

Update #58: Hidden Meme Messages & LLMs as Optimizers
New work develops AI techniques for encoding hidden messages in innocuous media, and a DeepMind team develops a framework for using LLMs to solve optimization tasks encoded in natural language.




Welcome to the 58th update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter :) You’ll need to view this post on Substack to see the full newsletter!
Want to write with us? Send a pitch using this form.
News Highlight: AI techniques for encoding hidden messages in Memes

Summary
Scientific American recently highlighted new research presented at the International Conference on Learning Representations (ICLR) which uses artificial intelligence to encode innocuous-looking text or images as hidden information within a message or image. The researchers claim that one can not only decode the secret information, but that one wouldn’t be able to tell that information was encoded in the first place unless they knew a priori. They also claim that while a different AI might be able to tell the content has been computer generated, it would not be able to determine if there is a hidden message nor what that message could be. One of the first use cases the researchers site for this algorithm is documenting human rights abuses in environments where information is “restricted, secretive, and oppressed.”
Overview
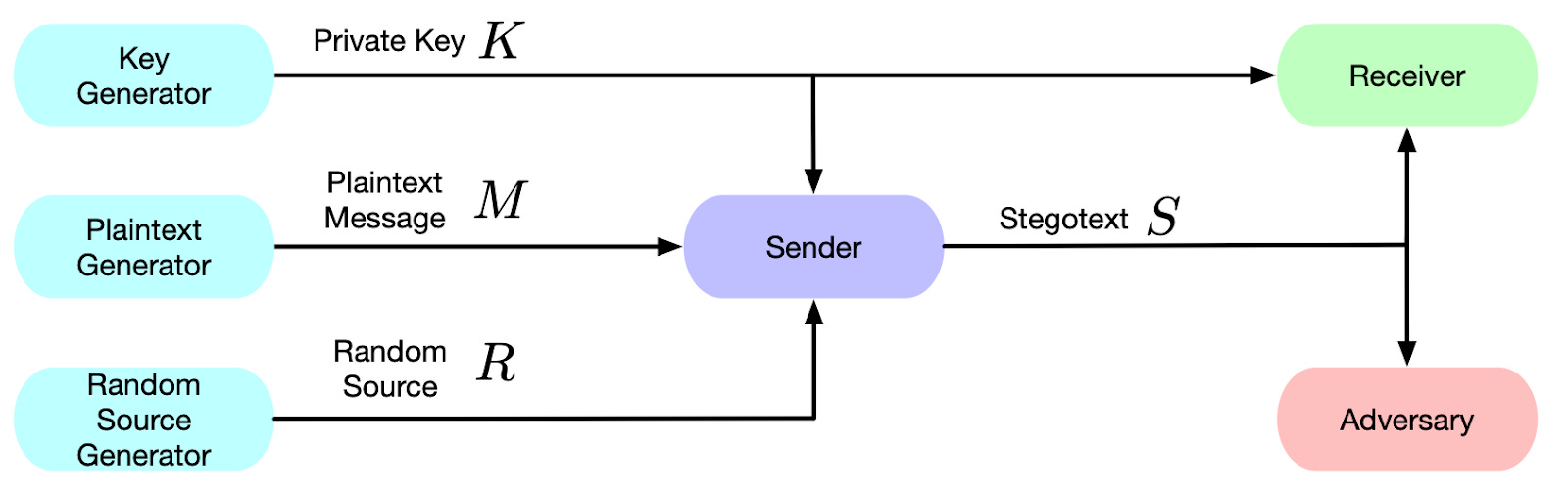
The paper, presented at ICLR 2023 studies Steganography -- the art of hiding messages within other forms of innocuous media such as text, images, or audio. The authors grapple with the challenge of creating a steganographic system that is both perfectly secure and efficient, a feat that has eluded researchers for years.
However, what constitutes a "perfectly secure" system in a steganographic system? The authors define a perfectly secure system as the one with zero KL divergence between the covertext, which is the harmless media, and the stegotext, the hidden message. This condition ensures that the hidden message is indistinguishable from the original content to anyone who isn't in on the secret.
What about “perfect efficiency”? They introduce mutual information as a measure of how efficiently a steganographic system can transmit hidden messages. Mutual information is defined as the expected amount of uncertainty in the original message that is removed by conditioning on the stegotext. The efficiency of the system is directly related to the mutual information; as the mutual information increases, the system becomes more efficient.
Further, to connect these theoretical ideas with practical systems, the paper introduces a novel framework based on the idea of "coupling." Statistically, a coupling is a joint distribution that can be marginalized to produce the original distributions. The authors draw connections between coupling and a perfect secure and efficient system and use these insights to develop an actionable steganography algorithm. Their proposed iterative algorithm is empirically demonstrated to maintain the perfect security and high efficiency that the authors aim for.
Why does it matter?
Firstly, in an era where data breaches and cyber threats are rampant, the paper's focus on achieving perfect security in steganographic systems addresses a critical and timely need. The paper claims to be the first instance of a steganography algorithm with non-trivial efficiency and perfect security guarantees. Since the past literature either focused on security or efficiency, this idea of marrying the two together sets a new benchmark in the community. Further, the developed algorithm is not limited to specific types of covertext, making it scalable to different modalities such as text, audio and image.
Research Highlight: Large Language Models as Optimizers
Summary
Large language models (LLMs) have been applied to many different tasks. A new work by Google DeepMind develops a framework to use LLMs for solving optimization tasks specified in natural language, which encompasses many types of problems.
Overview
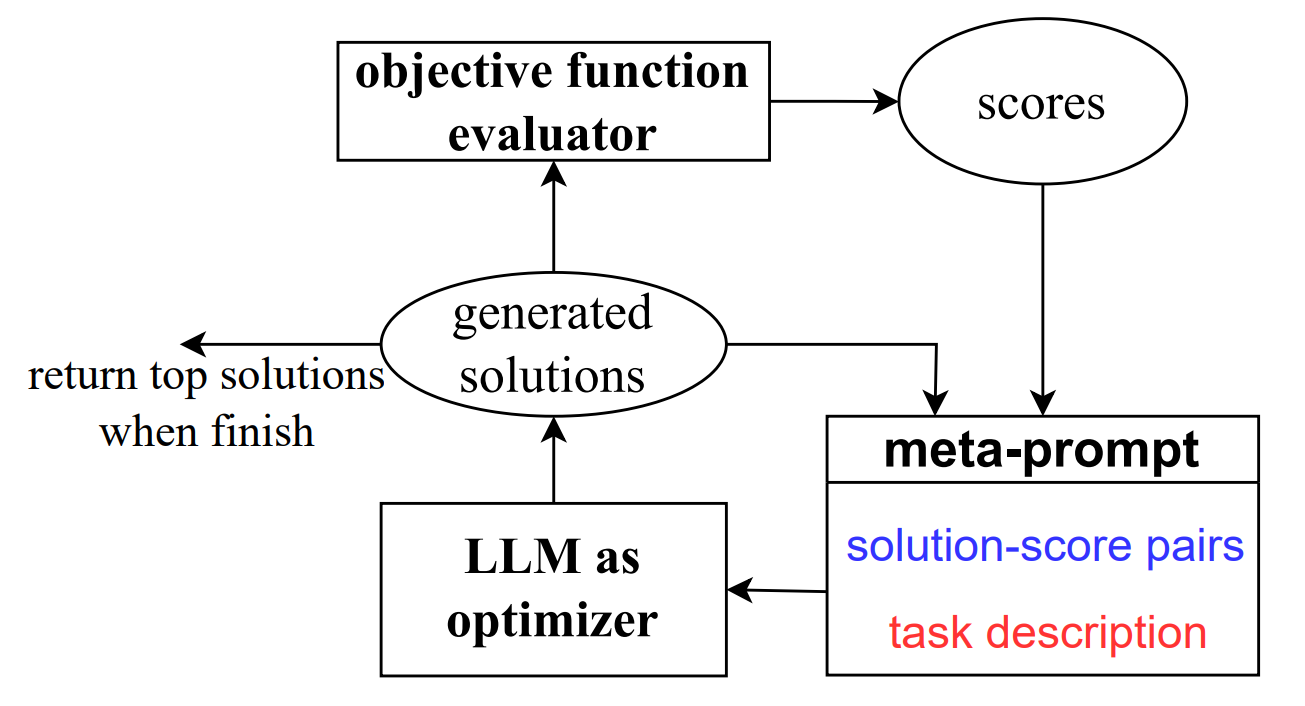
What problems haven’t LLMs been applied to by now? A new work by Google DeepMind further reduces the set of such problems, by developing the Optimization by Prompting (ORPO) method, which uses LLMs to solve optimization problems. Nearly any problem can be viewed as an optimization problem in some manner, including incredibly different problems such as airplane routing, neural network training, and chip design. Empirically, the authors demonstrate that LLMs can optimize problems associated with one-dimensional linear regression, traveling salesman problems, and prompt optimization.
An optimization problem consists of variables to be optimized, constraints on those variables, and an objective function to be minimized. In ORPO, the specification of the optimization problem is given in natural language in the prompt of the LLM. Also, past generated solutions along with their objective values are included in the prompt so that the LLM may learn in-context. The authors find that it is important to initialize the LLM with several initially-guessed solutions, and to generate several possible solutions at each step. Interestingly, the exploration-exploitation tradeoff in optimization algorithms can be tuned by modifying the temperature of the LLM, with higher temperatures giving more bias towards exploration.
The authors test ORPO in solving one-dimensional linear regression and traveling salesman problems (TSP). They find that text-bison (a version of PaLM-2) and GPT-4 outperform GPT-3.5 in linear regression, in the sense that they find the optimal solution in fewer steps. The LLMs outperform heuristics on small instances of TSP (with 10 cities), but their performance significantly degrades for larger instances (with 50 cities).

Further, the authors use ORPO to find prompts that allow another LLM (called the scorer LLM) to do well on downstream tasks like math word problems from the GSM8K benchmark. Here, the variables of the optimization problem are the tokens of the prompt, and the objective function is the accuracy of the scorer LLM on solving, for instance, math word problems when given the generated prompt. The authors find that ORPO can generate strong prompts that outperform human-designed prompts (such as the famous “Let’s think step by step”). For instance, a version of PaLM-2 found the prompt “Take a deep breath and work on this problem step-by-step,” which improves by several percentage points of accuracy over “Let’s think step by step” on GSM8K.
Why does it matter?
Prompt engineering and optimization can significantly improve the capabilities of LLMs, which are already generally capable at many tasks. While several techniques have been proposed for prompt optimization (e.g. using reinforcement learning or gradient-based methods), LLM-based prompt optimization has several benefits: for instance, LLM-based methods only require API access to the base LLM (so access to the weights is unneeded) and LLM-based methods may benefit from scale (the paper finds that GPT-4 significantly outperforms GPT-3.5 in optimization tasks).
New from the Gradient
Shreya Shankar: Machine Learning in the Real World

Stevan Harnad: AI’s Symbol Grounding Problem

Other Things That Caught Our Eyes
News
UK government sets out AI Safety Summit ambitions “The UK government has today set out its ambitions for the AI Safety Summit which will take place on the 1st and 2nd November at Bletchley Park.”
AI Startup Buzz Is Facing a Reality Check “Founders and venture capitalists who flocked to artificial-intelligence startups are learning that turning the chatbot buzz into successful businesses is harder than it seems.”
Even AI Hasn’t Helped Microsoft’s Bing Chip Away at Google’s Search Dominance “When Microsoft unveiled an AI-powered version of Bing in February, the company said it could add $2 billion of revenue if the revamped search engine could pry away even a single point of market share from Google.”
Baidu CEO says more than 70 large AI language models released in China “More than 70 large artificial intelligence language models with over 1 billion parameters have been released in China, Baidu Inc CEO Robin Li told an industry event in Beijing on Tuesday.”
Inside Elon Musk's Struggle for the Future of AI “At a conference in 2012, Elon Musk met Demis Hassabis, the video-game designer and artificial--intelligence researcher who had co-founded a company named DeepMind that sought to design computers that could learn how to think like humans.”
Pentagon plans vast AI fleet to counter China, Wall Street Journal reports “The Pentagon is considering the development of a vast network of Artificial Intelligence-powered technology, drones and autonomous systems within the next two years to counter threats from China, the Wall Street Journal reported on Wednesday.”
OpenAI will host its first developer conference on November 6 “OpenAI will host a developer conference — its first ever — on November 6, the company announced today.”
Newsom signs executive order to study uses, risks of generative AI in California “California Gov. Gavin Newsom (D) signed an executive order Wednesday directing the state to study the potential uses and risks of generative artificial intelligence (AI) — a subset of AI, like ChatGPT — that generates novel text, images and other content.”
Slack AI' will summarize your work chat starting this winter “After introducing the generative AI capabilities it was developing for Slack at World Tour NYC earlier this year, Salesforce has revealed as part of its Dreamforce announcements that it's now gearing up to pilot the new features this winter.”
Chinese AI chatbots want to be your emotional support “Baidu became the first Chinese tech company to roll out its large language model—called Ernie Bot—to the general public, following a regulatory approval from the Chinese government. Previously, access required an application or was limited to corporate clients.”
Nasdaq gets SEC nod for first exchange AI-driven order type “Nasdaq Inc. on Friday said it won approval from the U.S. Securities and Exchange Commission to launch the first exchange artificial intelligence-driven order type, a move that, if successful, could further increase the efficiency of an already fast-paced stock market.”
Congress to hold new AI hearings as it works to craft safeguards “Congress next week will hold three hearings on artificial intelligence, including one with Microsoft President Brad Smith and Nvidia chief scientist William Daly as Congress works on legislation to mitigate the dangers of the emerging technology.”
Roblox’s new AI chatbot will help you build virtual worlds “Roblox announced a new conversational AI assistant at its 2023 Roblox Developers Conference (RDC) that can help creators more easily make experiences for the popular social app.”
TSMC warns AI chip crunch will last another 18 months “Bad news for anyone looking to get their hands on Nvidia's top specced GPUs, such as the A100 or H100: it's not going to get any easier to source the parts until at least the end of 2024, TSMC has warned.”
Papers
Daniel: A few papers caught my eye recently! First off, this paper establishes a formal equivalence between the optimization geometry of self-attention and a hard-margin SVM problem that separates optimal input tokens from non-optimal tokens using linear constraints on the outer products of token pairs. I’m not sure there’s an immediate practical takeaway on this one, but the interpretation of transformers as SVMs is pretty neat. In the opposite direction, this paper shows that modern RNNs, equipped with linear recurrent layers interconnected by feedforward paths with multiplicative gating can exactly implement (linear) self-attention. These findings highlight the importance of multiplicative interactions in neural networks, and it’s notable that certain RNNs might actually be implementing attention. A final paper I’ll call out explores the role of the feedforward network (FFN) in Transformers and finds that the FFN is “highly redundant.” Traditional Transformers allocate one FFN to each layer of the encoder and decoder. The authors remove the decoder layers’ FFNs, and modify the encoder by sharing a single FFN across layers; they scale the architecture back to its original size by increasing the shared FFN’s hidden dimension and claim substantial performance gains in accuracy and latency compared to the original Transformer Big.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!
Amazing sets of news articles at the bottom. Delight to read through them. Thank you!