

Gradient Update #19: Woes of the IRS, Deep RL in Nuclear Fusion
In which we cover non-facial recognition options for the IRS to verify identity and DeepMind's recent application of deep reinforcement learning to nuclear fusion.

Welcome to the 19th update from the Gradient! If you were referred by a friend, subscribe and follow us on Twitter!
News Highlight: Face Recognition Is Out. So How Will the IRS Verify Identity?

Source, Photograph: Miroslav Prouza / Getty Images
Summary
The USA Internal Revenue Service (IRS) will stop using facial recognition to verify the identity of users signing up for new accounts on its website. The identity verification process was unveiled in November 2021, and quickly drew scrutiny from various critics. The November announcement was not without motivation: government disbursements during the COVID-19 pandemic often failed to reach their intended recipients due to identity fraud. This is the latest of several facial recognition systems to be terminated in the last few years, following restrictions from tech giants like Facebook, Microsoft, and Amazon.
Background
Recent data breaches and hacks have leaked taxpayer information from the IRS. The leaked personal information–including social security numbers and home addresses–has enabled identity fraud and theft of stimulus checks during the COVID-19 pandemic. In June 2021, the US Treasury Department, which includes the IRS, entered an 86 million dollar contract with the online identity verification company ID.me. As government assistance in the form of stimulus checks and unemployment funds were distributed at higher rates during the COVID-19 pandemic, many states and government agencies contracted with ID.me to verify identities of claimants.
As we covered in an earlier newsletter, Meta’s Facebook stopped using facial recognition in November 2021. In the summer of 2020, Amazon, IBM, and Microsoft put moratoriums on selling facial recognition technology to police in the wake of protests against racial discrimination and police brutality. These decisions and public debate around the technology were in part driven by studies that have discovered intersectional biases in facial recognition systems.
Why does it matter?
Identity verification and fraud detection is important for the IRS and other government agencies — some estimate that tens of billions of dollars of the disbursements under the pandemic era CARES Act were misspent. Such fraud reduces the amount of taxpayer money that goes to helping American citizens, and directly harms citizens who are reliant on stolen relief money.
Given the issues found with facial recognition systems, other types of digital identity verification systems have been proposed. For instance, digital identity systems are being developed in the EU and certain states in the USA; Apple has partnered with several states to add driver’s licenses to Apple Wallet. However, digital identity systems could also impede privacy and security. An ACLU report notes that digital IDs could reduce the friction for showing IDs. As a result, ID checks may become more frequent or even automated, both online and offline. If ID checks become a more frequent occurrence in daily life, governments and other organizations will have a far more detailed picture of citizens’ habits and activities than they do today.
Digital identity checks also require technology that not everyone has constant access to. Digital driver’s licenses, for instance, would require a smartphone and internet access. ID.me’s standard workflow for identity verification requires a smartphone in addition to another device.
Editor Comments
Derek: These new types of identity verification remind me of the IDNYC government-issued ID card for New York City residents. This system was put in place to help those who may struggle to get other forms of identity verification, such as immigrants. However, especially after the launch of the program, IDNYC holders faced stigma. For instance, many financial institutions still do not accept IDNYC cards for identity verification. I could imagine that someday, people who still use paper forms or do not have digital driver’s licenses could face similar stigma.
Daniel: This is a really tricky issue. On the one hand, digital identity checks make a lot of sense given the prevalence of identity theft, and to be as secure as possible those checks should involve something that can’t be stolen easily. I don’t know if there’s a right answer here—forms of identity verification that sacrifice some privacy may be our best bet. As with many other technologies that have concerning implications for privacy, the trade-offs are not obvious. Similar identity verification systems do already exist, and I feel we should not be hasty to endorse or dismiss more comprehensive or advanced systems.
Andrey: It’s interesting to see this story develop. By itself it’s not a big deal, but I do think it speaks to the likelihood of such face verification systems becoming commonplace in the coming years. Many airports already use them, and I would not be surprised if it becomes standard for all sorts of services. In general I think the convenience of such an identity verification is useful, but of course it’s important that these things are implemented well.
Paper Highlight: Magnetic control of tokamak plasmas through deep reinforcement learning
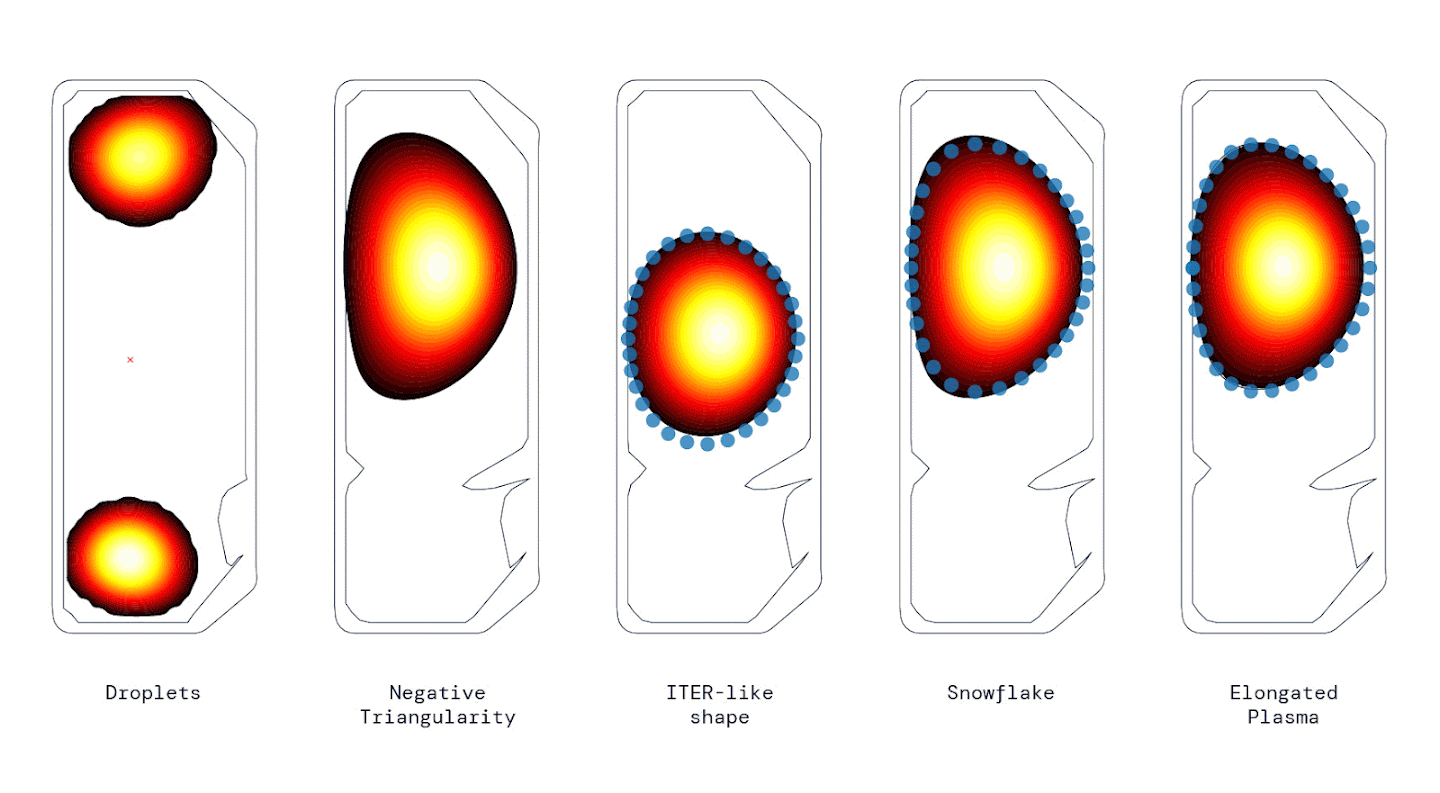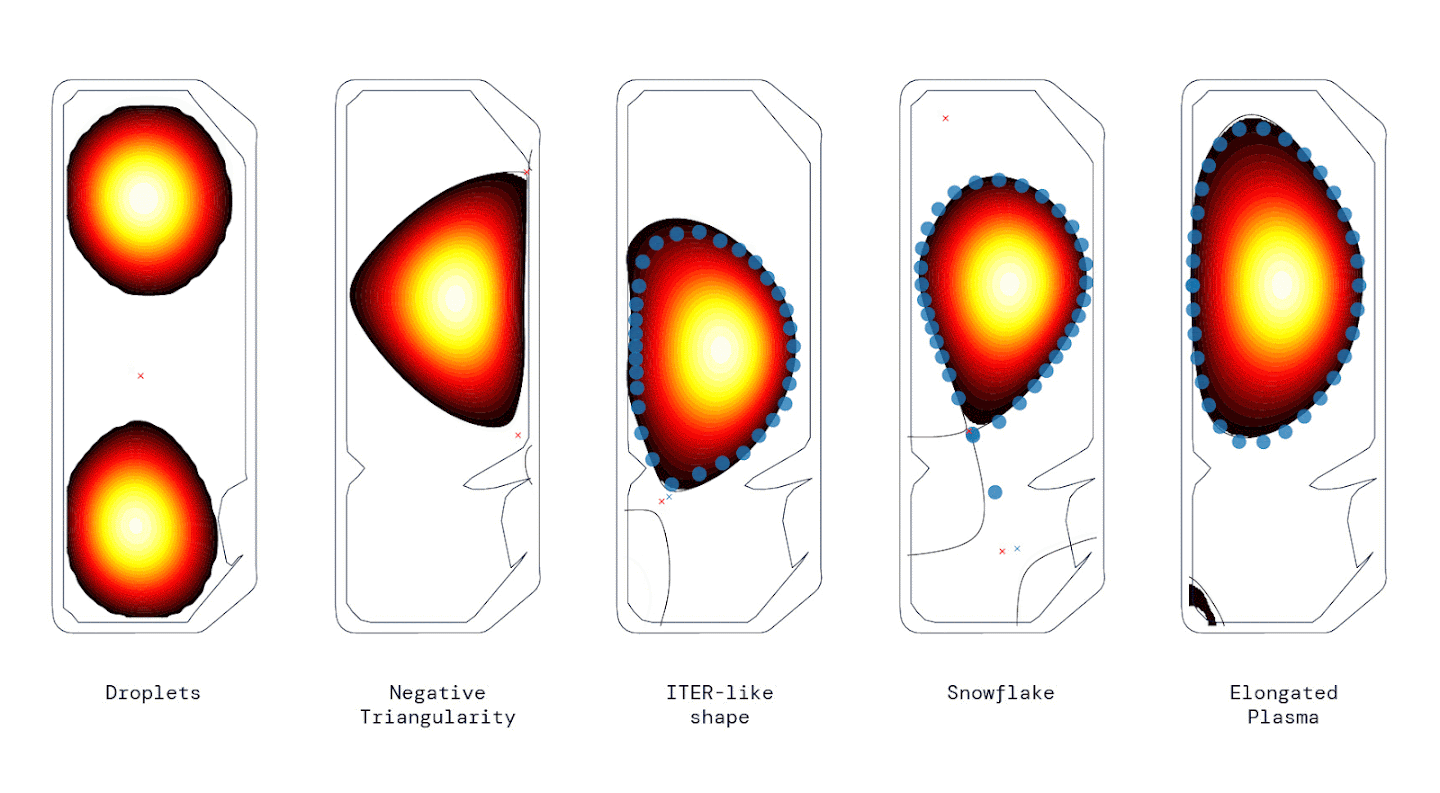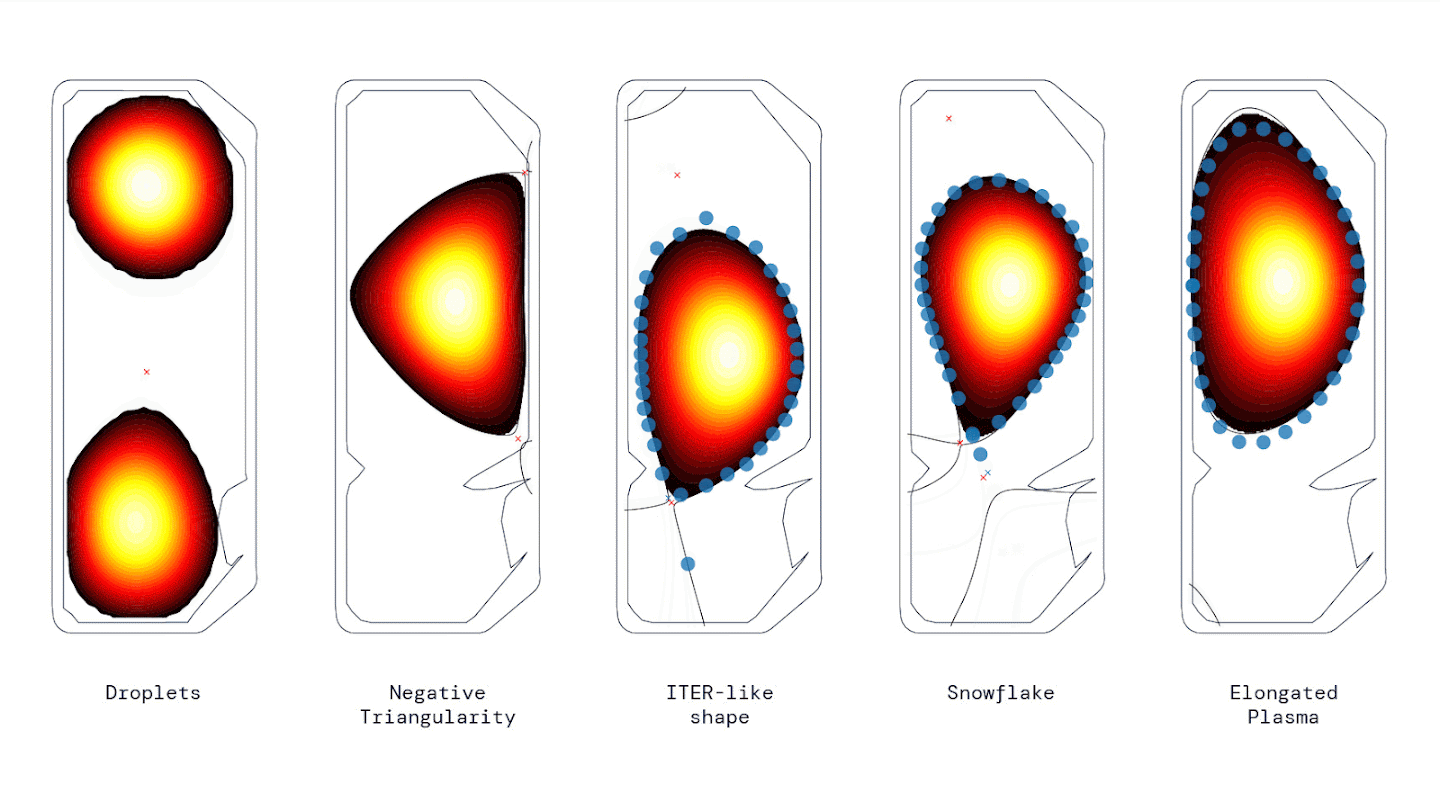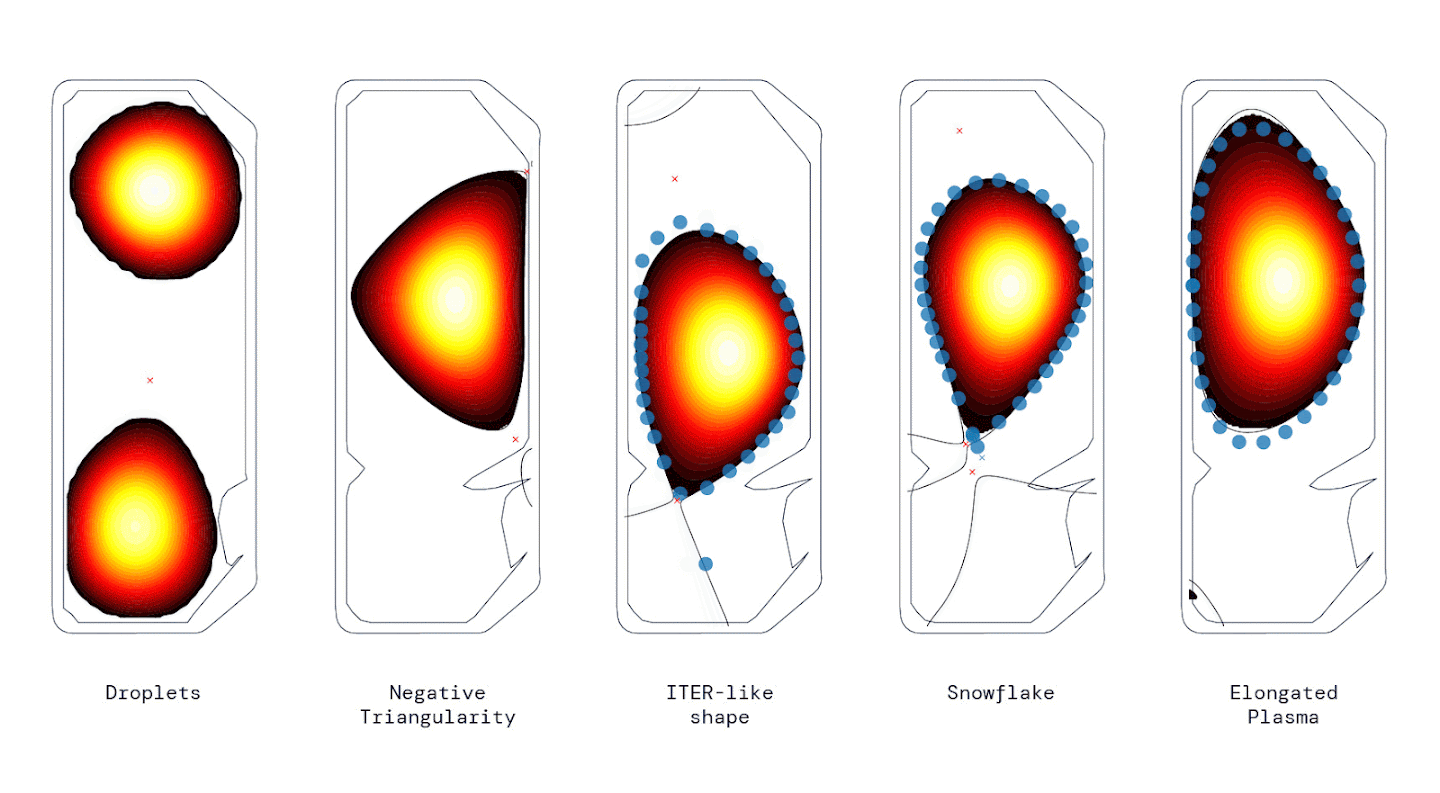
Hydrogen plasma configurations inside a Tokamak stabilized by DeepMind’s reinforcement learning method. Image Source: DeepMind/EPFL
Summary
Continuing its pursuit of applying AI to the natural sciences, DeepMind successfully stabilized hydrogen plasma inside a Tokamak using reinforcement learning. Developed in collaboration with scientists at EPFL - the Swiss Federal Institute of Technology Lausanne - the novel methodology provides a simpler, more intuitive solution to the task and paves the way for rapid developments at the intersection of deep learning and nuclear fusion research.
Overview
Nuclear fusion has long been considered as a front-runner for sustainably generating electricity, and a tokamak is the leading plasma confinement concept for future fusion power plants. A tokamak uses multiple magnetic coils to stabilize hydrogen plasma in a vacuum in various configurations such as droplets, snowflakes, and elongated plasma. While the current solution to this task is effective, it requires “substantial engineering effort, design effort and expertise whenever the target plasma configuration is changed”, according to the authors of the paper. Their solution introduces a control policy trained through reinforcement learning that can directly vary the voltages on the magnetic coils in a tokamak, thereby eliminating the need for re-engineering the system for each configuration. In order to achieve this, the scientists first developed a highly physically-accurate simulation environment for the tokamak, and then trained a policy in this setting, architectured as a Multi-Layer Perceptron with 3 Hidden Layers of 256 parameters each. The policy was further optimized using maximum a posteriori policy optimization (MPO) and tested on a real tokamak. Their results show that the near-optimal-policy required no fine-tuning in the ‘sim-to-real’ transfer and could be deployed directly from simulation to successfully stabilize multiple plasma configurations (see animated image for reference).
Why does it matter?
Nuclear fusion presents an untapped but highly rewarding opportunity as an energy source. Electricity generated from this reaction has “no emissions, minimal waste, and there is no risk of out-of-control meltdowns like Chernobyl. The fuel, derived from helium or hydrogen, is cheap and plentiful.” This work presents a significant step towards advancing the development of fusion technologies. According to Dimitri Orlov, an assistant research scientist at the UC San Diego Center for Energy Research, machine learning models could not only be used to prevent “plasma instabilities”, but also allow for better and faster control over highly complex tokamaks (Wired Magazine, Feb 16, 2022). Furthermore, this research presents a successful use case of AI in a highly complex setting with a zero-shot sim-to-real transfer, which certainly marks a milestone for modern day AI. Damien Ernst, Professor at the University of Liège, believes that this research could “dramatically accelerate the development of fusion reactors and, ultimately, our ability to fight global change.” (CNBC, Feb 18, 2022). Lastly, this feat is particularly impressive for me as the scientists achieved all of this on tensorflow.
Editor Comments
Andrey: It’s been really exciting to see the types of applied research DeepMind has been pulling off. AlphaFold was a great advance, and DeepMind has since collaborated with mathematicians, weather forecasters, and other experts from other areas than AI to solve hard problems. There is not much that’s interesting from an algorithmic perspective about this work, but the unique cross-disciplinary aspect of it is very exciting, and I hope we shall see this becoming a trend within academia as well.
Daniel: I mostly just want to echo what Andrey said above. Especially for areas like Reinforcement Learning, we’ve seen plenty of fascinating algorithmic advances arising from its use in gameplay. I’m especially excited to see a real-world application in an area like nuclear fusion. There are many truly difficult problems left whose solutions will yield great benefit, and I hope that AI research in academia and industry continues to take steps towards solving them.
New from the Gradient
One Voice Detector to Rule Them All

How Aristotle is Fixing Deep Learning’s Flaws

Reflections on Foundation Models (audio)

Other Things That Caught Our Eyes
News
Stanford University use AI computing to cut DNA sequencing down to five hours “A Stanford University-led research team has set a new Guinness World Record for the fastest DNA sequencing technique using AI computing to accelerate workflow speed.”
The US Copyright Office says an AI can’t copyright its art “The US Copyright Office has rejected a request to let an AI copyright a work of art. Last week, a three-person board reviewed a 2019 ruling against Steven Thaler, who tried to copyright a picture on behalf of an algorithm he dubbed Creativity Machine.”
China Is About to Regulate AI—and the World Is Watching “Wen Li, a Shanghai marketer in the hospitality industry, first suspected that an algorithm was messing with her when she and a friend used the same ride-hailing app one evening. Wen’s friend, who less frequently ordered rides in luxury cars, saw a lower price for the same ride.”
Meta’s new ‘system cards’ make Instagram’s AI algorithm a little less mysterious “On Wednesday, Facebook and Instagram’s parent company, Meta, announced during a virtual event that it was applying artificial intelligence capabilities to power a range of tasks, such as universal translation and a new generation of AI assistants, across its future metaverse platform and existing”
Law Firms Turn to AI to Vet Recruits, Despite Bias Concerns “New York’s Cadwalader firm passed over a law student vying for a summer job until an artificial intelligence algorithm flagged her as a good match.”
The Pentagon is working on an algorithm to detect Covid early “Preliminary results from an experiment using fitness trackers show promise. What if a fitness tracker could predict that the wearer was Covid-positive hours or even days before they start noticing symptoms?”
Papers
Vision Models Are More Robust and Fair When Pretrained on Uncurated Images Without Supervision Discriminative self-supervised learning allows training models on any random group of internet images, and possibly recover salient information that helps differentiate between the images. Applied to ImageNet, this leads to object centric features that perform on par with supervised features on most object-centric downstream tasks. In this work, we question if using this ability, we can learn any salient and more representative information present in diverse unbounded set of images from across the globe. To do so, we train models on billions of random images without any data pre-processing or prior assumptions about what we want the model to learn. We scale our model size to dense 10 billion parameters to avoid underfitting on a large data size. We extensively study and validate our model performance on over 50 benchmarks including fairness, robustness to distribution shift, geographical diversity, fine grained recognition, image copy detection and many image classification datasets. The resulting model, not only captures well semantic information, it also captures information about artistic style and learns salient information such as geolocations and multilingual word embeddings based on visual content only. More importantly, we discover that such model is more robust, more fair, less harmful and less biased than supervised models or models trained on object centric datasets such as ImageNet.
Choices, Risks, and Reward Reports: Charting Public Policy for Reinforcement Learning Systems In the long term, reinforcement learning (RL) is considered by many AI theorists to be the most promising path to artificial general intelligence. This places RL practitioners in a position to design systems that have never existed before and lack prior documentation in law and policy. Public agencies could intervene on complex dynamics that were previously too opaque to deliberate about, and long-held policy ambitions would finally be made tractable. In this whitepaper we illustrate this potential and how it might be technically enacted in the domains of energy infrastructure, social media recommender systems, and transportation. Alongside these unprecedented interventions come new forms of risk that exacerbate the harms already generated by standard machine learning tools. We correspondingly present a new typology of risks arising from RL design choices, falling under four categories: scoping the horizon, defining rewards, pruning information, and training multiple agents. Rather than allowing RL systems to unilaterally reshape human domains, policymakers need new mechanisms for the rule of reason, foreseeability, and interoperability that match the risks these systems pose. We argue that criteria for these choices may be drawn from emerging subfields within antitrust, tort, and administrative law. It will then be possible for courts, federal and state agencies, and non-governmental organizations to play more active roles in RL specification and evaluation. Building on the "model cards" and "datasheets" frameworks proposed by Mitchell et al. and Gebru et al., we argue the need for Reward Reports for AI systems. Reward Reports are living documents for proposed RL deployments that demarcate design choices.
Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework This paper presents a large-scale Chinese cross-modal dataset for benchmarking different multi-modal pre-training methods to facilitate the Vision-Language Pre-training (VLP) research and community development. Recent dual-stream VLP models like CLIP, ALIGN and FILIP have shown remarkable performance on various downstream tasks as well as their remarkable zero-shot ability in the open domain tasks. However, their success heavily relies on the scale of pre-trained datasets. Though there have been both small-scale vision-language English datasets like Flickr30k, CC12M as well as large-scale LAION-400M, the current community lacks large-scale Vision-Language benchmarks in Chinese, hindering the development of broader multilingual applications. On the other hand, there is very rare publicly available large-scale Chinese cross-modal pre-training dataset that has been released, making it hard to use pre-trained models as services for downstream tasks. In this work, we release a Large-Scale Chinese Cross-modal dataset named Wukong, containing 100 million Chinese image-text pairs from the web. Furthermore, we release a group of big models pre-trained with advanced image encoders (ResNet/ViT/SwinT) and different pre-training methods (CLIP/FILIP/LiT). We provide extensive experiments, a deep benchmarking of different downstream tasks, and some exciting findings. Experiments show that Wukong can serve as a promising Chinese pre-training dataset and benchmark for different cross-modal learning methods, which gives superior performance on various downstream tasks such as zero-shot image classification and image-text retrieval benchmarks. More information can refer to this https URL.
Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework In this work, we pursue a unified paradigm for multimodal pretraining to break the scaffolds of complex task/modality-specific customization. We propose OFA, a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image generation, visual grounding, image captioning, image classification, text generation, etc.) to a simple sequence-to-sequence learning framework based on the encoder-decoder architecture. OFA performs pretraining and finetuning with task instructions and introduces no extra task-specific layers for finetuning. Experimental results show that OFA achieves new state-of-the-arts on a series of multimodal tasks, including image captioning (COCO test CIDEr: 149.6), text-to-image generation (COCO test FID: 10.5), VQA (test-std acc.: 80.02), SNLI-VE (test acc.: 90.20), and referring expression comprehension (RefCOCO / RefCOCO+ / RefCOCOg test acc.: 92.93 / 90.10 / 85.20). Through extensive analyses, we demonstrate that OFA reaches comparable performance with uni-modal pretrained models (e.g., BERT, MAE, MoCo v3, SimCLR v2, etc.) in uni-modal tasks, including NLU, NLG, and image classification, and it effectively transfers to unseen tasks and domains. Code shall be released soon at http://github.com/OFA-Sys/OFA
Tweets

Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at gradientpub@gmail.com and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! If you enjoyed this piece, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!