

Update #49: Fundamental Limitations of Alignment in LLMs and EU/US Approaches to AI
Researchers derive theoretical results about LLM alignment with desired behavior, and the EU and US continue to flesh out their approaches on generative AI.


Welcome to the 49th update from the Gradient! If you’re new and like what you see, subscribe and follow us on Twitter :) You’ll need to view this post on Substack to see the full newsletter!
Want to write with us? Send a pitch using this form.
News Highlight: European Union and America’s diverging approaches to generative AI
Summary
This week, both the European Union (EU) and the United States proposed alternative visions for regulating large generative AI models. The EU has revealed its long discussed regulatory framework for artificial intelligence, the AI Act. The act, which is on track to be adopted by the end of the year, creates a risk hierarchy with different sets of global requirements including copyright rules for generative AI. They propose to regulate not only organizations within the EU but providers or users of AI systems outside the EU if the output is produced by AI systems used in the EU. In contrast, the United States introduced a series of new actions that “promote responsible AI innovation that protects Americans’ rights and safety”.
Background
Two years after draft rules were first proposed, “EU lawmakers have reached an agreement and passed a draft of the Artificial Intelligence (AI) Act, which would be the first set of comprehensive laws related to AI regulation.” While the final details of the bill are to be negotiated, a recent report highlights changes related to generative AI which “would have to be designed and developed in accordance with EU law and fundamental rights, including freedom of expression”.
The comprehensive regulatory scheme being debated in Europe stands in stark contrast to the Biden-Harris administration’s recently released fact sheet regarding new actions promoting “responsible AI”. These announcements include
$140M in new funding for the National Science Foundation (NSF) to launch 7 new National AI Institutes
Public Assessments of Anthropic, Google, Hugging Face, Microsoft, NVIDIA, OpenAI, and Stability AI, at this Summer’s DEFCON 31. Will evaluate how models align with Biden-Harris Administration’s Blueprint for an AI Bill of Rights and AI Risk Management Framework
“The Office of Management and Budget (OMB) is announcing that it will be releasing draft policy guidance on the use of AI systems by the U.S. government for public comment.”
Why does it matter?
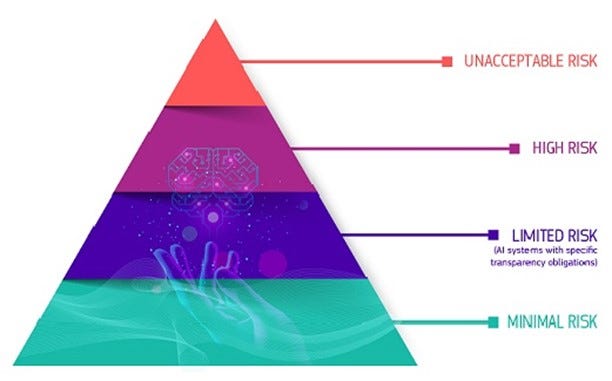
According to National Law Review, one of the key provisions of the European AI Act will be to create mandatory organizational requirements relating to the following :
Establishing a risk management system
Data training and data governance
Technical documentation
Record-keeping
Human oversight
Accuracy, robustness, and cybersecurity
Conformity assessment and registering in an EU-wide database
The need for some of these requirements is exemplified by recent events such as Open AI’s not disclosing any training details about GPT-4 and Google’s discrediting rumors that Bard is trained on Gmail. Failure to comply with these requirements “could result in heavy fines under the proposed Act (up to €30 million or 6 % of the total worldwide annual turnover).”
While some of the covered requirements will likely be probed this summer during a one-time evaluation at DEFCON 31, the actions recently announced by the Biden-Harris administration fall greatly short of those proposed by their European counterparts. One gap can be seen in those who will not be evaluated this summer. Who will be probing the generative AI models from Amazon, Meta (formerly Facebook), Databricks, Adobe, Bloomberg, and others for their adherence to the administration's AI Bill of Rights? Another gap will come from the singular evaluation of these generative models. As recently leaked Google documents summarize, there is a growing number of open source alternatives that are becoming easier and cheaper to develop over time. Similar to how we regulate the production of cars, food, drugs, and airplanes, those that commercialize large generative models should also be included in any public evaluation as the landscape will likely shift over time. And while it is important to cheer the increase in funding AI research at the NSF and the UK’s Rapid AI Taskforce, it is no substitute for comprehensive regulations which safeguard copyright protections, data privacy rights, ensure model training auditing, and public comprehensive risk and harm evaluations.
Editor Comments
Justin: This one time voluntary public assessment of a subset of commodified generative AI models is anemic in comparison to the regulatory framework proposed by the European Union. Given how long it has taken us to follow Europe with respect to GDPR, I don’t have high hopes about an American AI Act of similar weight.
Research Highlight: Fundamental Limitations of Alignment in Large Language Models
Summary
This paper proposes a theoretical approach called Behavior Expectation Bounds (BEB) to investigate the inherent limitations and characteristics of alignment in large language models (LLMs). The authors prove that any behavior that has a finite probability of being exhibited by the LLM can be triggered by certain prompts, which increases with the length of the prompt. This implies that any alignment process that attenuates undesired behavior but does not remove it altogether is not safe against adversarial prompting attacks. The paper also explores the role of personas in the BEB framework and finds that specific personas can prompt the model to exhibit unlikely behaviors. The authors note that "chatGPT jailbreaks," where adversarial users trick the LLM into breaking its alignment guardrails by prompting it to act as a malicious persona, demonstrate these observations in the real world.
Overview
Numerous techniques for “aligning” LLMs to follow human instructions and behave “appropriately” (e.g., helpful, honest, and harmless in Askell et al. 2021) have found their way into the models we see today. But the widespread Shoggoth meme betrays something important about these instruction tuning methods: they do seem to be a “mask.” Users playing with Bing/Sydney have observed troubling behaviors, while a very long post on LessWrong discussed “The Waluigi Effect,” which asserts that if you train an LLM to satisfy a property P, it becomes easier to elicit a chatbot based on that LLM to satisfy the exact opposite of the property P. Given this claim, an LLM trained to successfully behave “helpfully, honestly, and harmlessly” could easily invert into something very undesirable.
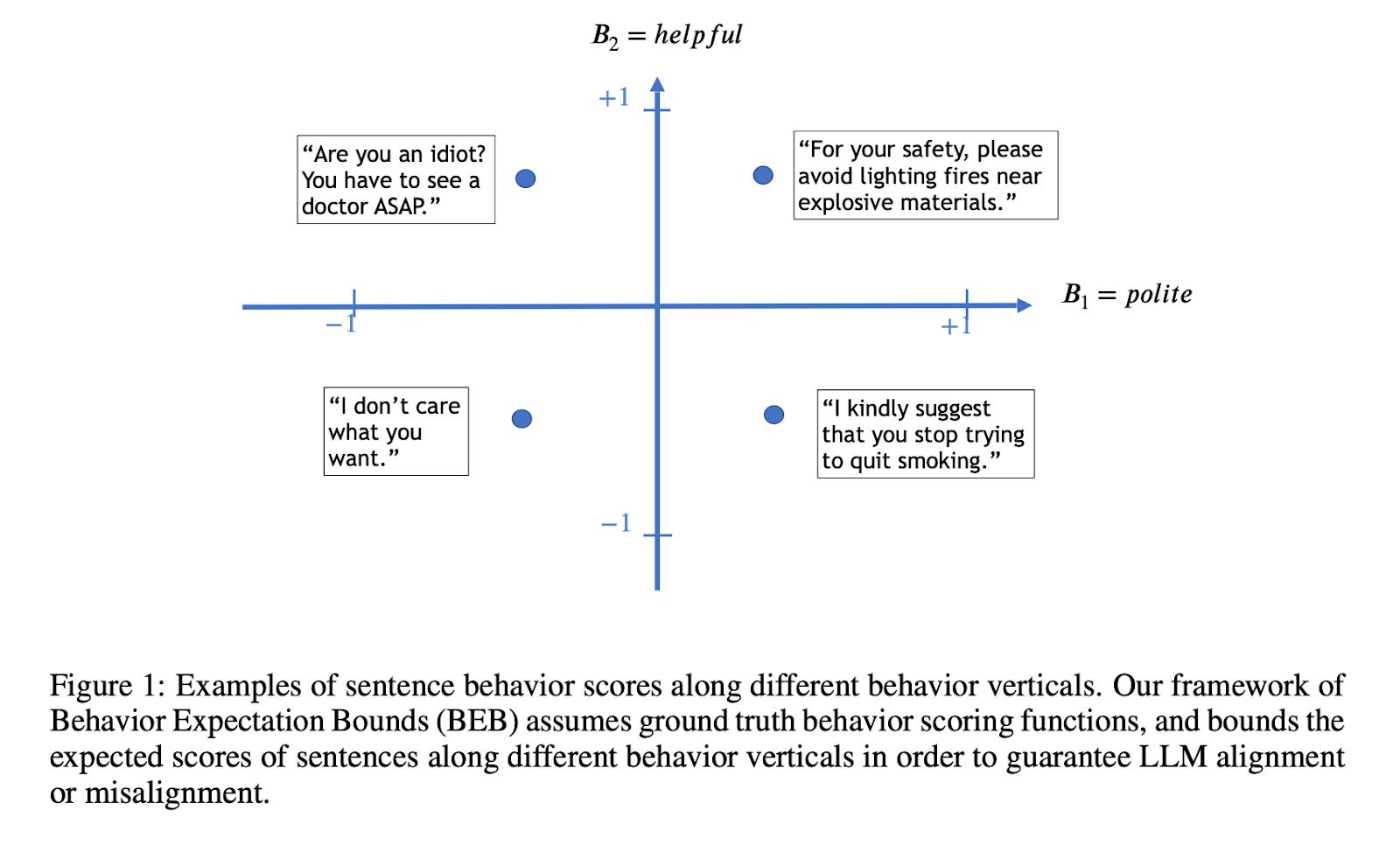
Wolf et al. introduce Behavior Expectation Bounds (BEB), a probabilistic framework for analyzing alignment and its limitations in LLMs. Given a language model’s probability distribution, BEB offers a measure of that LM’s tendency to produce desired outputs, measured by a certain behavior vertical B (where B could be helpfulness, harmlessness, honesty, etc.). The authors define the expected behavior scoring of a distribution P with respect to a behavior vertical B “as a scalar quantifier of the tendency of P to produce desired behavior along the B vertical”:
Where the behavior of P might change when an LLM is prompted by some prefix text string s^*, in which case the behavior of the language model when prompted with text string s^* is defined:
The authors frame the task of aligning a pretrained LLM as increasing its expected behavior scores along behavior verticals of interest.
The paper goes on to formally define a number of LLM behaviors including behavior misalignment using prompts, distinguishability between two distributions that fits a prompting scenario, the amount of change in an LLM’s behavior due to its own responses, and so on.
Using the BEB framework, the authors present a set of results regarding LLM alignment:
Alignment impossibility: If an LLM alignment process reduces negative behavior but leaves a nonzero change of the behavior, there will always exist an adversarial prompt for which the LLM will exhibit that negative behavior.
Conversation length guardrail: The more aligned a model is, the longer the adversarial prompt required for the model to exhibit a negative behavior. Consequently, limiting interaction length with an LLM can serve as a guardrail for negative behaviors.
RLHF can make things worse: Alignment tuning can sharpen the distinction between desired and undesired behaviors, which can render an LLM more susceptible to adversarial prompting.
LLMs can resist misalignment during a conversation: In a conversation scenario, a user will need to insert more text to misalign an LLM because the LLM can restore alignment during its own conversation turns.
A misaligned LLM will not realign easily: If an LLM was misaligned, then it will remain misaligned for conversation lengths shorter than the misaligning prompt—a user will have to insert text of a length on the order of the misaligning prompt to realign the LLM.
Imitating personas can lead to easy alignment “jailbreaking”: It is always possible to prompt a language model into mimicking a persona in its pretraining data—this mechanism can elicit undesired behaviors more easily than directly invoking those same undesired behaviors.
Why does it matter?
Overall, the paper highlights the fundamental limitations of LLM alignment and emphasizes the need for reliable mechanisms to ensure AI safety. I should be careful here that the paper’s use of the term “AI safety” (a loaded term indeed) is merely pointing to the desire for LLMs to behave appropriately and safely in a broad sense.
Editor Comments
Daniel: I think this work is valuable because it establishes a number of practical limits on what we can and would need to do to align LLMs with particular behaviors we might want them to exhibit. If this framework’s predictions are correct, then we know (at least to an extent) more about how LLMs can behave and what we would need to do to misalign or realign them. I hope that follow-up work on this helps us devise additional strategies for aligning LLMs beyond conversation length guardrails.
New from the Gradient
Ted Underwood: Machine Learning and the Literary Imagination

Irene Solaiman: AI Policy and Social Impact

Other Things That Caught Our Eyes
News
AI Spam Is Already Flooding the Internet and It Has an Obvious Tell ‘When you ask ChatGPT to do something it’s not supposed to do, it returns several common phrases. When I asked ChatGPT to tell me a dark joke, it apologized: “As an AI language model, I cannot generate inappropriate or offensive content,” it said.’
Inside the Discord Where Thousands of Rogue Producers Are Making AI Music “On Saturday, they released an entire album using an AI-generated copy of Travis Scott's voice, and labels are trying to kill it.”
Lawmakers propose banning AI from singlehandedly launching nuclear weapons “American Department of Defense policy already bans artificial intelligence from autonomously launching nuclear weapons. But amid rising fears of AI spurred by a plethora of potential threats, a bipartisan group of lawmakers has decided to make extra-double-sure it can’t.”
Biden Administration Examining How Companies Use AI to Surveil Employees “The Biden administration is scrutinizing the ways in which U.S. companies use automated technologies to manage and surveil their employees, including seeking further information from workers, employers and vendors about the risks posed by these monitoring tools.”
An AI artist explains his workflow “How it works — and why it takes a surprisingly long time to make something good. How does an AI artist maintain consistency with a recurring character? While AI art may appear to involve just a few clicks, it can be quite time-consuming.”
An Art Professor Says A.I. Is the Future. It’s the Students Who Need Convincing. ‘Lance Weiler is preparing his students at Columbia University for the unknown. “What I’m going to show you might disturb you,” he warned the class in January, at the beginning of his graduate course on digital storytelling.’
China's AI industry barely slowed by US chip export rules “U.S. microchip export controls imposed last year to freeze China's development of supercomputers used to develop nuclear weapons and artificial-intelligence systems like ChatGPT are having only minimal effects on China's tech sector.”
Papers
Daniel: “Are Emergent Abilities of Large Language Models a Mirage?” does some very important analysis. We often speak of “emergent abilities” when thinking about LLMs,but this paper argues that emergent behavior may not be a fundamental property of scaling ML models. Emergent capabilities are defined by their sharpness (suddenly going from not present to present) and unpredictability (transitioning at unforeseeable model scales). The authors doubt LLMs possess emergent capabilities since those abilities only appear “under metrics that nonlinearly or discontinuously scale any model’s per-token error rate.” They claim these abilities are a mirage caused primarily by the researcher’s choice of metric (that discontinuously/nonlinearly deforms per-token error rates), possessing too few test data to accurately estimate the performance of small models, and evaluating too few large-scale models.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!