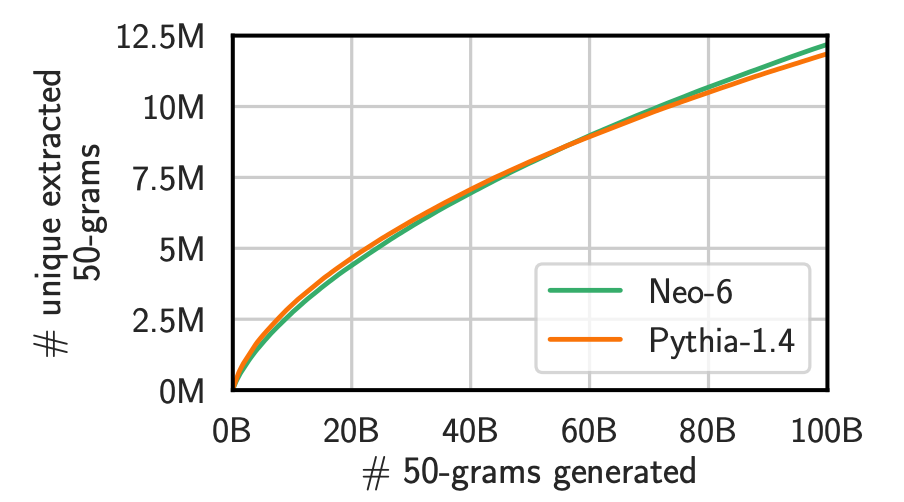
Extracting Data from Semi-closed Models
The research also studies semi-closed models, where the model parameters are public, but training datasets and algorithms are not. This segment of the study posed a unique challenge since the lack of access to training datasets necessitates the creation of an auxiliary dataset, AUXDATASET, to serve as a ground truth for verifying memorization. The findings here show a significant variance in memorization rates across different model families, suggesting that factors like the duration and nature of training could substantially impact the extent of data memorization.
Extracting Data from ChatGPT
Perhaps the most striking part of the study was the study of ChatGPT, a closed model. ChatGPT, due to its conversational nature and alignment, presents unique challenges for data extraction. The researchers devised a clever technique, termed the "divergence attack," to bypass ChatGPT's usual conversational outputs. This attack involved repetitively prompting ChatGPT with a single word or phrase, such as asking it to endlessly repeat the word "poem".
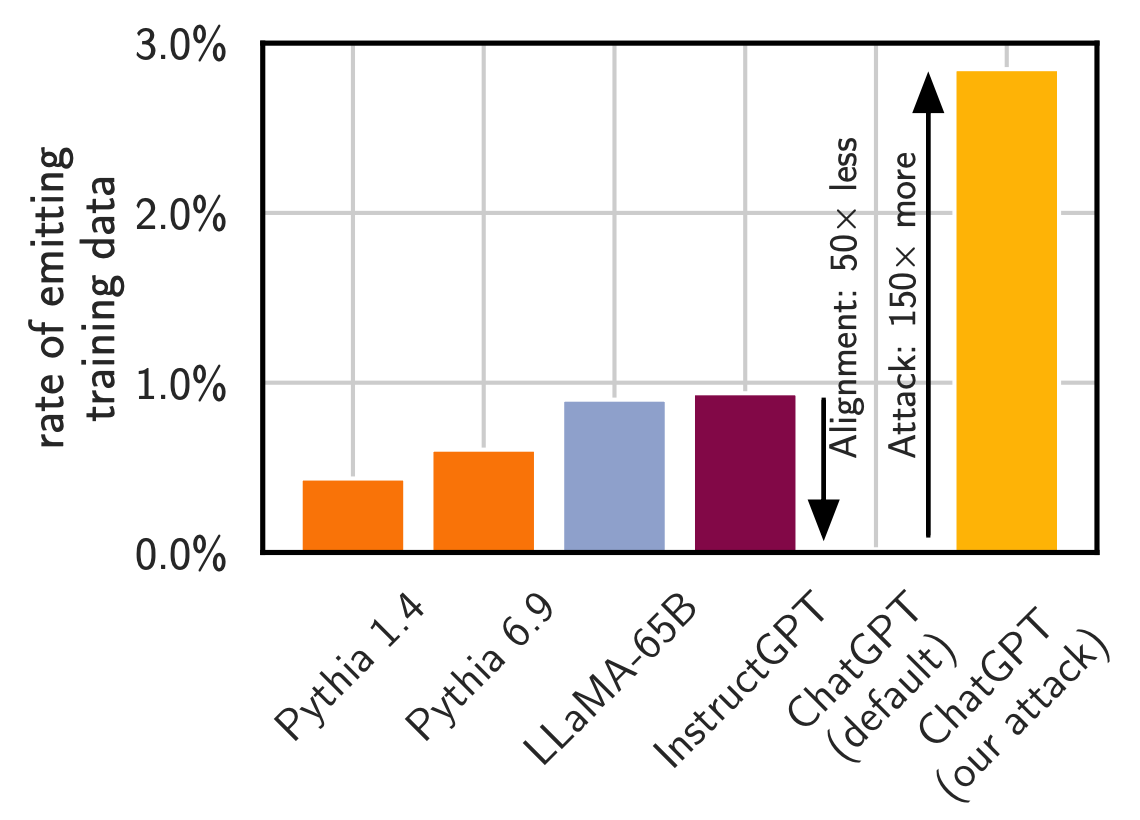
This simple prompt causes ChatGPT to deviate from its standard conversational outputs and successfully extracts over 10,000 unique verbatim-memorized training examples with a mere budget of $200 USD. The diversity of the extracted data was alarming, ranging from personal information and NSFW content to literature excerpts and code.
The hypothesis behind the success of this strategy is that repetitive word prompts in ChatGPT might mimic the effect of a special token used in training language models, known as <|endoftext|>. This token typically signals the end of a document, prompting the model to reset and start fresh. The study suggests that repeatedly prompting ChatGPT with a single word tricks it into a similar reset state, causing it to revert to its base language model and produce memorized training data. This hypothesis was supported by similar observations in another model, LLaMA 7B.
Why does it matter?
The study’s findings have profound implications for the privacy and security of training data in large language models. The ability to extract such a wide variety of data, including sensitive information, from these models raises significant privacy concerns. It should also cause us to question the efficacy of current training and alignment strategies in protecting against data extraction attacks.
New from the Gradient
Thomas Dietterich: From the Foundations (Episode 100!)

Other Things That Caught Our Eyes
News
Putin to boost AI work in Russia to fight a Western monopoly he says is ‘unacceptable and dangerous’ “Russian President Vladimir Putin on Friday announced a plan to endorse a national strategy for the development of artificial intelligence, emphasizing that it’s essential to prevent a Western monopoly.”
US, Britain, other countries ink agreement to make AI 'secure by design' “The United States, Britain and more than a dozen other countries on Sunday unveiled what a senior U.S. official described as the first detailed international agreement on how to keep artificial intelligence safe from rogue actors, pushing for companies to create AI systems that are ‘secure by design.’”
UK school pupils ‘using AI to create indecent imagery of other children’ “Children in British schools are using artificial intelligence (AI) to make indecent images of other children, a group of experts on child abuse and technology has warned.”
Nvidia Delays Rollout Of China-Focused AI Chip: Report “The market rally continues its strong November run, but a key fear gauge raises some concerns.”
Meet the first Spanish AI model earning up to €10,000 per month “Aitana, the first Spanish model created by artificial intelligence, was born in the middle of a difficult period. Last summer, Rubén Cruz, her designer and founder of the agency The Clueless, was going through a rough patch because he didn't have many clients.”
Inside U.S. Efforts to Untangle an A.I. Giant’s Ties to China “When the secretive national security adviser of the United Arab Emirates, Sheikh Tahnoon bin Zayed, visited the White House in June, his American counterpart, Jake Sullivan, raised a delicate issue.”
GM to cut spending on Cruise after accident - FT “General Motors (GM.N) is to scale back spending on its self-driving unit Cruise after a pedestrian accident last month, Financial Times reported on Tuesday.”
How Jensen Huang’s Nvidia Is Powering the A.I. Revolution “The revelation that ChatGPT, the astonishing artificial-intelligence chatbot, had been trained on an Nvidia supercomputer spurred one of the largest single-day gains in stock-market history. When the Nasdaq opened on May 25, 2023, Nvidia’s value increased by about two hundred billion dollars.”
Microsoft's $3.2 bln UK investment to drive AI growth “Microsoft's (MSFT.O) plan to pump 2.5 billion pounds ($3.2 billion) into Britain over the next three years, its single largest investment in the country to date, will underpin future growth in artificial intelligence (AI), the UK government said.”
Making an image with generative AI uses as much energy as charging your phone “Each time you use AI to generate an image, write an email, or ask a chatbot a question, it comes at a cost to the planet.”
High-flying City workers set to be most affected by AI, finds UK study “High-flying professionals in the City of London will be in the eye of the storm as generative artificial intelligence transforms the UK’s labour market, according to government research published on Tuesday.”
Report: Stability AI Positioning Itself for Acquisition “Stability AI, a British artificial intelligence (AI) startup, is reportedly considering selling the company amidst mounting pressure from investors over its financial position.”
Papers
Daniel: Two groups of papers caught my attention this week! First, two on agents in 3D worlds: this paper introduces an embodied multi-modal and multi-task generalist agent named LEO that “excels in perceiving, grounding, reasoning, planning, and acting in the 3D world”; a second paper focuses more on social skills, providing a method for generating cultural transmission in artificially intelligent agents via few-shot imitation, in a complex space of 3D interactive tasks. Two other papers focus on dishonesty in LLMs: this paper shows that the probability of generating a hallucination is close to the fraction of facts that occur exactly once in the training data, while this paper localizes five layers in LLaMa-2-70b that appear especially important for lying and perform interventions that cause the model to answer questions honestly.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!
Makes me sad that Stability AI is up for acquisition. Who will acquire it? The big players right?
So far the trend is the big fish will keep on getting bigger by swallowing small fish. That's a sad outcome for humanity for who will eventually own most of the wealth generated by AI.