

New Datasets to Democratize Speech Recognition Technology
Presenting the The People’s Speech, a massive English-language dataset of audio transcriptions, and the Multilingual Spoken Words Corpus (MSWC), a 50-language, 6000-hour dataset of individual words

New Datasets to Democratize Speech Recognition Technology
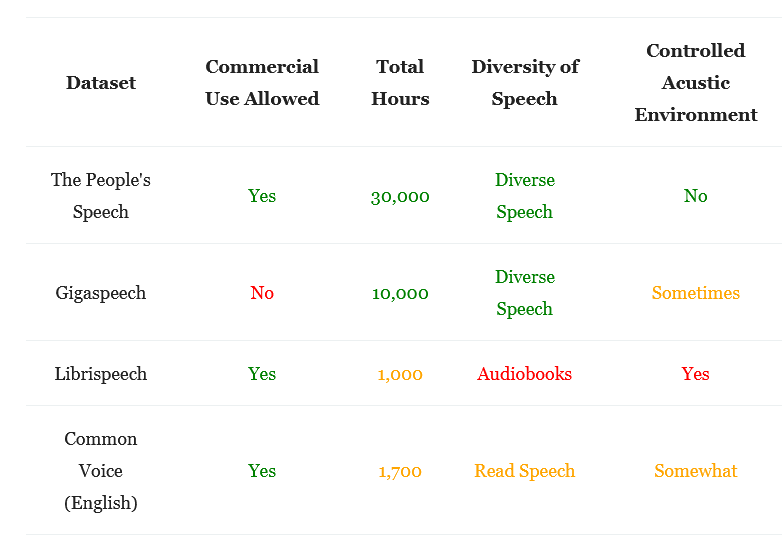
Over the last year, we at MLCommons.org set out to create public datasets to ease two pressing bottlenecks for open source speech recognition resources. We created The People’s Speech, a massive English-language dataset of audio transcriptions of full sentences, and the Multilingual Spoken Words Corpus (MSWC), a 50-language, 6000-hour dataset of individual words. Together, these datasets greatly improve upon the depth (TPS) and breadth (MSWC) of speech recognition resources licensed for researchers and entrepreneurs to share and adapt.
Read the article for audio samples!