

Gradient Update #25: Algorithmic Child Neglect Screening and A Generalist Agent
In which we discuss concerns about an algorithm that predicts child neglect and DeepMind's Gato.

Welcome to the 25th update from the Gradient! If you were referred by a friend, subscribe and follow us on Twitter!
News Highlight: An algorithm that screens for child neglect raises concerns

Image Source: AP Illustration by Peter Hamlin
Summary
A recent study from Carnegie Mellon University researchers raises alarms about a predictive algorithm used by Pennsylvania’s Allegheny County to determine which families should be investigated by the county’s child welfare agency. The study shows that the algorithm, developed at a significant cost to the county, has no effect on reducing racial disparities and biases in the screening process. While county officials still support the algorithm and claim that social workers ultimately have the decision making power, the algorithm has played a pivotal role in various court hearings and made an impact on the lives of many families over the past 6 years.
Background
Pennsylvania’s Allegheny County deployed the Allegheny Family Screening Tool (AFST) in August 2016 with the goals of automating the pipeline for screening calls received on the child services hotline and reducing biases and disparities currently present in the system. The algorithm was developed by Emily Putnam-Hornstein, a professor at the University of North Carolina at Chapel Hill’s School of Social Work, and Rhema Vaithianathan, a professor of health economics at New Zealand’s Auckland University of Technology. The researchers first collaborated a decade ago to work on a similar predictive risk algorithm for child services in New Zealand, which was not deployed due to concerns of bias.
The AFST uses data from government agencies and public programs to predict the risk of a child being placed in foster care in the next two years. The process works as follows: first, individuals report cases of potential neglect to the county’s child protection hotline. Next, each case goes through the screening algorithm which assigns a risk score from 1 through 20 (20 being the highest) to the family, or suggests a “Mandatory Screening”. Lastly, this score is reviewed by a social worker, who then decides if a case should be investigated or not. In theory, the role of the algorithm is only to support social workers in making decisions, and not to make standalone decisions at any point in the process.
The paper published by CMU researchers shows that the model is no better at recommending which cases to investigate than humans, and that if used alone, it would produce outcomes with worse racial disparities. In data collected from 2016-18, the AFST model alone had an accuracy of ~43% for black children, and an accuracy of ~57% for white children (a recommendation by the algorithm to investigate a case was considered accurate if the child was re-referred to the hotline within 2 months, or if the child was put in foster care within 2 years of the initial referral).
It is also worth noting that race is not explicitly an input variable to the model, but many experts argue that other metrics, such as participation in public welfare programs – which are used by the algorithm – serve as good proxies for race. County officials and algorithm developers welcomed research into their algorithm, but claimed that the CMU study is based on extrapolations and old data. In response, the CMU team recently re-ran their analysis on new data and found no change in their conclusions. Additionally, an unpublished analysis written by the developers of the algorithm also found that the algorithm had “no statistically significant effect” on reducing racial disparity in the screening system.
Why does it matter?
Predictive risk models, such as AFST, are used by many counties across the United States to assist social workers. While Allegheny County does not allow families to know their algorithm-generated risk score, some other counties provide that information to families, or deliver it upon request. There are also many concerns regarding transparency, as Allegheny County has not shared details about which factors its algorithm considers, or made the algorithm publicly accessible. Given that the recommendations of the model show higher rates of racial disparity when not reviewed by a human, public workers and family lawyers are concerned about the outcomes if a county were to deploy such an algorithm without human intervention in the future.
A core assumption behind this methodology of creating a risk assessment model is that data about a family’s financial history and participation in public programs can reliably predict their likelihood of neglecting a child. It is worth asking as ML researchers that while models can use priors to learn object features or optimal control trajectories, can they also predict human behavior? Do we draw the line on using an algorithm trained on hard quantitative data to predict how a child will be cared for by their family?
Perhaps the most chilling result of this experiment is the case of a family from 2018, as shared by their lawyer, Robin Frank. Their case was screened by the algorithm, and eventually brought to court. During the court hearing, a social worker discussed the mother’s risk score generated by the algorithm – a number that county officials did not intend to be used as evidence. Neither the lawyer nor the officials know how the score ended up in court, or what impact it had on the result of the hearing. The algorithm continues to be deployed today as a black-box with no avenues for investigation.
Editor Comments
Daniel: Another example, I think, of pigeonholing a problem and assuming that ML algorithms are the best way to solve it. I wish we’d back up a bit and think about the problem that’s actually being solved here: to me, one version of this looks something like “how do we effectively decide which families to investigate for child neglect?” The way to go about thinking through this problem, to me, isn’t: “we have data, let’s do some supervised learning.” Rather, we can stay at this level of abstraction or even back up a bit to investigate the structures (at societal or family levels) that might cause child neglect. I’m glad CMU has raised alarms about this algorithm, but we can’t keep waiting for potentially concerning algorithms like these to be deployed and hope that there is enough public backlash for actual governance ot occur.
Paper Highlight: A Generalist Agent (Gato)
Source: Gato Paper
Summary
DeepMind’s new Gato agent is a single model capable of accepting multiple types of inputs, and generating multiple types of outputs that achieve various tasks. Gato is able to achieve expert or near-expert level performance on tasks including playing Atari games, captioning images, stacking blocks with a real robot arm, and various simulated control tasks. Gato’s architecture is simple and inspired by large language models.
Overview
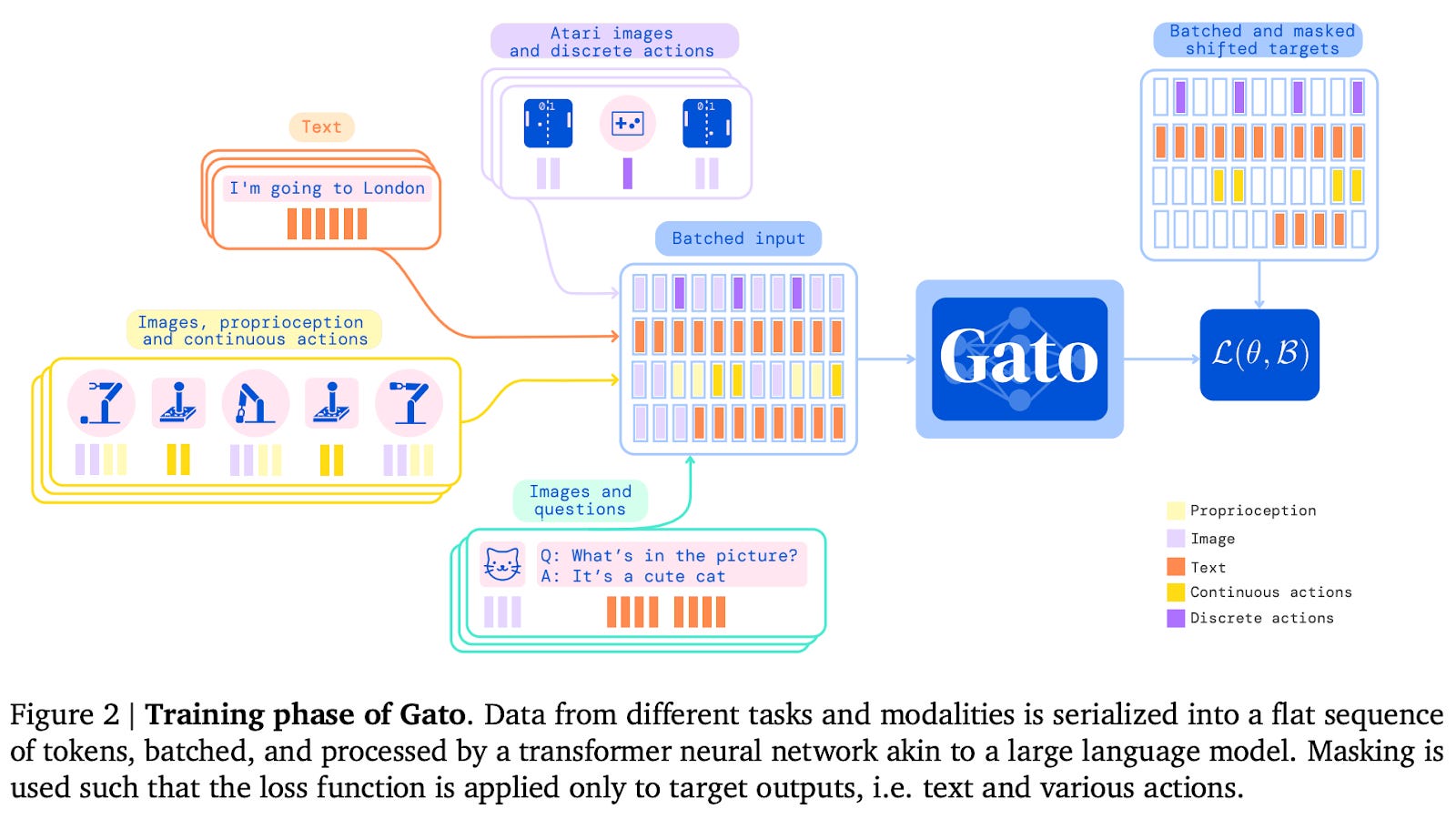
The Gato architecture uses a single Transformer decoder to process inputs and generate outputs much like standard large language models. Inputs from various modalities are tokenized, embedded, and given positional encodings. For instance, images are converted into 16x16 patches as in ViT, text is tokenized by a subword tokenizer, and discrete values like Atari button-presses are treated as sequences of integers. Discrete tokens are given learnable embeddings from a look-up table, and image tokens are embedded with a ResNet.
Given an input sequence, Gato outputs next token predictions. As Gato takes various types of tokens from different modalities as input, Gato can also output tokens of different modalities: it can predict the next text tokens that follow a sequence of text, or it can output tokens representing actions that an agent can make in a control task. During training, Gato’s weights are updated so as to maximize the probability of predicting the correct text token or agent action given the sequence of tokens preceding it. In other words, a standard language modeling loss is used, where the loss is only computed over predicted text and action tokens. In particular, a simple form of behavior cloning is used to train the agent on control tasks, which requires trajectories from other SOTA agents doing the task.
Gato is trained on a collection of diverse control tasks and several language and vision datasets. There are 596 different control tasks with about 63 million total episodes. The other datasets include the large MassiveText text dataset, image caption datasets, and the M3W dataset (also used in Flamingo) of multimodal web page data. Training is done on sampled batches of sequences from these datasets, with some higher probability placed on sampling from higher quality datasets.
The largest Gato model that DeepMind trained has about 1.2 billion parameters, which is much smaller than other large pretrained Transformers. This small size is chosen to allow real-time control of real robots, so future improvements in inference time could allow larger Gato-like models. Nonetheless, Gato achieves expert or near-expert performance in many of the diverse tasks that it is tested on. On 450 of the 604 tasks, it exceeds 50% of expert performance. Also, it reaches average human performance on 23 Atari games, and even doubles the human score for 11 games. The natural language capabilities of Gato are not that strong, but it appears able to answer a few questions in a conversation and generate some reasonable image captions.
Why does it matter?
Gato is the first empirical demonstration of a single trained model that is able to handle many tasks across different modalities. Earlier work includes the MultiModel, which handles 8 tasks with an architecture that includes modality-specific encoders unified with many shared parameters, and theoretical proposals for “One Big Net For Everything”. While many other works like Perceiver and Decision Transformers use the same architecture for different tasks or modalities, they usually have to retrain and learn a different set of weights for each task. In this sense, Gato is much more general than previous models.

Moreover, the largest Gato model is rather small compared to other large language-model-like architectures, with only 1.2 billion parameters. In contrast, DALL-E has 12 billion, GPT-3 has 175 billion, Flamingo has 80 billion, and PaLM has 540 billion. Furthermore, the authors demonstrate a scaling law of Gato, in which performance consistently increases when increasing the number of parameters and the number of tokens processed. Thus, with future improvements to hardware or algorithms, a larger version of Gato would be expected to perform much better with similar latency. If latency is not an issue for some set of tasks under consideration, then a large Gato can be trained on those tasks right this moment.
Editor Comments
Daniel: It’s been repeated enough times that Gato is another interesting byproduct of the “blessings of scale” and how you can take the “dumbest” thing and reap incredible rewards from it. Even some DeepMinders like David Pfau are not impressed–Pfau notes that this result is not surprising, and Gato indeed takes the approach of lifting the RL problem into a supervised learning problem. Like Pfau, I think the right take is that this is neat, but we haven’t solved the problem Gato is attacking just yet. That being said, I do think there will be some interesting engineering problems as we continue exploring how today’s models scale up along various dimensions, and am excited to see what innovations come on that side.
Derek: I find the basic architecture and input/output format pretty interesting. It reduces so many problems to just tokenizing the data, adding positional encodings, and decoding in a way that minimizes a simple supervised or self-supervised loss. Many other works have done this with Transformers to some extent, but seeing it work with this many different tasks and modalities is pretty cool.
New from the Gradient
David Chalmers on AI and Consciousness

Yejin Choi: Teaching Machines Common Sense and Morality

Other Things That Caught Our Eyes
News
Inflection AI, led by LinkedIn and DeepMind co-founders, raises $225M to transform computer-human interactions “Inflection AI, the machine learning startup headed by LinkedIn co-founder Reid Hoffman and founding DeepMind member Mustafa Suleyman, has secured $225 million in equity financing, according to a filing with the U.S. Securities and Exchange Commission.”
Investors pull back on artificial intelligence “Funding for AI-focused health startups fell 32% in Q1 2022, after nine straight quarters of steady growth, according to a fresh analysis from CB Insights.”
How A.I. Is Changing Hollywood | WIRED “Behind some of the coolest premium effects in Hollywood is the invisible aid of artificial intelligence. Machine learning is helping create previously unimaginable moments in media today, like in shows and movies like 'Wandavision' and 'Avengers: Endgame.'”
Apple Executive Who Left Over Return-to-Office Policy Joins Google AI Unit “An Apple Inc. executive who left over the company’s stringent return-to-office policy is joining Alphabet Inc.’s DeepMind unit, according to people with knowledge of the matter.”
Papers
Chain of Thought Prompting Elicits Reasoning in Large Language Models Although scaling up language model size has reliably improved performance on a range of NLP tasks, even the largest models currently struggle with certain reasoning tasks… This paper explores the ability of language models to generate a coherent chain of thought… Experiments show that inducing a chain of thought via prompting can enable sufficiently large language models to better perform reasoning tasks that otherwise have flat scaling curves. When combined with the 540B parameter PaLM model, chain of thought prompting achieves new state of the art of 58.1% on the GSM8K benchmark of math word problems.
LinkBERT: Pretraining Language Models with Document Links existing [Language model (LM) pretraining] methods such as BERT model a single document, and do not capture dependencies or knowledge that span across documents. In this work, we propose LinkBERT, an LM pretraining method that leverages links between documents, e.g., hyperlinks. Given a text corpus, we view it as a graph of documents and create LM inputs by placing linked documents in the same context. We then pretrain the LM with two joint self-supervised objectives: masked language modeling and our new proposal, document relation prediction. We show that LinkBERT outperforms BERT on various downstream tasks across two domains: the general domain (pretrained on Wikipedia with hyperlinks) and biomedical domain (pretrained on PubMed with citation links)... We release our pretrained models, LinkBERT and BioLinkBERT, as well as code and data at this https URL.
Training Vision-Language Transformers from Captions Alone We show that Vision-Language Transformers can be learned without human labels (e.g. class labels, bounding boxes, etc). [Training the visual backbone on ImageNet class prediction before being integrated into a multimodal linguistic pipeline] is not necessary and introduce[s] a new model Vision-Language from Captions (VLC) built on top of Masked Auto-Encoders that does not require this supervision… we find that our approach 1. outperforms ViLT on standard benchmarks, 2. provides more interpretable and intuitive patch visualizations, and 3. is competitive with many larger models that utilize ROIs trained on annotated bounding-boxes.
Tweets
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at gradientpub@gmail.com and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! If you enjoyed this piece, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!