

Gradient Update #13: FB Shuts Down Facial Recognition, MuZero upgraded to EfficientZero
In which we discuss Facebook's Plans to Shut Down Facial Recognition System and the paper Mastering Atari Games with Limited Data

Welcome to the 13th update from The Gradient!
News Highlight: Facebook, Citing Societal Concerns, Plans to Shut Down Facial Recognition System

Summary
This month, Facebook plans to shut down its facial recognition system. In doing so, it will delete the face scan data of over a billion users and put an end to the site’s venerable automated tagging feature. The decision follows hot on the heels of those from other tech giants like Microsoft, Amazon, IBM, which put moratoriums on police use of their facial recognition systems. Like the others, Facebook’s shuttering of this feature will not eliminate the DeepFace algorithm (the backbone of the system) or preclude work on facial recognition in the future.
Background
If you were an early Facebook user, you might remember noticing an interesting change when you uploaded or looked at photos: the UI would automatically identify people in those photos and suggest you “tag” them, which then linked the photo to their profiles. In addition to this feature, Facebook now has one of the largest digital photo databases in the world.
Facial recognition has since become much more accurate, and has many uses beyond tagging your friends in photos. Many of its potential misuses by governments, law enforcement, and companies have brought it under intense scrutiny. And these concerns aren’t just theoretical: Clearview AI scraped billions of photos from social media without users’ consent to provide law enforcement with a facial recognition system, and authorities in China have used facial recognition to track and control the Uighur population in Xinjiang. The move to mandate the use of facial recognition technologies picked up pace last year after the murder of the African-American George Floyd. Microsoft, Amazon, IBM, and other big tech companies put moratoriums on selling their facial recognition tech to police forces until deeper and more exhaustive legislation around the technology could be formulated.
Why does it matter?
While Facebook only used its facial recognition capabilities on its own site, the decision makes sense for the company. Their use of facial recognition had become a regulatory and privacy headache, stoking pushback on the company’s data gathering and use. The last few years have seen an incredible amount of discussion on and criticism of facial recognition. Digital privacy advocates and people concerned about technology ethics have pushed hard for restrictions on facial recognition systems, but there exist no federal regulations for facial recognition in the United States. For these advocates, any step in the direction of curtailing facial recognition use might be seen as a positive, and the Facebook shutdown is certainly big news on that front.
Editor Comments
Daniel: It’s hard to dismiss this news—Facebook’s photo tagging system is one of the most well-known applications of facial recognition in the world today. Facebook is also responsible for a number of advances in visual recognition technologies (R-CNN, RetinaNet). Facebook’s decision to allow opt-outs is a clear signal that major players are responding to public criticism of the technology. That this decision doesn’t preclude further facial recognition research is noteworthy, and I’d be careful to avoid expecting that significant regulation will follow in its wake. The company’s foray into the metaverse also signals that future projects may involve collecting biometric information. That being said, I hope this contributes to a trend of these technologies being subjected to more scrutiny so that if regulation does follow, it has been given due consideration.
Andrey: This is a big deal, and a complete surprise. With Amazon, Microsoft and IBM limiting their facial recognition offerings over the past several years as well, there is hope that this technology can progress more slowly until regulation on the topic can be passed.
Paper Highlight: Mastering Atari Games with Limited Data
Summary
While RL algorithms have been able to attain superhuman performance on Atari games for some time, thus these techniques have still largely been sample inefficient -- the RL agent needed to play the games far more than humans would to get good at them. Model-based approaches have shown promise for improving sample efficiency, but have not at the same time achieved superhuman results. The researchers of this paper build on the model-based MuZero algorithm and introduce a new variant they call EfficientZero. They highlight 3 main challenges that they address with EfficientZero:
Lack of supervision on the environment model - unlike computer vision tasks such as classification or recognition, in RL the representations of images are trained directly from rewards. This is a far less informative signal, since many states may not have associated rewards and the reward itself may not be easy to relate to elements in the image.
Hardness to deal with aleatoric uncertainty - model-based methods require the agent to predict what states it will move to and what rewards it will get after one or more actions. Predicting the future states multiple time steps in the future is hard due to games having uncertainty encoded in their rules, meaning that one action could lead to multiple future states (in other words, there is aleatoric uncertainty about the future). Without being able to predict future states and rewards accurately, it is not possible for the agent to perform well.
Off-policy issues of multi-step value - RL has a core problem, which is that the algorithm is simultaneously having the agent collect data from interaction and modifying the agent to perform better. To improve the model of how good a state is, MuZero recalls the rewards it got from that state multiple steps into the future and adds that to an estimate of the rewards it would have gotten after those steps (ie, calculating the multi-step value). However, that sequence of actions was executed by an older version of the model (ie, they are off-policy), meaning that the remembered rewards are no longer what the agent would get, and the prediction of future rewards after that may also be innacurate.
To address these 3 challenges, the paper introduces the 3 main modifications that differentiates EfficientZero from MuZero:
Use self-supervised learning to learn a temporally consistent environment - instead of learning to interpret the images using only rewards, the researchers use the method proposed in SimSiam to learn state representations in a self-supervised manner (similar to some prior works such as CURL and SPR). Self-supervision allows the model to learn image representations without additional labels. Further, self-supervision is implemented such that successive images from the game will have similar representations, which may not be the case when learning only from rewards.
Learn the value prefix in an end-to-end manner - instead of predicting successive states and rewards with the model, EfficientZero instead trains a separate LSTM that uses the predicted successive states to predict the eventual value of the summed reward. The LSTM alleviates the issue of uncertainty over future state by being able to see a mistake early on and know that it will result in bad rewards in the future, instead of relying on accurate state predictions later on to do so.
Use the learned model to correct off-policy value targets - instead of recalling the same number of steps as MuZero would, EfficientZero adds up fewer rewards from past experience and makes up for off-policy inaccuracy for values beyond past experience by doing ‘imagined rollouts’ with the current policy.
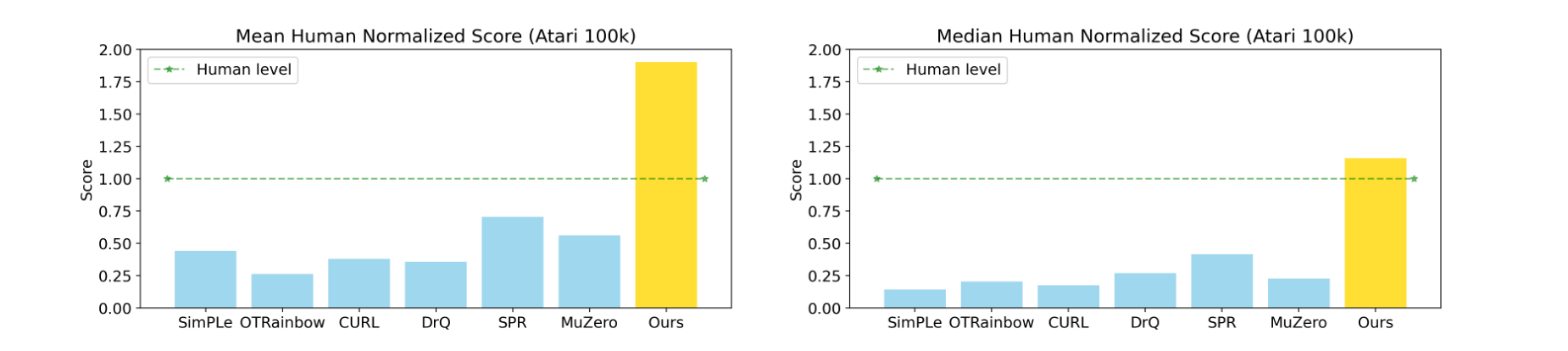
With these components combined, EfficientZero “achieves 190.4% mean human performance and 116.0% median performance on the Atari 100k benchmark with only two hours of real-time game experience and outperform the state SAC in some tasks on the DMControl 100k benchmark.”
Background

Use of a model - the notion of using a model of the environment was key to all of the predecessors of EfficientZero (AlphaGo, AlphaGo Zero, AlphaZero, and MuZero), and was a large part of the reason these algorithms proved to be powerful. Up until MuZero, the model of the environment (ie, the rules of the game) was provided to the agent. MuZero removed this requirement, but added the challenge of learning the model to the overall learning problem. The addition of self-supervised representation learning improves the ability of the algorithm to learn the model well.
Self Supervised Learning for Computer VIsion - self-supervision has been a known idea for decades, but until recently supervised learning was much better for learning useful image representations. However, that has been changing over the last several years techniques such as SimCLR, BYOL, and SWAV have been introduced and shown to work almost as well as supervised learning.
Why does it matter?
As the paper states, “AlphaZero needs to play 21 million games at training time. On the contrary, a professional human player can only play around 5 games per day, meaning it would take a human player 11,500 years to achieve the same amount of experience.” While sample efficiency is less important for problems that can be accurately captured with a simulator, such as Chess and other games, it matters greatly for other problems in which this is not the case.
In particular, robotics is an area where learning only from simulation has yet to be sufficient to fully transfer to the real world, and it is often required for the RL agent to learn by interacting with the environment with a real physical robot. This means that sample efficiency is crucial, as it is not possible to get millions of interactions with the environment in a short amount of time. For example, in Google’s QT-Opt paper the authors presented an approach to learn robotic grasping with RL from scratch. To do so, they used seven robots to collect 580k real-world grasp attempts, which took a total of about 800 robot hours and 4 months of experiments.
Editor Comments
Andrey: This is a pretty-exciting development. Sample efficiency is crucial for reinforcement learning to be useful for real-world problems, and the ideas and results presented in this paper present a significant advance towards that goal. The incorporation of self-supervised learning for image understanding in RL has been demonstrated a few times but has not been sufficient to enable both superhuman performance and sample efficiency on its own. The two other ideas presented in this work work well in concert with self-supervision and impressively improve upon prior efforts. I’m excited to see further efforts like this!
New from the Gradient

Explain Yourself - A Primer on ML Interpretability & Explainability

Alex Tamkin on Self-Supervised Learning and Large Language Models
Other Things That Caught Our Eyes
News
As the Arctic Warms, AI Forecasts Scope Out Shifting Sea Ice - "Global warming is making it harder to predict the movement and location of the ice cover, crucial information for fishing and global shipping."
Australia Ordered Clearview AI to Destroy its Database, As It's Violating Privacy Laws - "After a couple of investigations, the Australian Information Commissioner’s Office declared that Clearview AI had violated the Australian privacy laws. Clearview AI is a US company aiding police personnel to identify people by scanning their faces in public or searching them in their repository."
Zillow Quits Home-Flipping Business, Cites Inability to Forecast Prices - "Termination of ‘iBuying’ comes after company said it was halting new home purchases for rest of 2021"
Waymo is bringing its autonomous vehicles to New York City for (manually driven) mapping - "The latest autonomous vehicle company to tackle the mean streets of New York City will be Waymo. The Google spinoff is bringing a handful of cars to the Big Apple, where they will start mapping the city streets using manually driven vehicles with two people riding inside."
New Azure OpenAI Service combines access to powerful GPT-3 language models with Azure’s enterprise capabilities - "Since OpenAI, an AI research and deployment company, introduced its groundbreaking GPT-3 natural language model platform last year, users have discovered countless things that these AI models can do with their powerful and comprehensive understanding of language."
Papers
StyleCLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis - “ Generating images that fit a given text description using machine learning has improved greatly with the release of technologies such as the CLIP image-text encoder model; however, current methods lack artistic control of the style of image to be generated. We introduce StyleCLIPDraw which adds a style loss to the CLIPDraw text-to-drawing synthesis model to allow artistic control of the synthesized drawings in addition to control of the content via text. Whereas performing decoupled style transfer on a generated image only affects the texture, our proposed coupled approach is able to capture a style in both texture and shape, suggesting that the style of the drawing is coupled with the drawing process itself.”
Can I use this publicly available dataset to build commercial AI software? Most likely not - “Publicly available datasets are one of the key drivers for commercial AI software. The use of publicly available datasets (particularly for commercial purposes) is governed by dataset licenses … However, unlike standardized Open Source Software (OSS) licenses, existing dataset licenses are defined in an ad-hoc manner and do not clearly outline the rights and obligations associated with their usage. … We conduct trials of our approach on two product groups within Huawei on 6 commonly used publicly available datasets. Our results show that there are risks of license violations on 5 of these 6 studied datasets if they were used for commercial purposes. Consequently, we provide recommendations for AI engineers on how to better assess publicly available datasets for license compliance violations.”
Are Transformers More Robust Than CNNs? - “Transformer emerges as a powerful tool for visual recognition. In addition to demonstrating competitive performance on a broad range of visual benchmarks, recent works also argue that Transformers are much more robust than Convolutions Neural Networks (CNNs). Nonetheless, surprisingly, we find these conclusions are drawn from unfair experimental settings, where Transformers and CNNs are compared at different scales and are applied with distinct training frameworks. In this paper, we aim to provide the first fair & in-depth comparisons between Transformers and CNNs, focusing on robustness evaluations. … We hope this work can help the community better understand and benchmark the robustness of Transformers and CNNs. ”
Masked Autoencoders Are Scalable Vision Learners - “This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels … Our scalable approach allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream tasks outperforms supervised pre-training and shows promising scaling behavior.”
NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework - “Pretrained language models have become the standard approach for many NLP tasks due to strong performance, but they are very expensive to train. We propose a simple and efficient learning framework, TLM, that does not rely on large-scale pretraining. Given some labeled task data and a large general corpus, TLM uses task data as queries to retrieve a tiny subset of the general corpus and jointly optimizes the task objective and the language modeling objective from scratch. On eight classification datasets in four domains, TLM achieves results better than or similar to pretrained language models (e.g., RoBERTa-Large) while reducing the training FLOPs by two orders of magnitude.”
Tweets




Closing Thoughts
Have something to say about this edition’s topics? Shoot us an email at gradientpub@gmail.com and we will consider sharing the most interesting thoughts from readers to share in the next newsletter! If you enjoyed this piece, consider donating to The Gradient via a Substack subscription, which helps keep this grad-student / volunteer-run project afloat. Thanks for reading the latest Update from the Gradient!