

Gradient Update #24: Robotaxis in Beijing and a Multi-task Visual Language Model
In which we discuss Baidu and Pony.ai's license to operate AVs without safety drivers in Beijing and DeepMind's new visual language model Flamingo.

Welcome to the 24th update from the Gradient! If you were referred by a friend, subscribe and follow us on Twitter!
News Highlight: Baidu and Pony.ai become first robotaxi services to operate without safety drivers in Beijing

Summary
Autonomous vehicles (AVs) are one of the most anticipated products of AI research in the past few decades. While there are many technical challenges still to be overcome before level 5 autonomy can be achieved, regulatory progress in this domain remains equally important. China recently took a significant step in this direction by allowing two companies, Baidu and Pony.ai, to operate self-driving cars without safety drivers in Beijing, a first for the country.
Background
While advances in AI have propelled the field of autonomous driving, regulatory response to this rapid technological development has largely been slow. According to a 2022 report, 22 countries have introduced legislation that allow testing AVs in some capacity, but only five of them allow for AVs to be driven on roads beyond testing. In the United States, 38 states have passed legislation that allows autonomous vehicles to be driven with varying caveats. California leads the country, giving its approval in three tiers: 48 companies have permits to test AVs with a safety driver, 7 companies can test AVs without a safety driver, and only 3 (Waymo, Cruise and Nuro) have a license to deploy AVs on public roads.
China has recently seen a rush in AV development, with more than $8.5 Billion being invested into Chinese robotaxi startups in 2021. Government support is a huge contributor to this success, as regulators have introduced a slew of legislation and roadmaps for introducing AVs on public highways and city roads in the past few years. In a landmark decision in August 2021, the Chinese government eased restrictions on driverless testing, allowing companies to petition for a license to test their AVs without a safety passenger. In November 2021, Baidu and Pony.ai received approval to launch paid robo-taxi services in Beijing’s Yizhuang region with a safety driver present. Following this chain of events, on April 30th this year, both companies received a license to operate their AVs without a safety driver, this time limited to a 23 square mile region in Yizhuang. The regulations do require a ‘supervisor’ to be present in the car, just not in the driver’s seat strictly. Nevertheless, this move marks the first time AVs will be allowed to drive on public roads with an empty driver seat, and continues a series of recent wins for Baidu and Pony.ai. Pony.ai previously also became the first company to receive a taxi license in China (with a safety driver), but had their driverless license in California suspended when one of their AVs collided with a center divider.
Why does it matter?
The development of safe and reliable AVs is dependent on a strong relationship between regulators and tech companies; while regulators must provide companies with opportunities to test and deploy their cars in the real world, they also need to ensure that this advancement doesn’t come at the cost of public safety. Many countries in the world have begun to warm up to AVs, and it is encouraging to see China join the list, allowing fully driverless testing of autonomous vehicles. This step is not just important for companies to properly evaluate their algorithms in production-like settings, but also helps build public confidence in the technology that is aimed to be offered as a paid taxi service by many, including Baidu and Pony.ai. These decisions set the stage for more countries to follow suit and allow for AVs to be tested without the training wheels.
Editor Comments
Ather: It is encouraging to see that autonomous vehicles are gaining the confidence of regulators and policy-makers in other parts of the world besides the United States. Recent studies like the ones by Virginia Tech and Tesla, suggest that AVs are fairly safe and reduce the number of car crashes and injured persons as a result thereof. But till we can be fully at ease with having unmanned vehicles on the roads driving alongside us, increasing the testing ground for AVs should bring in more data regarding their unsurfaced, potential pitfalls.
Daniel: I agree that we need to incrementally expand the scope of testing allowed for AVs, and I’m glad to see that these permissions don’t seem to be given wholesale (although Beijing may be a different story). Baidu has previously been granted approval to test cars without safety drivers in Sunnyvale, while Pony.ai was given approval in three California cities–its license in one was revoked due to an accident involving one of its vehicles. I think the incremental approach of (a) restricting where the vehicles can operate and (b) requiring a supervisor present somewhere in the vehicle is a good one. But issues with generalization abound, and so this incremental approach will need to be kept–the next step should not be a license to drive around all of Beijing with no supervisor at all. I think this approach will help us better understand their capabilities and failings as the scope of AV use increases over time.
Paper Highlight: Tackling multiple tasks with a single visual language model

Source: Deepmind blog post
Summary
DeepMind’s new Flamingo model is a Visual Language Model (VLM) that demonstrates many new capabilities for multimodal AI. Flamingo is trained on uncurated web data, can handle sequences of text and visual input in arbitrary order, and can process both images and video. It achieves state of the art performance in few shot learning, and surpasses models that are trained on significantly more task-specific data.
Overview
Flamingo has many capabilities that are not present in any VLMs from prior works. It is able to process images, video, and text presented in arbitrary orders. Since it is trained on uncurated data, Flamingo is likely to learn more general information beyond the structure that might be present in a curated dataset. Also, the structure of Flamingo allows it to be prompted using both visual and textual data. This allows for flexible prompting for visual question answering and also for conversations that include images.
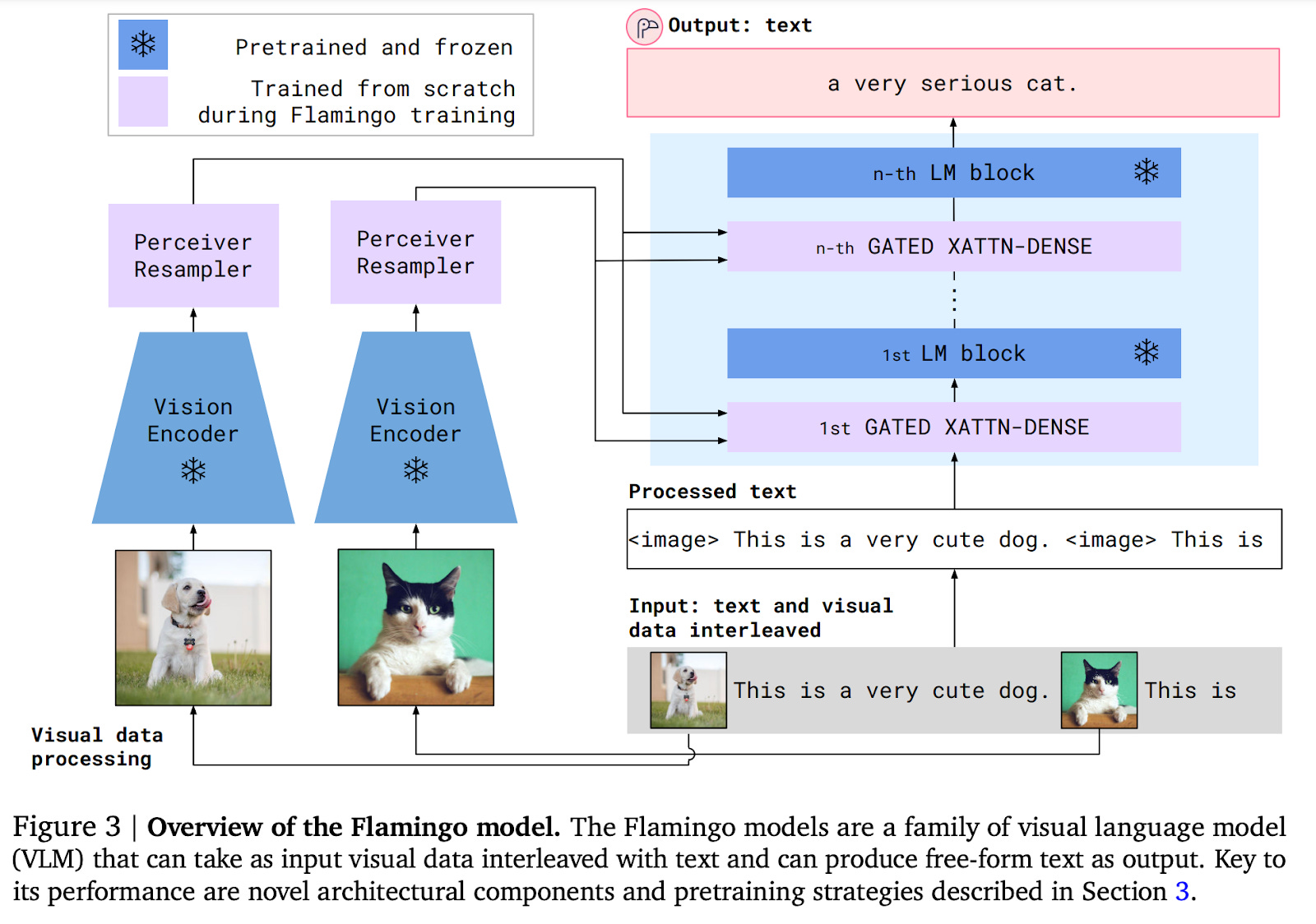
Flamingo integrates a powerful pretrained language model and vision model into a single framework, thus taking advantage of well-understood single modality foundation models. For language, Flamingo uses a pretrained Chinchilla language model with 70 billion parameters. For vision, Flamingo uses a contrastively pretrained Normalizer Free ResNet (NFNet) with 435 million parameters. During training, the parameters of these two models are frozen. And once it’s complete, Flamingo can be directly adapted to vision tasks via simple few-shot learning without any additional task-specific finetuning.
To allow these single modality modules to communicate, Flamingo uses cross attention modules, in which each language token attends to the nearest visual token that came before it in the sequence. For instance, in an input of the form “<image 1> is a duck. <image 2> is a goose.”, the token “goose” would attend only to image 2. These cross attention models are trained while the pretrained single modality backbones are kept fixed. Moreover, Flamingo uses a resampler based on DeepMind’s Perceiver to process varying numbers of visual tokens (e.g. varying number of frames in a video) into a fixed number of visual tokens.
The types of data and ways in which Flamingo uses the data is also notable. While uncurated web-scraped data has been successfully used for single modality training of large language models and vision models, such data has not found much success for multimodal models. Flamingo is trained on a new multimodal dataset introduced in the paper, which consists of 43 million web pages with interleaved images and text.
Why does it matter?
The engineering and architectural innovations in Flamingo lead us to more generally capable, flexible multimodal AI. It can take in more general input: images, video, and text presented in arbitrary order, which allows for prompt engineering and prototyping with uncurated data. Also, it generates text output, which allows it to do more tasks than other multimodal models.
Flamingo leverages two sources of strength: pretrained single modality models, and uncurated multimodal data. The researchers solved certain problems that arise in integrating single modality models with each other and using uncurated multimodal data, which allow Flamingo to use these powerful tools. As more work and computational resources are used to improve the single modality models and collect more data, the successors of Flamingo will improve as a consequence.
Editor Comments
Ather: Today, researchers and engineers spend a big chunk of their time in cleaning and preprocessing the data before training a model on it. Hence, Flamingo’s ability to take in both textual and visual data that is both arbitrary and uncurated is particularly useful. It should allow teams to prototype and train models faster without spending substantial time in data cleaning and preprocessing.
Daniel: Flamingo combines two exciting trends that have already overlapped–multimodal models and few-shot learning. Its ability to combine pre-trained vision and language models and perform a variety of tasks doesn’t seem massive in and of itself, but DeepMind’s architectural innovations make this quite interesting. Its ability to be further fine-tuned to SOTA performance on harder benchmarks like HatefulMemes is a good indication of progress on these difficult problems, which I’m excited to see. It’s worth noting that, as with anything using a pre-trained model, Flamingo will inherit issues/biases in the models composing it.
Derek: Flamingo’s generality also impresses me; it is really nice that it can take in interleaved image, video, and text data. The ability for Flamingo to answer questions about a complex image are quite impressive, though it is unclear whether this image and discussion about it are included in Flamingo’s massive training dataset.
New from the Gradient
Beyond Message Passing, a Physics-Inspired Paradigm for Graph Neural Networks

Focus on the Process: Formulating AI Ethics Principles More Responsibly
Deep Learning in Neuroimaging

Other Things That Caught Our Eyes
News
What’s New in Spot | Boston Dynamics “We’re excited to announce the latest advancements to Spot’s hardware and ecosystem.”
Singaporean wins $100k prize in challenge to build AI models that detect deepfakes “A one-man team comprising Singaporean research scientist Wang Weimin beat 469 other teams from around the world in a five-month-long challenge to develop the best artificial intelligence (AI) model for detecting deepfakes.”
UK Regulators' Path for AI Starts with Auditing Algorithms “The Digital Regulation Cooperation Forum (DRCF), a group of four U.K. regulators, published last week, April 28 two documents where it provided businesses with guidance about the benefits and risks of artificial intelligence (AI) and machine learning (ML) and how to audit algorithms.”
Intel wins DARPA RACER-Sim program “The Defense Advanced Research Projects Agency (DARPA) intends to continue the innovation of autonomous off-road vehicles (AKA unmanned guided vehicles).”
Papers
LEARNING TO EXTEND MOLECULAR SCAFFOLDS WITH STRUCTURAL MOTIFS Recent advancements in deep learning-based modeling of molecules promise to accelerate in silico drug discovery… Here, we propose MoLeR, a graph-based model that naturally supports scaffolds as initial seed of the generative procedure…. MoLeR performs comparably to state-of-the-art methods on unconstrained molecular optimization tasks, and outperforms them on scaffold-based tasks, while being an order of magnitude faster to train and sample from than existing approaches.
Federated Learning with Buffered Asynchronous Aggregation Scalability and privacy are two critical concerns for cross-device federated learning (FL) systems. In this work, we identify that synchronous FL - synchronized aggregation of client updates in FL - cannot scale efficiently beyond a few hundred clients training in parallel… On the other hand, asynchronous aggregation of client updates in FL (i.e., asynchronous FL) alleviates the scalability issue… we propose a novel buffered asynchronous aggregation method, FedBuff, that is agnostic to the choice of optimizer, and combines the best properties of synchronous and asynchronous FL…
Where Do You Want To Invest? Predicting Startup Funding From Freely, Publicly Available Web Information We consider in this paper the problem of predicting the ability of a startup to attract investments using freely, publicly available data. We… study here whether one can solely rely on readily available sources of information, such as the website of a startup, its social media activity as well as its presence on the web, to predict its funding events. As illustrated in our experiments, the method we propose yields results comparable to the ones making also use of structured data available in private databases.
Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at gradientpub@gmail.com and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! If you enjoyed this piece, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!