

Update #35: AI Bill of Rights and Unifying Language Learning Paradigms
In which we look at the White House's Blueprint for an AI Bill of Rights and Google's new method for training LMs with a mixture of objectives.



Welcome to the 35th update from the Gradient! If you were referred by a friend, subscribe and follow us on Twitter!
Want to write with us? Send a pitch using this form :)
News Highlight: Blueprint for an AI Bill of Rights

[1] White House: Blueprint for an AI Bill of Rights
[2] IEEE: 6 reactions to the White House’s AI Bill of Rights
Summary
In the United States, the White House Office of Science and Technology Policy (OSTP) has released a blueprint consisting of five principles meant to protect the American people’s civil rights from infringement by artificial intelligence systems. The full document includes examples to help identify issues with automated systems and guidelines to aid in preserving the rights outlined in the five principles. Nonetheless, the document notes that this blueprint is “non-binding and does not constitute U.S. government policy”, so specific enforcement of the principles is not guaranteed in any sense.
Background
AI use is becoming more pervasive in all facets of life, and further development will likely lead to automated AI systems in even more areas. However, proper implementation of AI and associated data collection processes is needed to ensure that such systems do not negatively impact people. In the European Union, the AI Act is a proposed law that seeks to regulate AI in order to minimize negative impacts upon society. China has also recently developed initiatives related to AI governance.
Recently, the United States’ White House OSTP released a so-called “Blueprint for an AI Bill of Rights”, which outlines five principles for responsibly building AI in a way that does not infringe upon civil rights and freedoms. The principles are as follows:
Safe and Effective Systems: AI systems should be designed and deployed in a manner that minimizes harm. This can include testing before deployment and evaluation during deployment.
Algorithmic Discrimination Protections: Automated systems should not discriminate based on race, gender, religion, or other protected characteristics.
Data Privacy: Your data should be collected responsibly, and you should be able to make informed choices regarding your data.
Notice and Explanation: People should know when automated systems are being used, and information about the automated system should be accessible.
Human Alternatives, Consideration, and Fallback: When possible, there should be a choice to opt out of using an automated system, and instead have a human alternative. If an automated system works incorrectly, then there should be some sort of human consideration or fallback.
Why does it matter?
IEEE Spectrum collected reactions of 6 experts on AI policy towards the AI Bill of Rights blueprint [2]. Opinions were varied. Daniel Castro of the Center for Data Innovation argues that there should not be separate regulations for AI systems, and instead existing laws that protect civil rights should be applied to automated systems just as they are for non-digital issues. The Surveillance Technology Oversight Project criticizes the lack of enforcement options for this blueprint, and argues that enforceable regulations are needed. On the other hand, the Algorithmic Justice League applauded the blueprint as “an encouraging step in the right direction in the fight toward algorithmic justice”. Either way, we may expect more AI-related rights regulations and legislation in the future, both in the US and other countries worldwide.
Editor Comments
Daniel: I’m curious how this bill of rights is going to pan out, especially as we are seeing more forward measures coming from other parts of the world–Europe and China are important examples. The question, as it often seems with bills like these, is “where’s the bite?” I think there are important ideas and considerations in this document, but enforcement and detection of violations is always a tricky issue. I think that globally, we’re getting closer to seeing these types of legislation play out in a meaningful way: we’ve seen examples of enforcement in Europe and analysts like Matt Sheehan have commented that China “will be running some of the world’s largest regulatory experiments on topics that European regulators have long debated.” Perhaps we’ll see the regulation flywheel begin to spin soon.
Research Highlight: A Unified Language Learner from Google
Summary
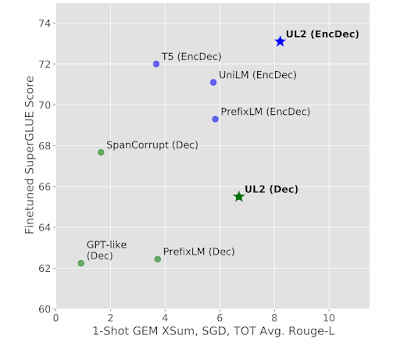
Language models are typically trained using one of a handful of objective functions, such as masking, prompting, etc (elaborated on later). Each of these objectives brings its own pros and cons, resulting in a set of trained models that often have complementary strengths. Google’s new framework named Unified Language Learning Paradigm (or UL2), is a multi-task training methodology that allows a language model to be trained using multiple objective functions. The authors show that the resulting model trained on a mixture of objectives outperforms models trained on a single objective, thereby demonstrating a novel application of multi-task learning to the domain of Natural Language Processing (NLP).
Overview
Current methods in NLP use a variety of techniques to train language models that essentially map a sequence of input tokens to the output tokens. Models such as PaLM or GPT-3 utilize autoregressive decoder-only architectures in which they are trained to predict the next sequence of tokens given the input sequence. Other models such as T5 utilize encoder-decoder based architectures in which a portion of the input sequence is masked and the model is tasked to predict the masked sequence. Both techniques bring their own advantages and disadvantages – autoregressive models tend to show better performance in prompt-based generation (which has gained popularity in recent times) but not as well on fine-tuning tasks, while models trained with masked inputs (also called corruption-based methods) perform well on supervised fine-tuning tasks but not on open-ended generation. Hence, the pros and cons of these models are complimentary, leaving the current state of NLP models to have obvious pitfalls based on the objective they were trained on.
Google’s new method–UL2–aims to bridge this gap by developing a training methodology that utilizes both corruption and sequence generation techniques. UL2 essentially trains a language model to learn the transformation between a sequence of “noisy” input tokens and the “de-noised” output tokens. UL2 utilizes variations of two objectives in its implementation: span corruption, where a number of contiguous spans are masked out from the input, and PrefixLM, in which the first k tokens are input to the model, and the rest are masked out (where k is randomly sampled). Specifically, it trains language models on a mixture of three de-noising objectives:
R-denoising: Regular span corruption, where a sequence of tokens is masked in the input
X-denoising: Extreme span corruption, similar as masking, but more heavily masked than R-denoising
S-denoising: same as the PrefixLM objective
During pre-training, once an input sequence is obtained from the dataset, one of three [R], [X], or [S] tasks is chosen by randomly sampling based on pre-specified weights. This task type – [R/X/S] is then appended to the input sequence to communicate the chosen task.
The authors evaluate their model on both fine-tuning and in-context learning tasks and show that models trained with their methodology outperform other models in joint-performance across both of these tasks. While the encoder-decoder based model achieves a higher score in both tasks, the decoder only model trained with UL2 achieved a higher score on the 1-shot in-context learning task than other models, but had the second highest score on fine tuning. The highest score was achieved by SpanCorrupt, but since its score on the in-context learning task was a third of the score of the UL2 model, we can conclude that the UL2 model shows the best joint performance on the two tasks.
Why does it matter?
The work is a great example of multi-task learning that can be leveraged in training language models with fewer pitfalls than previous methods. The checkpoints of the trained model are also open source, and ofcourse, there is a HuggingFace API.
New from the Gradient
Zachary Lipton: Where Machine Learning Falls Short

Stuart Russell: The Foundations of Artificial Intelligence

Other Things That Caught Our Eyes
News
GitHub Users Want to Sue Microsoft for Training an AI Tool With Their Code “‘Copilot’ was trained using billions of lines of open-source code hosted on sites like GitHub. The people who wrote the code are not happy.”
FDA clears noninvasive AI-powered coronary anatomy, plaque analyses “HeartFlow announced it has received FDA 510(k) clearance on two new noninvasive artificial intelligence-powered coronary artery anatomy and plaque analyses based on coronary CT angiography.”
Weird robot breaks down in middle of House of Lords hearing on AI art “A freaky-looking humanoid robot wearing dungarees and named Ai-Da became the first machine to speak at a House of Lords committee hearing on AI art this week.”
Meta’s AI translator can interpret unwritten languages “[U]nwritten languages pose a unique problem for modern machine learning translation systems, as they typically need to convert verbal speech to written words before translating to the new language and reverting the text back to speech, but Meta has reportedly addressed [this issue] with its latest open-source language AI advancement.”
Generally Intelligent secures cash from OpenAI vets to build capable AI systems “A new AI research company is launching out of stealth today with an ambitious goal: to research the fundamentals of human intelligence that machines currently lack.”
Papers
On Feature Learning in the Presence of Spurious Correlations Following recent work on Deep Feature Reweighting (DFR), we evaluate [a deep classifier’s] feature representations by re-training the last layer of the model on a held-out set where the spurious correlation is broken. On multiple vision and NLP problems, we show that the features learned by simple ERM are highly competitive with the features learned by specialized group robustness methods targeted at reducing the effect of spurious correlations. Moreover, we show that the quality of learned feature representations is greatly affected by the design decisions beyond the training method, such as the model architecture and pre-training strategy. On the other hand, we find that strong regularization is not necessary for learning high quality feature representations.
Diffusers: Efficient Transformers with Multi-Hop Attention Diffusion for Long Sequences [L]everaging sparsity [in Transformers] may sacrifice expressiveness compared to full-attention, when important token correlations are multiple hops away. To combine advantages of both the efficiency of sparse transformer and the expressiveness of full-attention Transformer, we propose Diffuser, a new state-of-the-art efficient Transformer. Diffuser incorporates all token interactions within one attention layer while maintaining low computation and memory costs. The key idea is to expand the receptive field of sparse attention using Attention Diffusion, which computes multi-hop token correlations based on all paths between corresponding disconnected tokens, besides attention among neighboring tokens. Theoretically, we show the expressiveness of Diffuser as a universal sequence approximator for sequence-to-sequence modeling, and investigate its ability to approximate full-attention by analyzing the graph expander property from the spectral perspective. Experimentally, we investigate the effectiveness of Diffuser with extensive evaluations, including language modeling, image modeling, and Long Range Arena (LRA).
Meta Learning Backpropagation And Improving It Many concepts have been proposed for meta learning with neural networks (NNs), e.g., NNs that learn to reprogram fast weights, Hebbian plasticity, learned learning rules, and meta recurrent NNs. Our Variable Shared Meta Learning (VSML) unifies the above and demonstrates that simple weight-sharing and sparsity in an NN is sufficient to express powerful learning algorithms (LAs) in a reusable fashion. A simple implementation of VSML where the weights of a neural network are replaced by tiny LSTMs allows for implementing the backpropagation LA solely by running in forward-mode. It can even meta learn new LAs that differ from online backpropagation and generalize to datasets outside of the meta training distribution without explicit gradient calculation. Introspection reveals that our meta learned LAs learn through fast association in a way that is qualitatively different from gradient descent.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at editor@thegradient.pub and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this piece, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!