

Update #42: AI + News Editors Make Mistakes and New Masked Image Self-Supervised Methods
CNET finds that AI-assisted writing isn't as easy as it bargained, and masking-based self-supervised learning makes strides (+ Author Q&A)



Welcome to the 42nd update from the Gradient! If you were referred by a friend, subscribe and follow us on Twitter :) You’ll need to view this post on Substack to see the full newsletter!
Want to write with us? Send a pitch using this form.
News Highlight: CNET Finds Errors in More Than Half of Its AI-Written Stories

Summary
Popular tech news website CNET recently began using an AI bot (not ChatGPT) to write short articles and found errors in 41 of the 77 stories the bot wrote. CNET’s Editor-in-chief, Connie Guglielmo, shared the details in a note that defended the use of the technology and listed some changes the organization is making to better address these issues. While CNET has paused the use of its AI bot for the time being, Guglielmo asserted her vision of integrating AI tools into the stack of the modern journalist and mentioned CNET’s plan to resume the use of such technologies at a better time in the future.
Background
Language models have made their mark in recent years with models like GPT-3 and ChatGPT being used by individuals in every industry for their own use cases. A straightforward yet tricky application of generative language models is their ability to write articles or blogs when fed a prompt. While LLMs can often generate coherent content, that content is not guaranteed to be reliable. This effect is heavily documented with the use of ChatGPT, which has been shown to produce factually incorrect answers to a variety of prompts.
Considering this, it is not surprising to learn that when CNET deployed an in-house model to write short blogs on personal finance, the model often generated incorrect or plagiarized content without proper citations. A CNET editor fed the bot an article outline then reviewed and edited the draft. Despite this process, CNET found errors in more than half of the articles published by the editor-bot teams. Issues ranged from minor mistakes such as jumbled or reversed numbers and incorrect company names to issues that required “substantial correction” (CNET did not elaborate on what this specifically entailed). It is also unclear why these issues, big and small, were not caught by the human editors before publishing.
Why does it matter?
This case speaks to a general trend of overconfidence in the capabilities of novel language models, especially when deployed in production. It is perhaps more concerning that human reviewers who should have been aware of the potential pitfalls of the algorithm did not correct these mistakes before publishing. While AI will indubitably be a part of the writer’s stack in the future, the appropriate level of oversight needed for AI systems remains uncertain. This incident also reflects the immense pressure on journalists to churn out articles – perhaps even after using an AI system to write articles, these journalists could not find time to comprehensively review the generated drafts. The issue of plagiarism from language models is also interesting – models trained on vast amounts of text data from the internet will inevitably use language borrowed in some way from different sources and writing styles. The questions then are, how can we discern specific cases of plagiarism that cross a threshold, where do we draw this line between inspiration and duplication, and what might that look quantitatively?
Editor Comments
Daniel: Wow, would you look at that. When you get LLMs and people together in a room to write articles, numerous mistakes are made. It’s pretty clear that integrating generative technologies into journalism isn’t going to stop–see CNET’s own comments above and BuzzFeed’s recent announcement, for instance. The question we have to consider now is how to deploy these models and integrate them into human work in such a way that mistakes like these (or worse) can be avoided. I’m glad CNET jumped in with this and made mistakes, because now we can look at what went wrong and alleviate the causes of their issues. If journalists are being pushed at such a rate that they can’t effectively fact-check articles they co-write with LLMs, there’s a clear problem with multiple possible solutions: giving journalists more time (gasp), involving additional staff / fact-checkers in the process.
Research Highlight: New Masked Image Self-Supervised Methods
Sources:
[1] Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
[2] Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture

Source: [2]
Summary
Recently, new methods for masking-based self-supervised learning from images have been developed. SparK [1] uses sparse convolutions and hierarchical decoding to develop a BERT-style masked pretraining objective that works well with convolutional networks. I-JEPA [2] is a scalable masked image modelling framework that predicts representations of masked blocks, as opposed to predicting in pixel space.
Overview
Masking-based self-supervised representation learning has found tremendous success in natural language processing (NLP), especially through BERT and its descendants. For several reasons, effective masking objectives took longer to develop for image representation learning; for example, pixels / patches in images are continuous valued while tokens in natural language are discrete, and good Transformers for Vision were developed a few years after the original Transformers (and popular masking based methods like BERT relied on Transformers). Nonetheless, masked image models like BEiT and MAE have now achieved success in self-supervised learning of useful representations. This week, we cover two new masking-based methods for self-supervised learning on images.
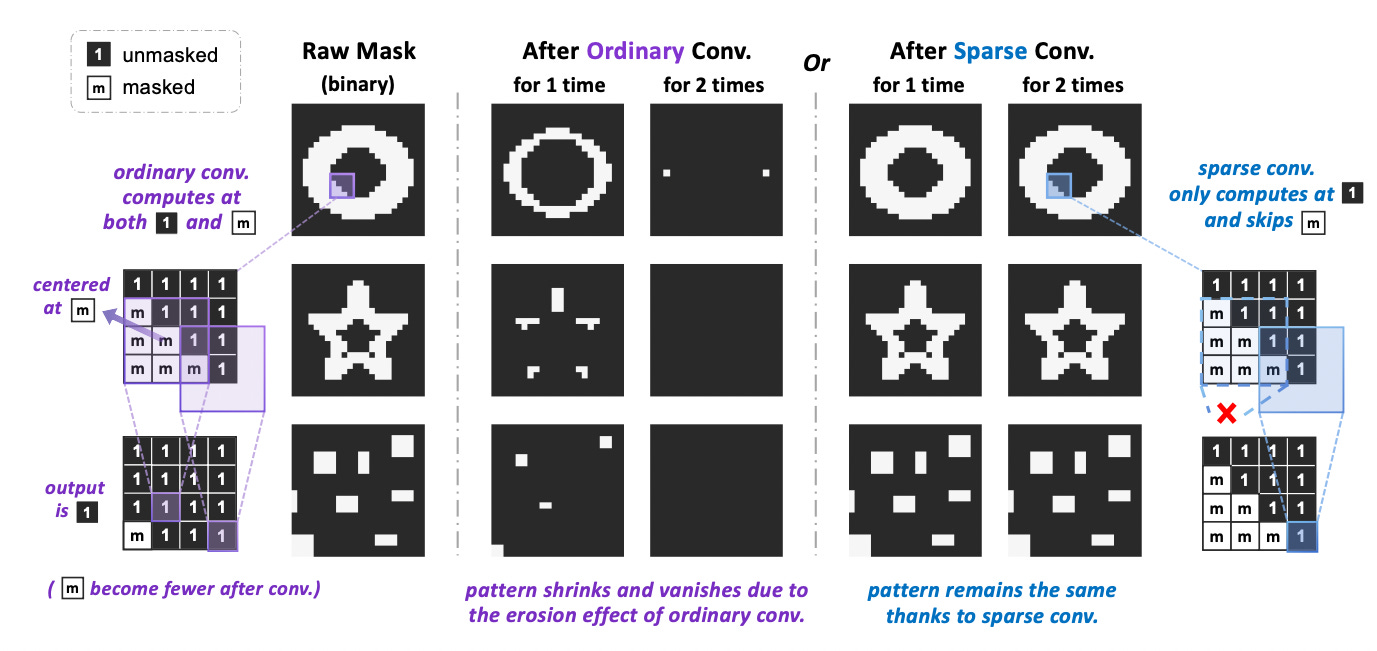
Artifacts of ordinary convolution (middle column) on masked input. Sparse convolution (right column) is fine. Image from [1]
Sparse masked modeling (SparK) is a newly proposed method to use masking based methods for convolutional networks (convnets). There are a few difficulties when training with masking for convnets as opposed to Transformers. In the above Figure, we see that ordinary convolutions cause harmful artifacts when applied to masked data that can make learning useful representations difficult. This is in part because convolutions are ordinarily defined on regular grids of input, and typically process overlapping patches. Changing to a sparse convolution, in which the convolution is only applied when the kernel is centered at non-masked pixels, alleviates these issues. The other important design decision in SparK is to use hierarchical encoding and decoding: the encoder will generate feature maps at different resolutions, and then decode to reconstruct the masked patches using all of these feature maps.

A Meta AI (FAIR) team recently developed an Image based Joint-Embedding Predictive Architecture (I-JEPA). This is another self-supervised method based on masking, that predicts in representation space as opposed to pixel space. The authors hypothesize that predicting in representation space can encourage the model to learn semantic features. I-JEPA consists of two encoders: a context encoder and a target encoder. A context block (unmasked patches) is sampled, and several target blocks (that are masked in the context block) are sampled. The target encoder takes in the whole image, and then the target representations corresponding to certain context blocks are taken from the outputs of this target encoder. The context encoding is generated by the context encoder, and passed to a decoder to predict the target representations.
Why does it matter?
Both methods achieve impressive empirical results. The sparse convolutions in SparK increase efficiency, as only the 40% unmasked patches of each image need to be processed. I-JEPA is slower than MAE per iteration (as the target encoder has to take in a whole image as opposed to just unmasked patches), but converges in many fewer iterations, thus achieving strong performance much quicker than MAE. SparK outperforms a variety of self-supervised methods when fine-tuning the entire pretrained model; I-JEPA does very well on linear evaluation (when the pretrained model weights are frozen and only an additional linear layer is trained), while using much less compute than previous methods.
Masked image modelling has several advantages over other types of self-supervised learning. For instance, there is no need for hand-picked data augmentations, as are needed for contrastive learning. Also, masked based pretraining is more similar to types of pretraining done in other modalities, so research advances may be able to be more easily transferred to the image domain through image masking frameworks.
To find out more, we spoke to Keyu Tian — the lead author of SparK from Peking University.
Author Q&A
Q: What are the benefits of developing self-supervised methods for convnets, as opposed to just Transformers?
A: First of all, I would say convnets are still a great choice in practical for visual tasks. Convolution was once dominant in the field of computer vision, with properties such as translational equivariance and scale hierarchy that have long been considered the gold standard. In addition, these operations are deeply optimised on various hardware, whereas self-attention is not. Hence convnets are used by default in many engineering scenarios, especially real-time ones, due to their excellent efficiency and ease of deployment. A direct benefit of this work is a powerful self-supervised method for convnets, which may hopefully bringing improvement to these budget constrained scenarios.
On the other hand, in a broader scope, we need more evidence to fully understand why transformers seems to outperform convnets on a wide range of vision tasks. There are a lot of differences between these two models. One of which, particularly interest us, is the different paradigm for self-supervised learning. Our paper inspect the convnets and in a unique point of view: by mitigating the seemingly transformer exclusive pretraining paradigm to convnets, we show that, at least part of the “superiority” of transformers may be attribute to learning criteria. We would like to see more interesting research on adapting convention from Transformers to convnets or vice versa to unveil the fundamental property of the models.
Q: How about the benefits of developing self-supervised methods for Transformers instead?
A: I feel Transformers become more promising when doing vision-language pretraining. The Transformer is currently a good choice for dealing with cross-modal data (vision and language) — It is born to process token sequences, either from text or from images. So developing some general self-supervised learning (e.g., masked autoencoding on both text and image tokens) can be pretty useful for tasks like visual question answering, image captioning and image-sentence retrieval.
Q: What do your results imply for the future of self-supervised image representation learning?
A: BERT-style masked autoencoding is a broad family of methods. Our work is one of the early attempts for BERT-style pretraining to work for convnets. We expect to see more papers working on generative representation learning for convnets this year. We will not be supervised if pure generative representation learning taking over the leading position of contrastive learning and became the first choice among self-supervision for computer vision researchers and engineers.
New from the Gradient
Blair Attard-Frost: Canada’s AI strategy and the ethics of AI business practices

Linus Lee: At the Boundary of Machine and Mind

Do Large Language Models learn world models or just surface statistics?

Reasons to Punish Autonomous Robots

Other Things That Caught Our Eyes
News
Scores of Stanford students used ChatGPT on final exams, survey suggests “Stanford students and professors alike are grappling with the rise of ChatGPT, a chatbot powered by artificial intelligence, and the technology’s implications for education.”
How to Spot AI-Generated Art, According to Artists “How long will the naked eye be able to spot the difference between images made by generative artificial intelligence and art created by humans?”
I’m a Congressman Who Codes. A.I. Freaks Me Out. “Imagine a world where autonomous weapons roam the streets, decisions about your life are made by AI systems that perpetuate societal biases and hackers use AI to launch devastating cyberattacks.”
Alphabet-owned AI firm DeepMind shutters office in Canada's Edmonton “DeepMind Technologies, owned by Alphabet Inc (GOOGL.O), is closing its office in the Canadian city of Edmonton, a spokesperson for the AI firm said, just days after Google's parent announced it would lay off 12,000 employees.”
Papers
Daniel: First a shoutout for the researchers who finally went and named a model ClimaX. I’m looking out for work applying generative models to biology / life sciences these days, and in that domain I was happy to see two works: “Large language models generate functional protein sequences across diverse families” and “On the Expressive Power of Geometric Graph Neural Networks.” The first paper introduces ProGen, a language model that can generate protein sequences with a predictable function across large protein families. Again, I’m excited about models like ProGen that can expand the space of protein sequences we can study beyond those naturally arising from evolution. The second paper proposes a geometric version of the Weisfeiler-Leman (WL) graph isomorphism test, which unpacks how design choices influence GNN expressivity. These networks have applications in biology and materials because biomolecules, materials, and other physical systems can be represented as graphs in Euclidean space. This area is going to be exciting in the coming years.
Derek: Though I don’t know much about these areas, I like the newly published “A Watermark for Large Language Models”. Methods similar to those presented in the paper could be useful for LLM services (e.g. the OpenAI API) to determine whether a given segment of text (e.g. a high school student’s essay) is generated using an LLM from that service. This could help with reducing misuse, though in a future in which more and more parties have strong LLMs, such methods may not be enough to detect whether any given piece of text is generated from one of the many available LLMs.
Tanmay: I came across the paper, Dissociating Language And Thought In Large Language Models: A Cognitive Perspective that verbalizes an issue we have all perhaps felt while using LLM’s. The paper suggests that linguistic abilities can be divided into two buckets: Formal Linguistic Competence and Functional Linguistic Competence. Formal linguistic skills require understanding the rules and patterns of language itself, such as grammar and syntax, while functional linguistic skills require the agent to reason, understand logic, social norms, etc while responding to a prompt. The authors argue that while LLM’s can be thought of agents with excellent formal linguistic competence, we are still a bit away from developing functional skills. An example used in the (very thorough) paper is how GPT-3’s response to “Get your sofa onto the roof of your house” is “I would start by getting a very strong ladder and a very strong friend…”. While the structure of the sentence is grammatically correct, the logic and reasoning behind it has considerable pitfalls.
Tweets
Prof Lipton being a savage 👀



Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this newsletter, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!