

Update #31: Expectations for AI + Healthcare and 8-bit Quantization
In which we discuss the realities of AI's use in healthcare and two exciting advances in using 8-bit quantization for ML training and inference.

Welcome to the 31st update from the Gradient! If you were referred by a friend, subscribe and follow us on Twitter!
News Highlight: AI and Healthcare in 2022 - Technology, Regulation and Expectations

Summary
Healthcare and medicine has seen a large inflow of funding for AI-enabled technologies, but these systems’ performance has not met expectations. While computer vision and machine learning advances have led to better performance, models today are hindered by a lack of robust datasets to learn from. Many experts are still optimistic about the role of AI in healthcare, but they now expect AI systems to become tools that assist doctors and enable them to make decisions faster, rather than replace them.
Background
At a 2016 conference, AI pioneer Geoffrey Hinton suggested that radiologists would soon be replaced by deep learning: “people should stop training radiologists now. It’s just completely obvious that, within five years, deep learning is going to do better.” Since then, funding towards AI applications in healthcare has progressively increased, reaching $10B in 2021 and accruing $3B in the first quarter of 2022 alone. However, there remains a dearth of success stories in healthcare, as many applications for AI face administrative and regulatory hurdles.
A notable issue with applications of deep learning in medicine is deep learning’s ‘black box’ nature. In a comment to Politico, Florenta Teodoridis, a business school professor at the University of Southern California whose research focuses on AI, mentioned that not being able to explain why a model reaches a certain result is troubling when that algorithm can have life-changing impacts. Recently, the FDA published specific guidelines for radiological devices that utilize ML which require organizations to describe expected results from the algorithm and prove that it “works as intended”. Establishing these standards for current deep learning methods can be challenging as it is easier to describe the performance of a model on specific datasets, but harder to quantify its generalizability on unknown data, especially when the size of datasets available for training is small.
In addition to size, current datasets in healthcare also suffer from a lack of completeness, as any single healthcare provider does not have access to a patient’s complete medical history. Hence, many pieces of the puzzle are missing when data is fed into a model, leading to inaccuracies in the results output by the model. Many experts are also concerned about bias in these models. A 2019 study found that “a hospital algorithm more often pushed white patients towards programs aiming to provide better care than Black patients, even while controlling for the level of sickness.”
While there are many hurdles to adopting AI models for patient care, technological advancements in recent years have enabled many applications of AI in medicine. According to a trial from the Mayo Clinic, an algorithm that helps oncologists and physicians make plans for removing head and neck tumors reduced 80% of the human effort involved. Another group, led by Facebook AI Research and NYU Langone Health developed a model that reduces MRI generation time from one hour to 15 minutes. In cases like these, algorithms handle rote or mundane tasks, ultimately serving as tools for physicians who can integrate the algorithms’ results or decisions into their work as they see fit. More and more, we have seen a shift from attempting to replace doctors to developing models that can distill information and allow physicians to make quicker, better decisions for their patients.
Why does it matter?
AI’s promise to significantly improve our medical practices is alluring, but perhaps still farther than previously envisioned. Particularly in healthcare, AI systems developed to recommend treatment plans or make diagnoses must be carefully vetted before being deployed for the general public. While today’s models may fall short of expectations, we see an increasing need to improve accessibility to quality healthcare data rather than develop novel algorithms. As many exciting avenues open up for AI to improve medicine, we must remember that at least in the near future, algorithms are unlikely to replace doctors. Their primary objective will be to assist them, reduce their workload, and improve turnaround times.
Editor Comments
Daniel: I’m not entirely surprised AI in healthcare has gone the route of providing assistance for the time being. I suspect that automation of certain specialized skills may be possible–indeed, the MIT Future of Work Task Report noted that, surprisingly, highly specialized careers were at high risk for being automated as were ones involving menial work. But I expect progress to take a while. As we negotiate this “intermediate period” that looks something like partial automation, we will need to carefully study how humans interact with AI systems–it’s one thing for a machine to make a decision and act on its own (hypothetically), and entirely another for a human to be dealing with that machine and its outputs. There is not just a technical problem for the machine, but a problem of how humans interpret what machines are saying, how they use that information, the biases involved, and more (see our interview with Been Kim for more thoughts on this).
Research Highlight: 8-Bit Neural Network Quantization Advances

Summary
There have been many recent advances in neural network quantization, which reduces the precision of the activations, weights, and or biases of a neural network for increased efficiency in training and inference. One recent work develops a method to primarily use 8-bit integers for inference with large Transformer-based language models. Another work studies 8-bit floating point inference and training in various neural network architectures.
Overview
It has been known for a while that neural networks generally do not need the full numerical precision of the standard single or double precision floating point numbers (32-bit or 64-bit) that are widely used for numerical computations in other fields. Lowering the precision comes with several benefits, such as increased energy efficiency, increased memory efficiency, and often increased runtime efficiency. As such, 16-bit precision is often used for neural network training and inference; Google Brain even developed their own bfloat16 (where the B stands for Brain) 16-bit floating point format that is supported in TPUs and various NVIDIA GPUs. However, 8-bit precision formats are not as widely supported, and often come with larger degradations in numerical stability and downstream performance–training may diverge more easily due to numerical issues, for instance. Importantly, while GPUs and TPUs generally support 8-bit integer operations, they mostly do not support 8-bit floating point operations.
LLM.int8() successfully uses 8-bit quantization on trained Transformer language models to approximately halve the memory requirements for inference. The memory savings from their quantization method allow 175 billion parameter models (i.e. models of GPT-3 or OPT-175B size) to be run on consumer hardware — 8 RTX 3090 GPUs with 24 GB RAM each. Their implementation is open-sourced and integrated into the HuggingFace transformers library.
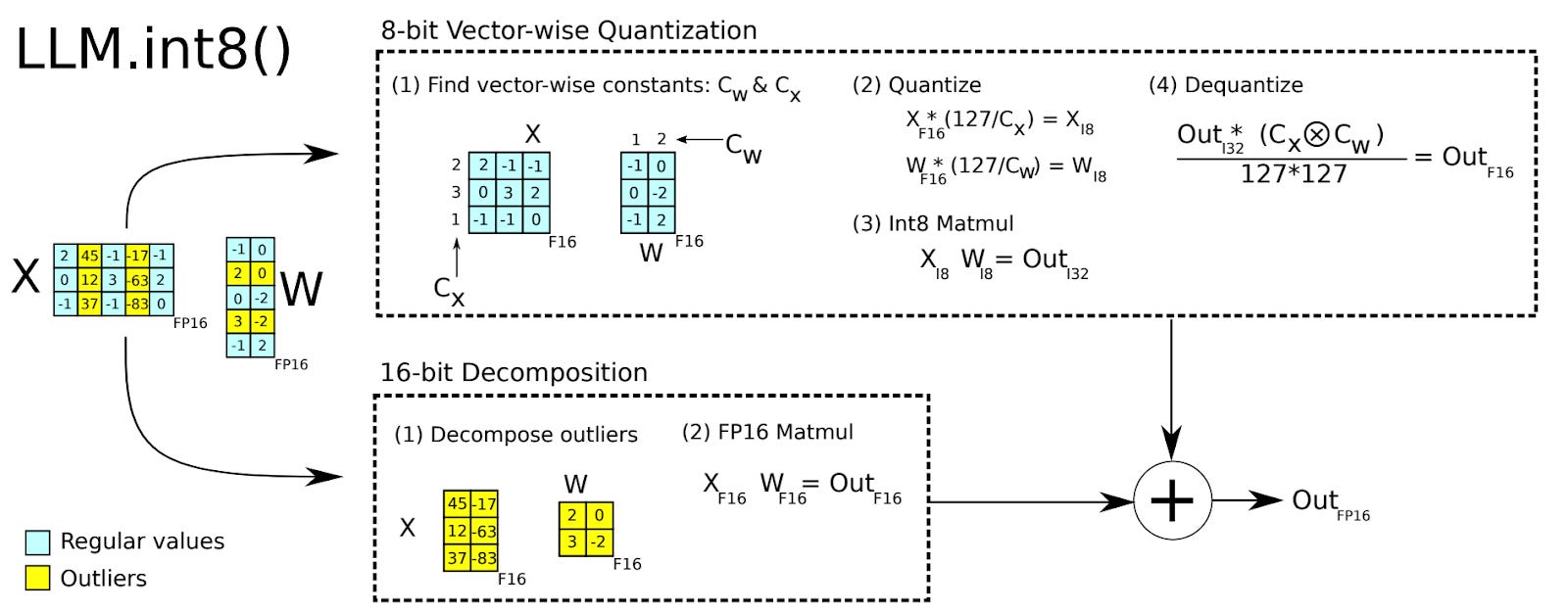
The quantization method is based on decomposing matrix multiplications into two parts. One part of the matrix multiplication is done using int8 multiplication, where each row of the input left matrix and each column of the input right matrix is quantized to int8 with different scaling constants. The second part treats certain outlier feature dimensions, multiplying them using higher precision 16-bit matrix multiplication. The authors found that these outlier feature dimensions, which contain values that are large in magnitude, very consistently emerge in Transformer language models of a certain size (at least 6.7 billion parameters) and that are sufficiently good at language modeling (as measured by perplexity). Entries of large magnitude must be dealt with carefully in quantization, because they can cause large errors when quantizing to lower precision data types.

The LLM.int8() work leveraged the int8 operations available in many accelerators, but the authors note in their paper they “believe FP8 data types offer superior performance compared to the Int8 data type, but currently, neither GPUs nor TPUs support this data type.”
Another recent paper on 8-bit floating point quantization builds an efficient implementation of a simulator for 8-bit floating point arithmetic. With this simulator, they study 8-bit floating point performance for training and post-training inference; they show that 8-bit floating point formats can achieve better performance on learning tasks than int8 for post-training inference, but int8 performs about as well for training.
Why does it matter?
Low-precision training and inference has several important benefits. A major goal of the LLM.int8() work is to further democratize access to AI by lowering hardware requirements for using large language models. Previously, enterprise hardware such as a server with 8 A100 GPUs each with 80GB RAM was required for inference of 175 billion parameter models, while now consumer hardware such as a server with 8 RTX 3090s suffices. In fact, this even allows larger models to fit on resources like Colab Pro, where one can use a 13 billion parameter language model with the new int8 quantization method.
Quantization also significantly improves energy efficiency, and often benefits runtime efficiency as well. Runtime benefits may come from allowing more vector instructions to run at once, being able to store more values in caches, and requiring less time for communication of data; but, additional operations used for quantization (such as splitting matrix multiplies into different parts as in the LLM.int8() paper) may reduce this runtime benefit.
Sources
Editor Comments
Daniel: This is really, really neat. I’m excited to see work pushing the boundaries of low-precision training and inference because, if the large model trend is to continue, we’ll need efficient methods for training and inference to make the capabilities of these models more widely accessible. Given issues with numerical instability that will inevitably arise as we push precision down further, I don’t know if we’ll get much further than int8. That being said, I did love the creativity required to make LLM.int8() work and hope this inspires further work in quantization.
New from the Gradient
Catherine Olsson & Nelson Elhage: Understanding Transformers

Been Kim: Interpretable Machine Learning

Other Things That Caught Our Eyes
News
You just hired a deepfake. Get ready for the rise of imposter employees. “New technology — plus the pandemic remote work trend — is helping fraudsters use someone else’s identity to get a job.”
Writer’s GPT-powered CoWrite handles content ‘drudgery’ and leaves creativity to humans “Writer is an AI-powered tool for checking and guiding content creators in organizations where voice and branding are essential. Its new feature CoWrite does that writing itself — but don’t worry, this isn’t quite the content apocalypse we’ve been worried about.”
The outgoing White House AI director explains the policy challenges ahead “The first director of the White House’s National Artificial Intelligence Initiative Office, Lynne Parker, has just stepped down.”
After Text-to-Image, Now it’s Text-to-Video “When OpenAI announced DALL-E in 2021, the internet fell in love with the text-to-image AI generator. It helped AI become more mainstream. While its successor, DALL-E 2, is the most popular, there are other budding AI image generators such as Midjourney, Craiyon, and Imagen.”
Papers
Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks In this work, we introduce a general-purpose multimodal foundation model BEiT-3, which achieves state-of-the-art transfer performance on both vision and vision-language tasks. Specifically, we advance the big convergence from three aspects: backbone architecture, pretraining task, and model scaling up. We introduce Multiway Transformers for general-purpose modeling, where the modular architecture enables both deep fusion and modality-specific encoding. Based on the shared backbone, we perform masked "language" modeling on images (Imglish), texts (English), and image-text pairs ("parallel sentences") in a unified manner…
Discovering Agents Causal models of agents have been used to analyse the safety aspects of machine learning systems. But identifying agents is non-trivial -- often the causal model is just assumed by the modeler without much justification -- and modelling failures can lead to mistakes in the safety analysis. This paper proposes the first formal causal definition of agents -- roughly that agents are systems that would adapt their policy if their actions influenced the world in a different way. From this we derive the first causal discovery algorithm for discovering agents from empirical data, and give algorithms for translating between causal models and game-theoretic influence diagrams…
Towards Learning Universal Hyperparameter Optimizers with Transformers In this paper, we introduce the OptFormer, the first text-based Transformer HPO framework that provides a universal end-to-end interface for jointly learning policy and function prediction when trained on vast tuning data from the wild… OptFormer can imitate at least 7 different HPO algorithms, which can be further improved via its function uncertainty estimates.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at gradientpub@gmail.com and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! For feedback, you can also reach Daniel directly at dbashir@hmc.edu or on Twitter. If you enjoyed this piece, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!